- The paper proposes a data-driven, explainable CBR system that uses PSO to optimize local similarity measures for enhanced financial risk detection.
- The system utilizes weighted feature scoring and case-based reasoning to provide transparency and justification, ensuring GDPR compliance.
- Empirical evaluations across multiple datasets demonstrate superior performance versus traditional classifiers in key metrics such as accuracy and ROC AUC.
A Data-driven Explainable Case-based Reasoning Approach for Financial Risk Detection
Introduction
The paper proposes an innovative approach to financial risk detection using an explainable Case-Based Reasoning (CBR) system. CBR is a well-known XAI methodology that imitates human reasoning by solving new problems using experiences from past cases. This study emphasizes the necessity for such explainability in the financial sector due to regulatory requirements like the GDPR, which mandates transparency in automated decision-making processes.
Methodology
Evolutionary CBR System
The proposed system leverages the local-global principle for similarity measures to determine case similarity in a dataset based on attributes. The global similarity Sim(Q,C) between a query case Q and a case C is computed by aggregating local similarities using weighted sums, where weights are derived from feature importance scoring methods. The system employs Particle Swarm Optimization (PSO) to optimize local similarity function parameters, automatically configuring the CBR system without expert intervention.
Explainability Goals
The paper identifies four primary goals of explanation in CBR systems:
- Transparency: Enables users to comprehend how decisions are made through similarity measures.
- Justification: Provides confidence in predictions by estimating posterior probabilities using nearest cases.
- Relevance: Identifies influential features for decision-making, allowing stakeholders to prioritize important factors.
- Learning: Facilitates deeper understanding by using clustering techniques to extract additional insights from the data.
Data-Driven Design
The CBR system's automatic design involves setting parameters such as the number of most similar cases (k) using a KNN algorithm and computing feature weights through various scoring methods like Gini, Mutual Information, and ANOVA. The parameter optimization and evaluation processes are parallelized to expedite computation.
Experimental Setup
The study evaluates the CBR system across five different financial datasets, ranging from credit card fraud to bank churn. It contrasts the results of the designed CBR system with other classifiers, including Logistic Regression, Decision Trees, and Naive Bayes, using performance metrics like accuracy, precision, recall, and ROC AUC. The evaluation leverages the Multiple-Criteria Decision-Making (MCDM) method, specifically the TOPSIS algorithm, to comprehensively rank the models based on performance scores.
Results
Empirical results demonstrate the superiority of the proposed CBR system in predicting financial risk, surpassing traditional machine learning models across several performance metrics. The results highlight the stability and competitive edge of the CBR approach in various datasets, emphasizing the importance of explainability in financial predictions.
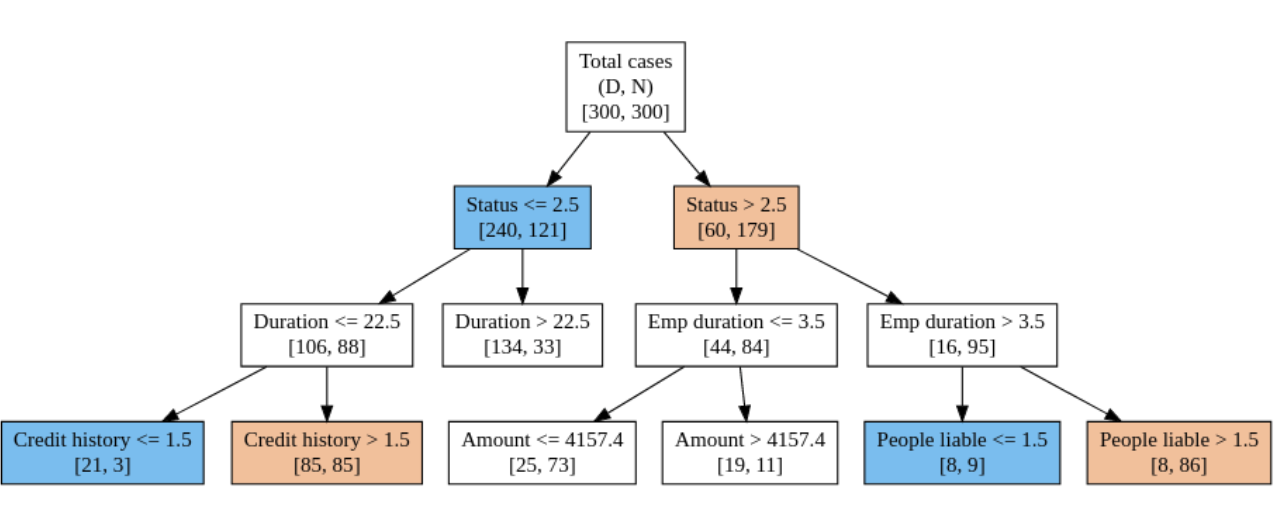
Figure 1: The most likely causes for a particular default based on CID tree scoring. The decision tree is built using the C4.5 algorithm, and the prominent features have been highlighted (node P (blue) and node S (yellow)).
Interpretation and Implications
The paper provides a thorough explanation of prediction results, using specific case studies from the South German credit dataset to illustrate the CBR system's interpretability. It showcases how financial institutions can leverage the system to provide insightful recommendations and improve risk assessment decisions based on similar historical cases.
Additionally, the study discusses how data-driven insights derived from feature relevance and clustering can enhance credit risk assessments. For instance, identifying that financial status and credit duration are significant predictors of risk can guide credit approval processes.
Conclusion
This paper presents a robust framework for a data-driven, explainable CBR system that excels in financial risk detection. By enhancing model transparency and interpretability, it addresses a critical need for compliance with regulatory standards like GDPR. The study sets the stage for future research, focusing on optimizing feature weighting methodologies and improving computational efficiency through alternative optimization algorithms.