- The paper demonstrates that effective data transfer follows a power-law relationship in low-data regimes, reducing the need for extensive training data.
- The methodology compares fine-tuned pre-trained models against models trained from scratch, showing superior performance and compute efficiency.
- Empirical results indicate that pre-training on large, diverse datasets dramatically optimizes resource use in subsequent task-specific fine-tuning.
Scaling Laws for Transfer
The paper "Scaling Laws for Transfer" examines the empirical scaling laws associated with transfer learning in unsupervised settings, particularly focusing on the fine-tuning of large transformer models pre-trained on a language distribution and subsequently adapted for code generation tasks. This work investigates the transfer of effective data from pre-training to fine-tuning, and the implications of such transfer on model performance in varying data conditions.
Introduction
The paper outlines a detailed examination of how neural networks, especially large transformer models, benefit from transfer learning—a process where models pre-trained on one type of data distribution can be effectively adapted to another through fine-tuning. The central premise lies in identifying how pre-trained models can achieve performance levels comparable to training from scratch, but with significantly less data and computational resources.
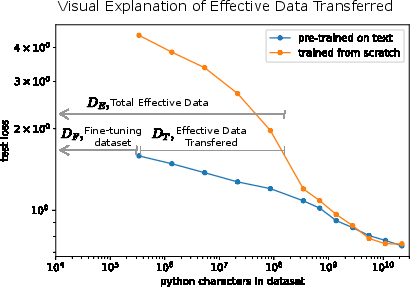
Figure 1: Performance comparison of a 40M parameter transformer model trained on python, pre-trained on text, and fine-tuned on python, illustrating effective data transfer.
A critical observation is that models trained from scratch on limited datasets become data-constrained, exhibiting no performance improvement with increased model capacity. Conversely, models pre-trained on large language datasets show reduced performance gain slopes when fine-tuned, indicating enhanced data efficiency and transfer effectiveness.
Key Results
Empirical results demonstrate that the effective data transferred from pre-training is described by a power-law relationship in low-data regimes. This law quantifies the additional data needed by a model trained from scratch to attain equivalent performance as a pre-trained model.
DT=k⋅(DF)α⋅(N)β
Additionally, experiments indicate a unique scaling behavior with different pre-training distributions such as text versus a mixture of text and non-python code, concluding that the architectural generality significantly influences transfer effectiveness.
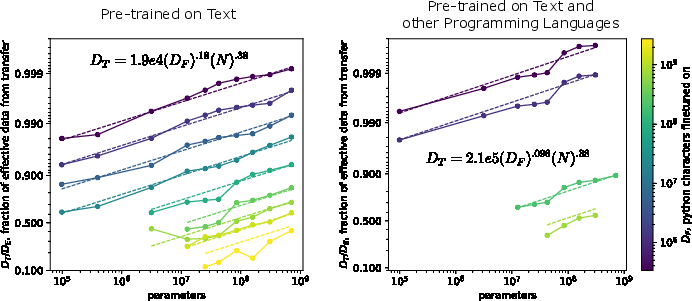
Figure 2: Transfer fits in low-data regimes depicting power-law relationships over several orders of magnitude in model and dataset sizes.
Scaling Laws Analysis
The exploration extends to the scalability of fine-tuning versus training from scratch within constrained data regimes, highlighting that pre-trained models consistently derive greater performance than their from-scratch counterparts.
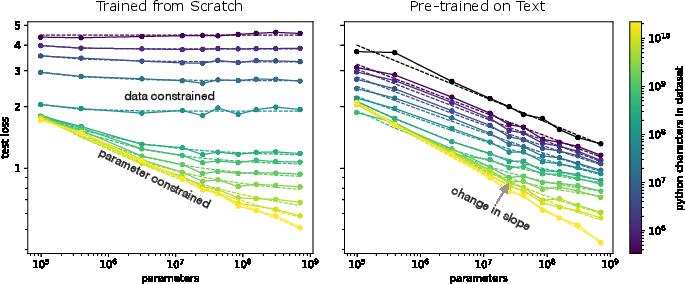
Figure 3: Scaling laws comparison showcasing pre-trained models outperforming data-constrained from-scratch models demonstrating limited benefit from increased parameters.
Furthermore, compute efficiency analysis reveals that fine-tuning requires less computational effort for a given performance level, reinforcing the practical advantages of transfer learning.
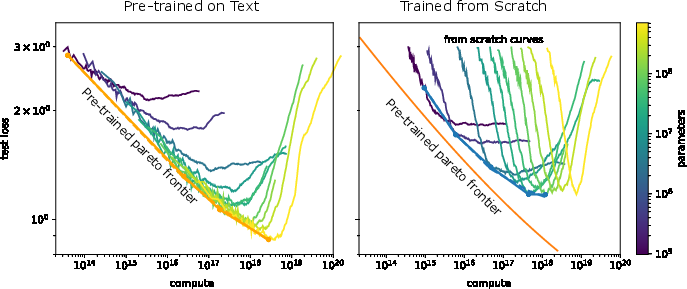
Figure 4: Comparative performance showcasing compute efficiency in low-data regimes for fine-tuning models versus training from scratch.
Practical Implications
The paper emphasizes the practical impact of transfer learning, suggesting that in low-data regimes, fine-tuned models effectively multiply the available dataset size, thereby reducing the need for extensive training data and computational resources. Additionally, it provides a methodological approach to estimate transfer benefits and make informed decisions about data collection and model scaling strategies.
Although the theoretical generalization across diverse data distributions remains unclaimed, the focus on data-efficient training remains crucial for domains lacking abundant datasets.
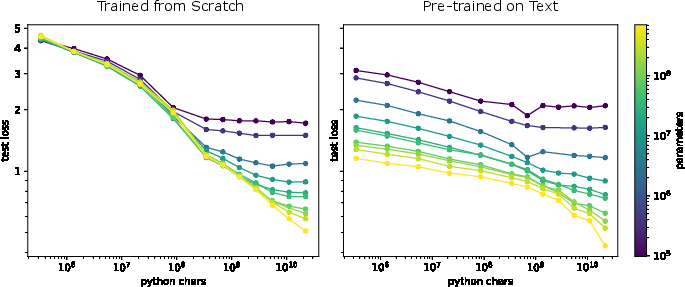
Figure 5: Data scaling laws indicating improved performance with larger datasets for small models trained from scratch versus fine-tuned models in high data regimes.
Conclusion
The findings of "Scaling Laws for Transfer" underscore the pivotal role of pre-training in enhancing neural network efficiency across diverse applications. By providing robust scaling laws for transfer, the paper informs strategic design choices in AI, advocating for the deployment of pre-trained models to maximize output with minimal direct data exposure. These insights carry profound implications for the evolution of AI systems, facilitating innovation in sparse data environments.
Ultimately, this work contributes substantially to the dialogue on optimizing data, compute, and model parameters, marking an advance in understanding neural network behavior under data-transfer conditions.