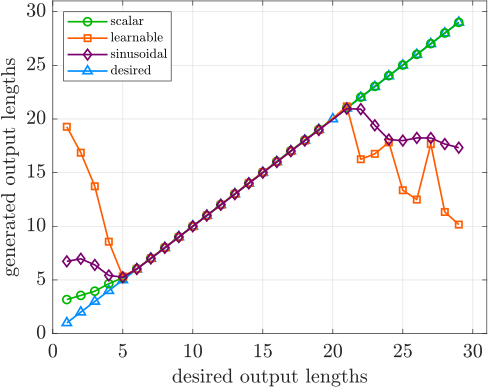
- The paper demonstrates that direct scalar input methods achieve near-perfect extrapolation in controlled text generation tasks, outperforming learnable and sinusoidal embeddings.
- Through experiments on SNLI, QQP, and Yelp datasets, both LSTM and Transformer decoders are assessed using metrics such as MSE and exact-match accuracy to gauge control adherence.
- Findings indicate that direct scalar inputs provide superior generalization in zero-shot conditions, challenging conventional practices in scalar embedding for text generation.
Introduction
This paper presents an in-depth empirical evaluation of extrapolation behavior when controlling neural text generators via scalar-valued conditions, such as target sequence length, output–input edit distance, or sentiment intensity. The primary focus is on the zero-shot regime: models are trained on a narrow interval of scalar conditions and must generalize to control values outside this range at test time. The study rigorously compares various approaches for representing scalar controls—including learnable, sinusoidal, and direct scalar input methods—across multiple text generation settings. The findings identify direct scalar input strategies as the most robust solution for extrapolation, with implications for the design of future controllable generative models.
Scalar Control in Neural Text Generation
Scalar control variables enable conditional generation where outputs possess quantifiable attributes directly specified by the user or upstream system. Common examples include explicit sentence length control or sentiment specification. The study formalizes this as learning conditional generation models (e.g., P(Y∣X,c) for sequence-to-sequence tasks) where c is an integer-valued scalar, and empirically benchmarks three tasks:
- Length-Conditioned Language Modeling: SNLI dataset, controlled output length.
- Edit Control in Paraphrasing: Quora Question Pairs, controlled lexical divergence (Jaccard-based discretized edit).
- Sentiment Control: Yelp reviews, discrete 1–5 sentiment rating as target.
For all tasks, the scalar variable conditions either a vanilla LM or a neural paraphrastic/conditional generator, based on either LSTM or Transformer architectures.
Scalar Embedding Strategies Compared
The research investigates several embedding paradigms for the scalar input:
- Learnable Embeddings: Discrete scalar values are embedded via a trainable lookup table.
- Sinusoidal (Fixed Positional) Embeddings: Scalars encoded with periodic basis functions as in canonical Transformer position encoding.
- Direct Scalar Input: Scalar passed without learned encoding, either as a raw value or repeated as a fixed-length vector concatenated to token embeddings ("scalar_repeat").
A consistent control architecture is used in all cases: the scalar encoding is concatenated to the input token embedding at each decoder step. For length and edit controls, a secondary embedding indicates the current value achieved so far.
(Figure 1)
Figure 1: Depiction of scalar control tasks integrating a control value into the decoder pipeline.
Experimental Protocol
Experiments systematically restrict observed control ranges at train time and evaluate performance on both seen and extrapolation ranges. Perplexity (PPL) quantifies general generation quality; adherence to the control signal is measured by Mean Squared Error (MSE) to the desired scalar, and (where possible) the exact-match accuracy of achieving the targeted value.
For robust assessment:
- Training is always limited to a subset of possible control values (e.g., lengths L≤20 in SNLI), while evaluation proceeds on a wider range (e.g., L≤30 with extrapolation for 20<L≤30).
- Both LSTM and Transformer decoders are included, facilitating architecture-level insights.
Main Empirical Findings
Direct scalar input strategies ("scalar" and "scalar_repeat") consistently outperform complex embedding alternatives for extrapolation, yielding near-exact match in both controlled output range and minimal loss of generation quality:
A notable secondary outcome is that LSTM decoders exhibit superior zero-shot extrapolation of control value, compared to Transformers, especially for the simplest scalar representations. This may relate to sequence modeling inductive biases inherent in recurrent architectures.
Theoretical and Practical Implications
These results directly contradict the common intuition—drawn from positional and feature-embedding traditions—that complex, learned, or periodic embeddings better support extrapolation. Instead, direct scalar input passes maximize generalization outside observed training intervals, likely due to their monotonic, linear nature in the model’s parameter space and suitability for non-ordinal control variables. This has theoretical implications for the design of conditioning interfaces in neural generation: scalar passage should be preferred over learned embeddings for most extrapolation scenarios.
On a practical level, these findings inform researchers developing controllable LMs (for summarization, controllable paraphrase, or NLG systems needing output constraint generalization) to avoid learned scalar embeddings. For zero-shot control settings, optimal outcomes are achieved with direct scalar input concatenation. The evidence provided may inform future design of plug-and-play or parameter-efficient conditional adapters requiring robust scaling beyond the training range.
Outlook and Future Work
The paper’s approach could be systematically extended to subtler forms of control (continuous-valued, multi-dimensional, or stochastic control) as well as across more nuanced text domains. Future directions include theoretical analysis of why direct scalar passage enables such effective extrapolation, as well as integrating learned normalization or calibration mechanisms where raw direct input scaling may interact nontrivially with deeper architectures.
Conclusion
The study offers an authoritative empirical comparison of scalar-conditioned controllable text generation, focusing on zero-shot extrapolation to unseen scalar values. The evidence robustly supports the use of direct scalar value input (without embedding) for generalization, across multiple tasks and architectures. These findings challenge standard practices and should directly shape future work in conditional natural language generation and controllable sequence modeling.
Reference: "An Empirical Study of Extrapolation in Text Generation with Scalar Control" (2104.07910).