- The paper introduces two RL algorithms, Heavy-UCRL2 and Heavy-Q-Learning, that extend traditional methods to handle heavy-tailed reward distributions with robust mean estimators.
- By truncating extreme rewards and adding exploration bonuses, the methods achieve near-optimal regret bounds in challenging Markov Decision Processes.
- Experimental results on synthetic and deep RL benchmarks demonstrate improved performance over standard algorithms in high-variability, heavy-tailed settings.
No-Regret Reinforcement Learning with Heavy-Tailed Rewards
Reinforcement Learning (RL) algorithms often assume that reward distributions are light-tailed (e.g., Gaussian or bounded). However, many real-world applications involve rewards that follow heavy-tailed distributions, such as financial systems or network routing times. This paper addresses the challenge of designing RL algorithms that efficiently handle heavy-tailed rewards, introducing Heavy-UCRL2 and Heavy-Q-Learning, which achieve near-optimal regret bounds in this setting.
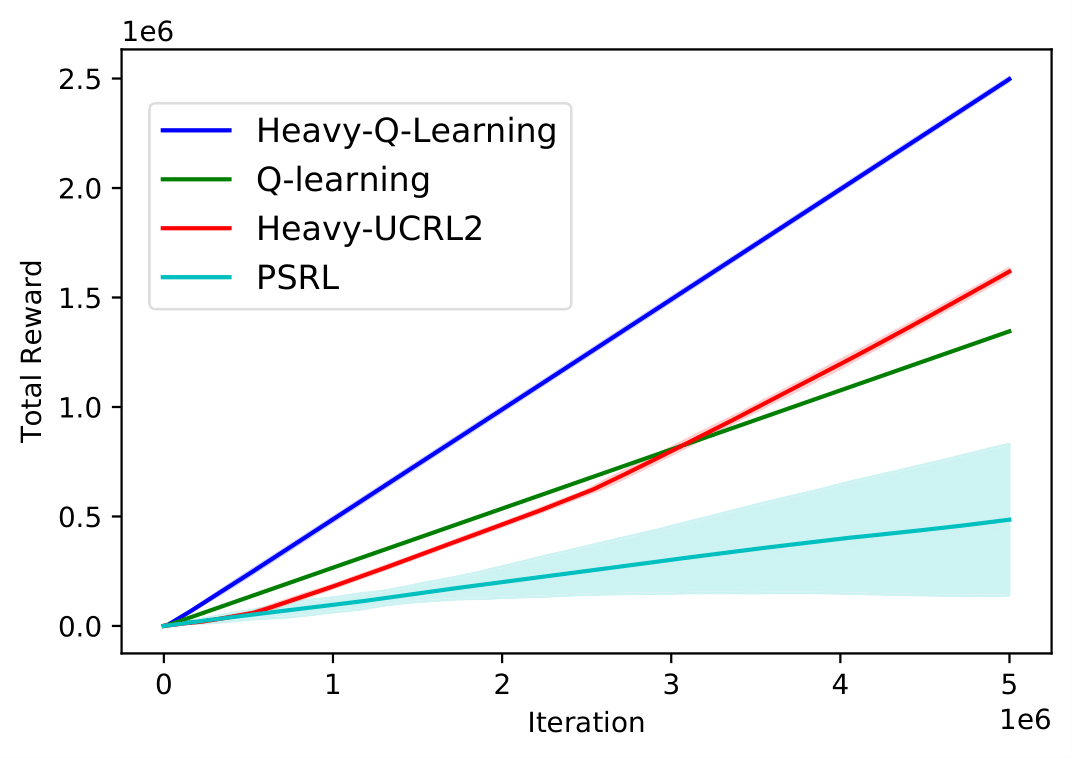
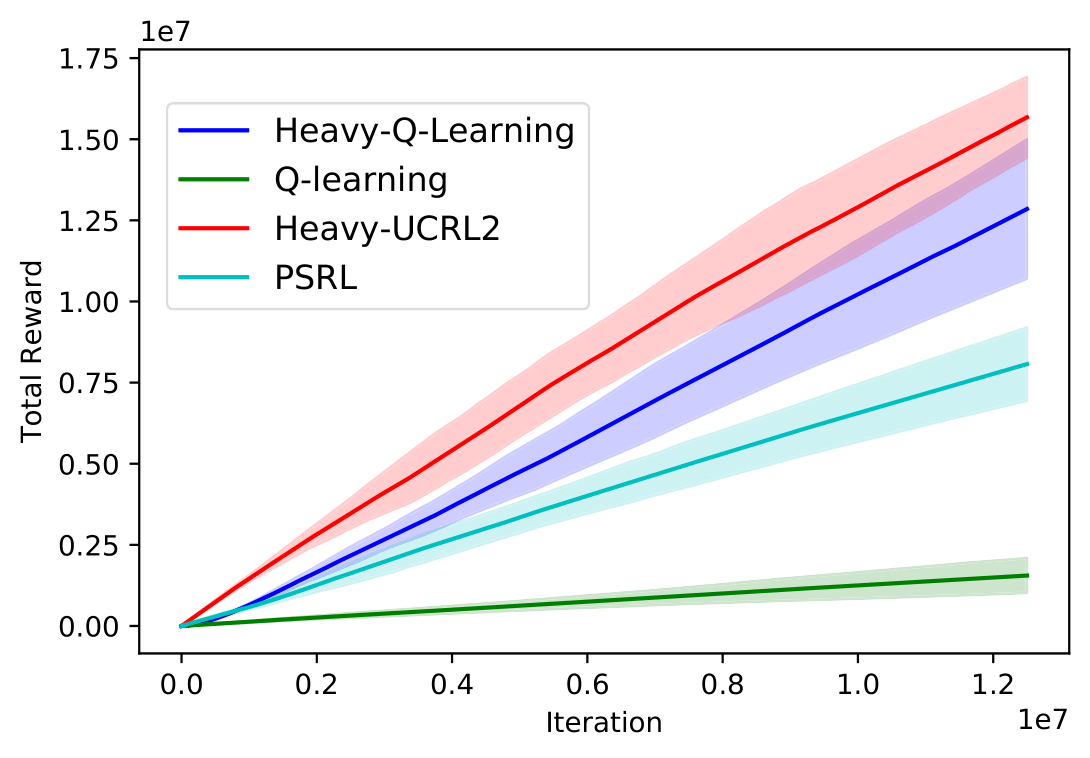
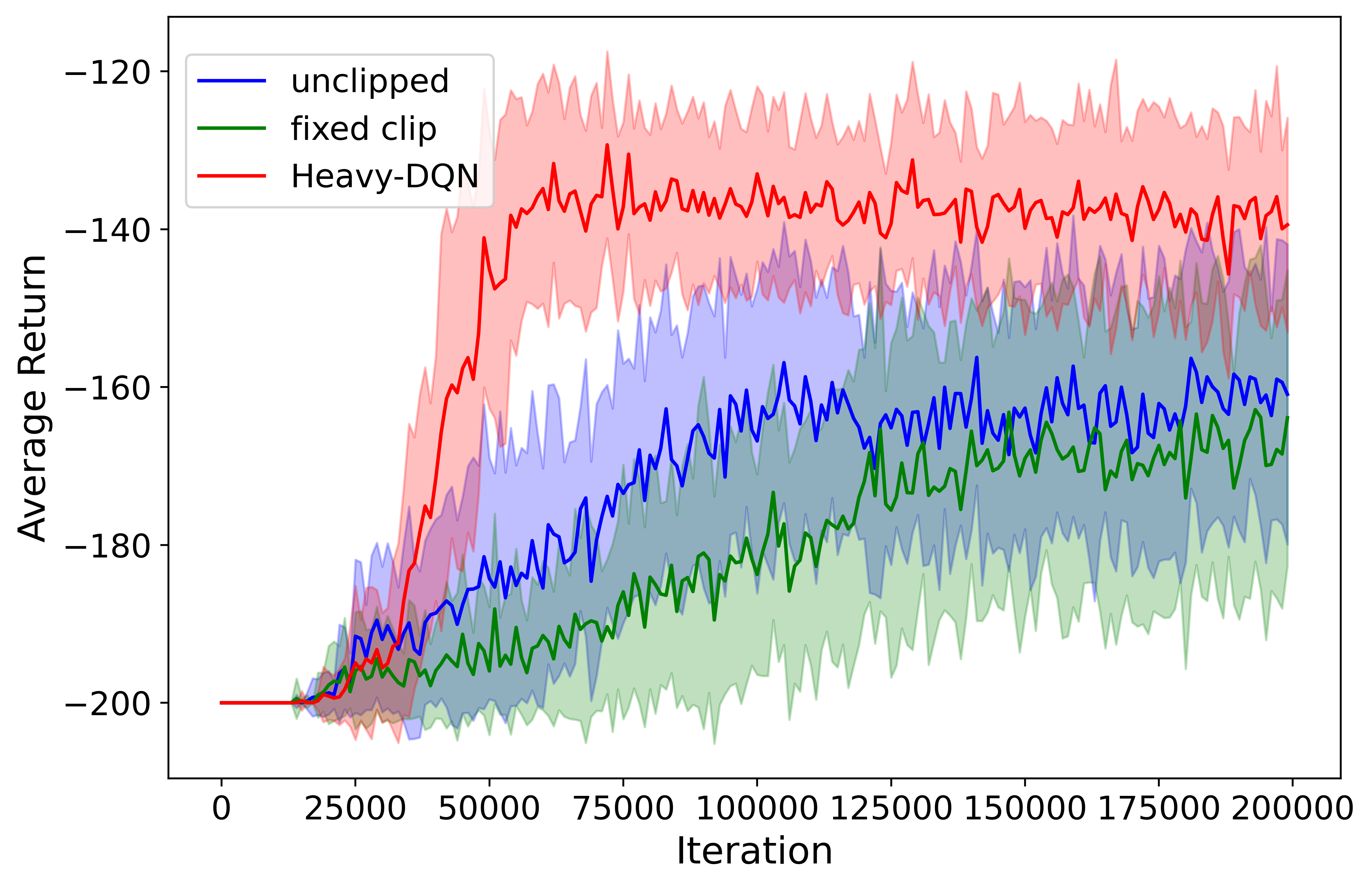
Figure 1: The DoubleChain MDP, illustrating the transition structure for two actions.
Problem Statement
The reinforcement learning problem is set in the context of a Markov Decision Process (MDP) with heavy-tailed reward distributions. Traditionally, RL algorithms focus on learning transition probabilities, but with heavy-tailed rewards, the learning difficulty shifts towards accurately estimating these rewards. The goal is to maximize the undiscounted return or equivalently, minimize regret.
Proposed Algorithms
Heavy-UCRL2
Heavy-UCRL2 is an extension of UCRL2 for heavy-tailed rewards. It uses robust mean estimators like the truncated mean to construct valid confidence intervals for rewards. This ensures that the algorithm explores effectively even when rewards have large variances. The pseudocode for Heavy-UCRL2 follows a similar structure to UCRL2, but with modifications to accommodate robust mean estimation techniques.
Heavy-Q-Learning
Heavy-Q-Learning adapts Q-learning for environments with heavy-tailed rewards. The reward is truncated, and an additional bonus is added to handle the uncertainty introduced by heavy-tailed distributions. The initialization is prone to using optimistic values, which helps in navigating exploration effectively without misleading updates from extreme reward samples.
Heavy-DQN
This approach extends Heavy-Q-Learning into deep RL settings using DQNs, incorporating adaptive reward truncation via count-based exploration methods like SimHash. This adaptive strategy helps stabilize training dynamics in deep reinforcement learning environments impacted by heavy-tailed noise.
Theoretical Results
The paper presents various theoretical guarantees for the proposed algorithms:
- Minimax Regret Bound: Both Heavy-UCRL2 and Heavy-Q-Learning achieve regret bounds of O~((SAT)1), where A is the action space and T is the time horizon, indicating robustness against reward distribution heavy-tailedness.
- Problem-Dependent Regret: Continued analysis shows logarithmic dependence on the number of state-action pairs, emphasizing efficient learning in environments where extreme outcomes are possible.
- Regret Under Changing MDPs: The algorithms maintain performance even when MDP transitions, indicating adaptability to dynamic environments.
Experimental Validation
Extensive experiments demonstrate improved performance of Heavy-UCRL2 and Heavy-Q-Learning across synthetic MDPs like SixArms and DoubleChain (Figure 1), outperforming standard algorithms not designed for heavy-tailed settings. Deep RL experiments validate Heavy-DQN's effectiveness in environments like MountainCar, showcasing robust learning where reward noise follows heavy-tailed distributions.
Conclusion
The introduction of Heavy-UCRL2 and Heavy-Q-Learning represents significant progress in realistically handling environments with heavy-tailed reward distributions. These algorithms effectively apply techniques from robust statistics to RL, underscoring RL's potential in complex real-world applications with extreme variability. The continued exploration of heavy-tailed reward settings holds promise for enhancing RL's applicability in uncertain and dynamic environments.