- The paper introduces a simplified routing mechanism that directs each token to a single expert, significantly reducing computational and communication overhead.
- The paper demonstrates up to 7x pre-training speedups and improved training stability by leveraging bfloat16 precision in sparse models.
- The paper confirms that multilingual and fine-tuning results are maintained across diverse NLP benchmarks and 101 languages, showcasing scalability.
Introduction
The paper entitled "Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity" (2101.03961) addresses fundamental limitations in the scalability of Mixture of Experts (MoE) models by introducing the Switch Transformer. While MoE models have achieved significant successes, their adoption is constrained by complexity, high communication costs, and training instability. The Switch Transformer simplifies the MoE routing algorithm, reduces computational and communication costs, and achieves training stability. This paper demonstrates the ability to train large sparse models with reduced precision using bfloat16 formats, leveraging the benefits of sparsely-activated expert models without incurring additional computational costs relative to densely-activated alternatives.
The Switch Transformer extends upon the Transformer architecture by incorporating sparsely-activated layers, known as Switch layers, which activate only a subset of weights for each incoming example. This design philosophy prioritizes a large parameter count while maintaining a constant computational cost, effectively scaling neural LLMs without additional computational burden.
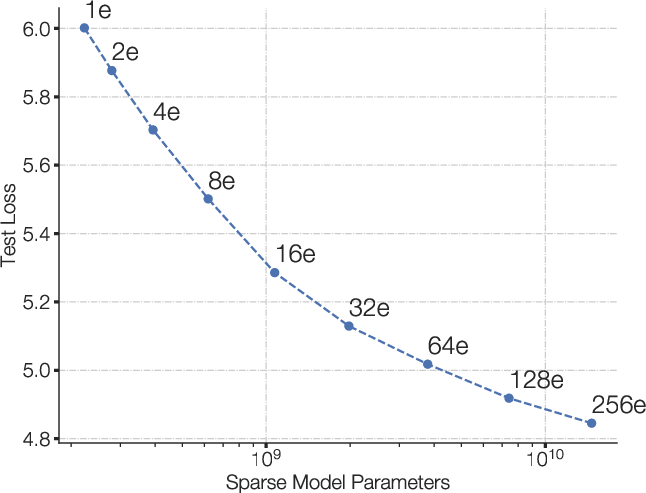
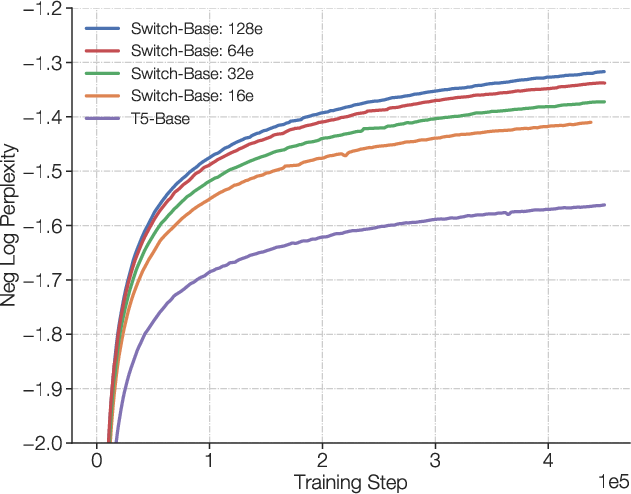
Figure 1: Scaling and sample efficiency of Switch Transformers. Left Plot: Scaling properties for increasingly sparse (more experts) Switch Transformers. Right Plot: Negative log perplexity comparing Switch Transformers to T5 models using the same compute budget.
Simplified Sparse Routing
The Switch Transformer implements a simplified routing mechanism, contrasting with previous top-k expert selection strategies that compute non-trivial gradients across multiple experts. The Switch routing strategy uses a simplified mechanism by assigning each token to a single expert, thereby reducing computational overhead and enhancing training stability.
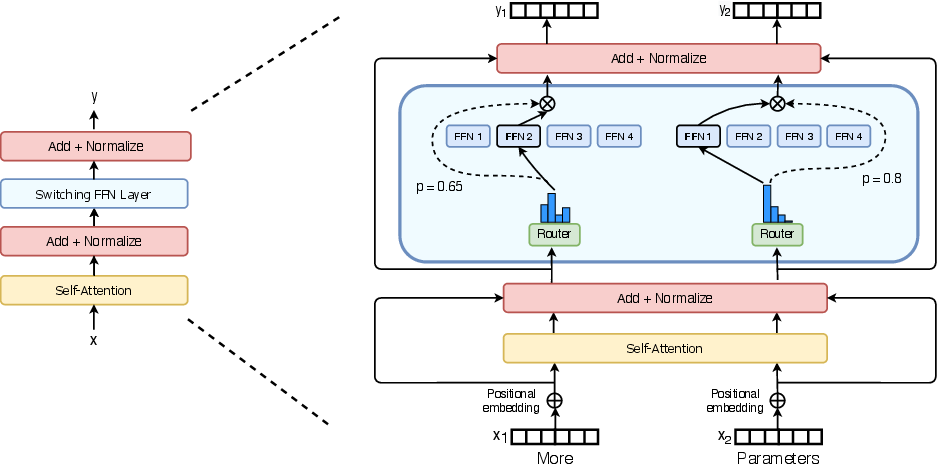
Figure 2: Illustration of a Switch Transformer encoder block. We replace the dense feed forward network layer present in the Transformer with a sparse Switch FFN layer. The layer operates independently on the tokens in the sequence.
Efficient Sparse Routing Implementation
Utilizing Mesh-Tensorflow for efficient sparse routing, the Switch Transformer ensures stability in routing decisions through dynamically set expert capacities and an auxiliary load balancing loss. The implementation maintains computational efficiency, even when faced with uneven token dispatch across multiple experts.
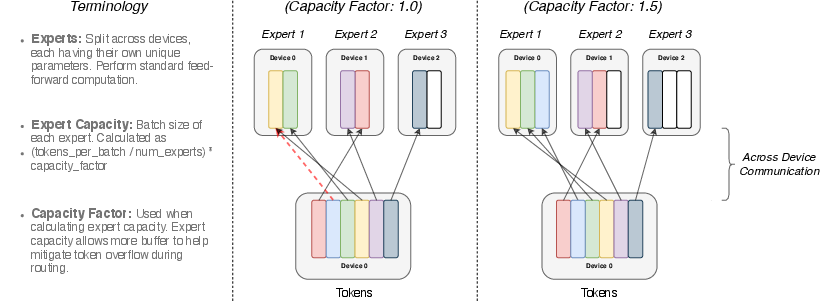
Figure 3: Illustration of token routing dynamics. Each expert processes a fixed batch-size of tokens modulated by the capacity factor.
Experimental Results
The Switch Transformer has demonstrated significant improvements in training speed and efficiency, with reported speedups of up to 7x in pre-training compared to dense models such as T5-XXL. Key improvements are observed in multilingual contexts, where Switch Transformers achieve consistent gains across all 101 languages, recording speedups of 4x or greater for 91% of languages.
Figure 4: Scaling properties of the Switch Transformer. Despite all models using an equal computational budget, we observe consistent improvements scaling the number of experts.
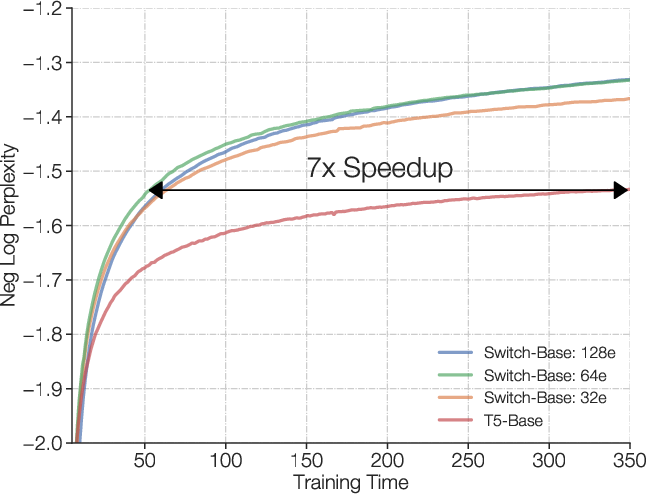
Figure 5: Speed advantage of Switch Transformer. For a fixed amount of computation and training time, Switch Transformers significantly outperform the dense Transformer baseline.
Fine-Tuning and Distillation
The Switch Transformer exhibits substantial improvements during fine-tuning across diverse NLP tasks, including GLUE, SuperGLUE, SQuAD, and TriviaQA. The architecture supports effective model distillation, compressing large sparse models into dense variants while preserving a significant fraction of the quality improvements.
Multilingual and Scaling Design
In multilingual training, Switch Transformers demonstrate effective scaling properties, displaying mean step speed-ups against mT5-Base. These models incorporate a blend of data, model, and expert-parallelism, achieving parameter scales up to 1.6 trillion, showcasing enhanced sample efficiency and reduced training duration compared to large-scale dense models.
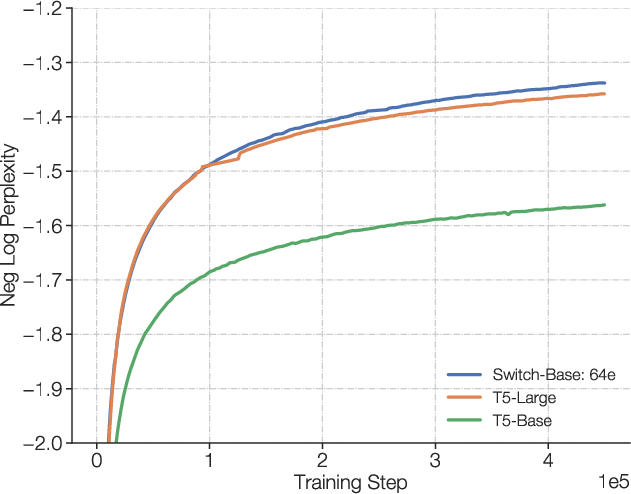
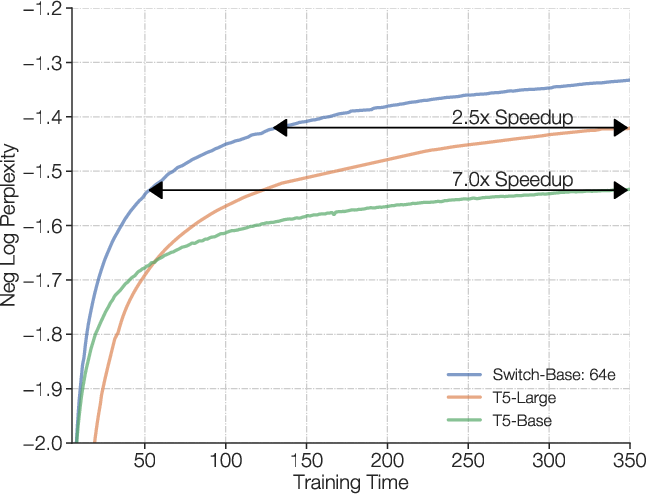
Figure 6: Multilingual pre-training on 101 languages. Improvements of Switch T5 Base model over dense baseline when multi-task training on 101 languages.
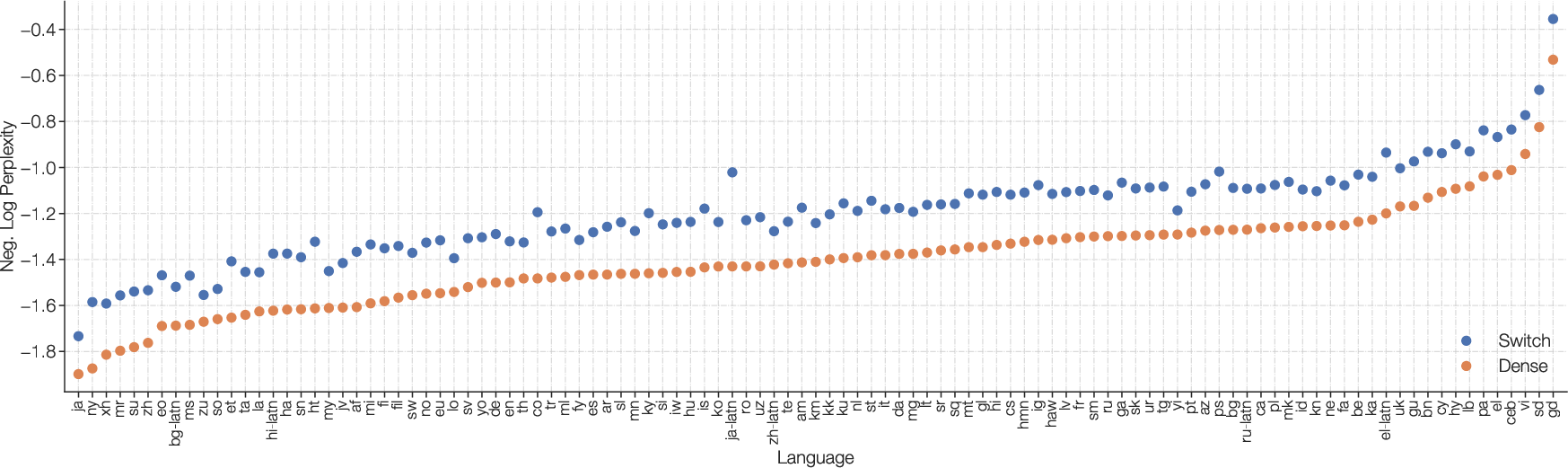
Figure 7: Multilingual pre-training on 101 languages. We histogram for each language, the step speedup of Switch Transformers over the FLOP matched T5 dense baseline to reach the same quality.
Conclusion
The Switch Transformer establishes a paradigm shift in the design and scalability of large-scale LLMs through its focus on sparse activation and computational efficiency. Its adoption may catalyze future advancements in sparsely-activated architectures, embracing both multilingual contexts and expansive parameter scales.

