Continual Backprop: Stochastic Gradient Descent with Persistent Randomness
Abstract: The Backprop algorithm for learning in neural networks utilizes two mechanisms: first, stochastic gradient descent and second, initialization with small random weights, where the latter is essential to the effectiveness of the former. We show that in continual learning setups, Backprop performs well initially, but over time its performance degrades. Stochastic gradient descent alone is insufficient to learn continually; the initial randomness enables only initial learning but not continual learning. To the best of our knowledge, ours is the first result showing this degradation in Backprop's ability to learn. To address this degradation in Backprop's plasticity, we propose an algorithm that continually injects random features alongside gradient descent using a new generate-and-test process. We call this the \textit{Continual Backprop} algorithm. We show that, unlike Backprop, Continual Backprop is able to continually adapt in both supervised and reinforcement learning (RL) problems. Continual Backprop has the same computational complexity as Backprop and can be seen as a natural extension of Backprop for continual learning.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a problem in how neural networks learn when the world keeps changing. The usual way to train neural networks is called Backpropagation (Backprop), which uses a method named stochastic gradient descent (SGD) and starts with small random weights. The authors discovered that while Backprop works well at first, it gets worse over time when the data or environment changes many times. They call this “decaying plasticity,” meaning the network becomes less able to adapt.
To fix this, they propose a new method called Continual Backprop (CBP). CBP keeps the network flexible by regularly adding new random features (like fresh ideas) and removing less useful ones, alongside the normal learning. They show that CBP can keep adapting in situations where Backprop slows down or breaks down.
The big questions the researchers asked
- Can standard Backprop keep adapting when the data changes many times over a long period?
- Why does Backprop’s ability to adapt fade over time?
- Can we design a simple, practical extension of Backprop that stays flexible and learning-ready all the time?
- Will the new method work in different types of problems, like image recognition and reinforcement learning?
How did they test their ideas?
Understanding Backprop and “randomness”
- Backprop is the standard way to train neural networks: it tweaks the network’s weights to reduce mistakes, one step at a time (this step-by-step tweak is SGD).
- At the start, the network’s weights are set to small random values. This randomness helps the network begin with a variety of useful “features” (think of features as little detectors or helpers inside the network).
- The key insight: Backprop uses randomness only at the beginning. After that, learning becomes predictable and can get stuck, especially when things keep changing.
What does “non-stationary” mean?
- “Stationary” means the data or task stays the same over time.
- “Non-stationary” means the data or task changes—sometimes a little, sometimes a lot—as time goes on. Real life is often non-stationary (e.g., robots in shifting environments, apps with changing user behavior).
- “Semi-stationary” problems are a special case: the input changes over time, but the underlying rule (the target function) remains the same.
The new idea: Continual Backprop (CBP)
- CBP keeps the good parts of Backprop (SGD) but adds a simple “generate-and-test” cycle:
- Generator: regularly proposes new random features, sampled from the same kind of randomness used at the start.
- Tester: looks for features that aren’t helping much and replaces them with the new random features.
- Think of a sports team:
- The generator is like scouting fresh players.
- The tester is like the coach benching underperformers and giving newcomers a chance.
- CBP protects new features briefly (so they don’t get removed immediately), and adds them in a way that doesn’t disrupt what the network already knows.
- Important: CBP uses constant memory and has similar computational cost to normal Backprop. It’s a practical upgrade, not a heavy add-on.
The three experiments
- Bit-Flipping problem (semi-stationary):
- The inputs are bits (0s and 1s). Some bits flip their value every so often (like the rules of a game changing), so the input pattern shifts thousands of times.
- The network must keep tracking the best way to predict outputs as the input distribution changes.
- Permuted MNIST (online image classification):
- MNIST is a dataset of handwritten digits.
- In “Permuted MNIST,” they shuffle the pixels of the images by a random permutation. After showing all images, they change the pixel permutation and continue. This creates many changes over time.
- The network must keep recognizing digits even as the pixel layout changes repeatedly.
- Slippery Ant (non-stationary reinforcement learning):
- An “Ant” robot in a physics simulator must learn to move.
- The ground’s friction changes drastically every so often (from very slippery to very sticky), forcing the agent to adapt its movement strategy.
- They used PPO (a popular RL algorithm) with and without CBP.
What did they find?
Here are the main results in simple terms:
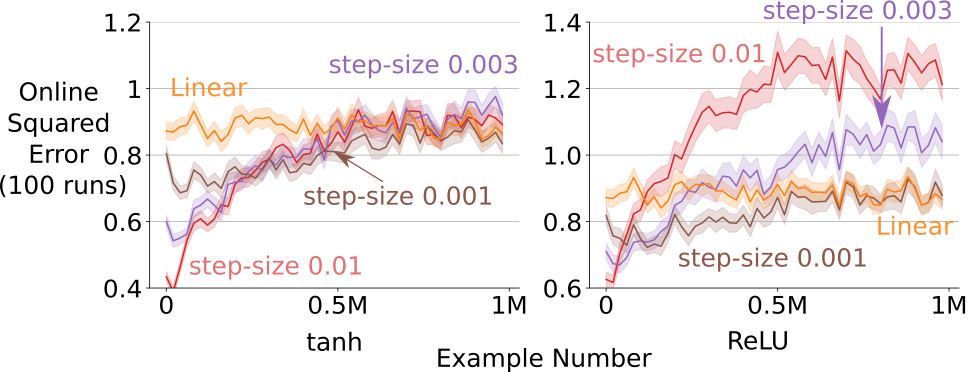
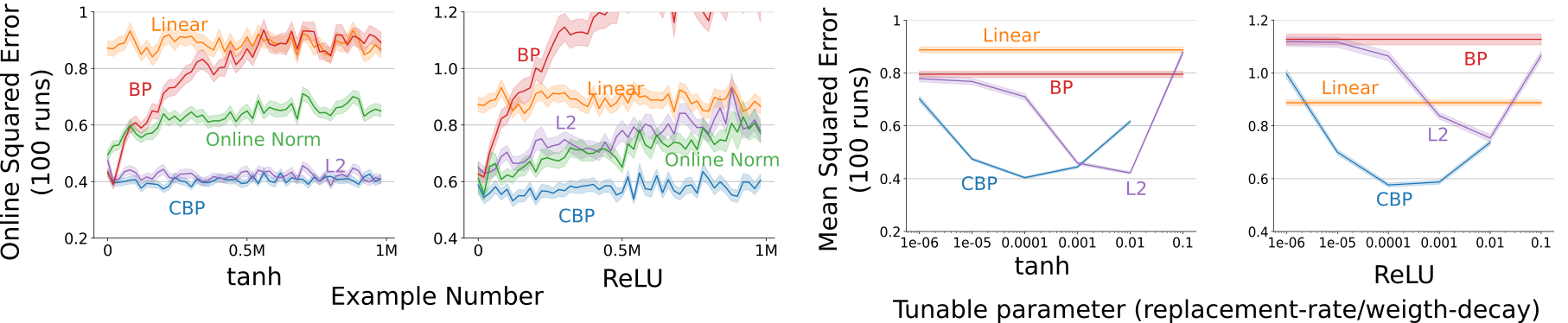
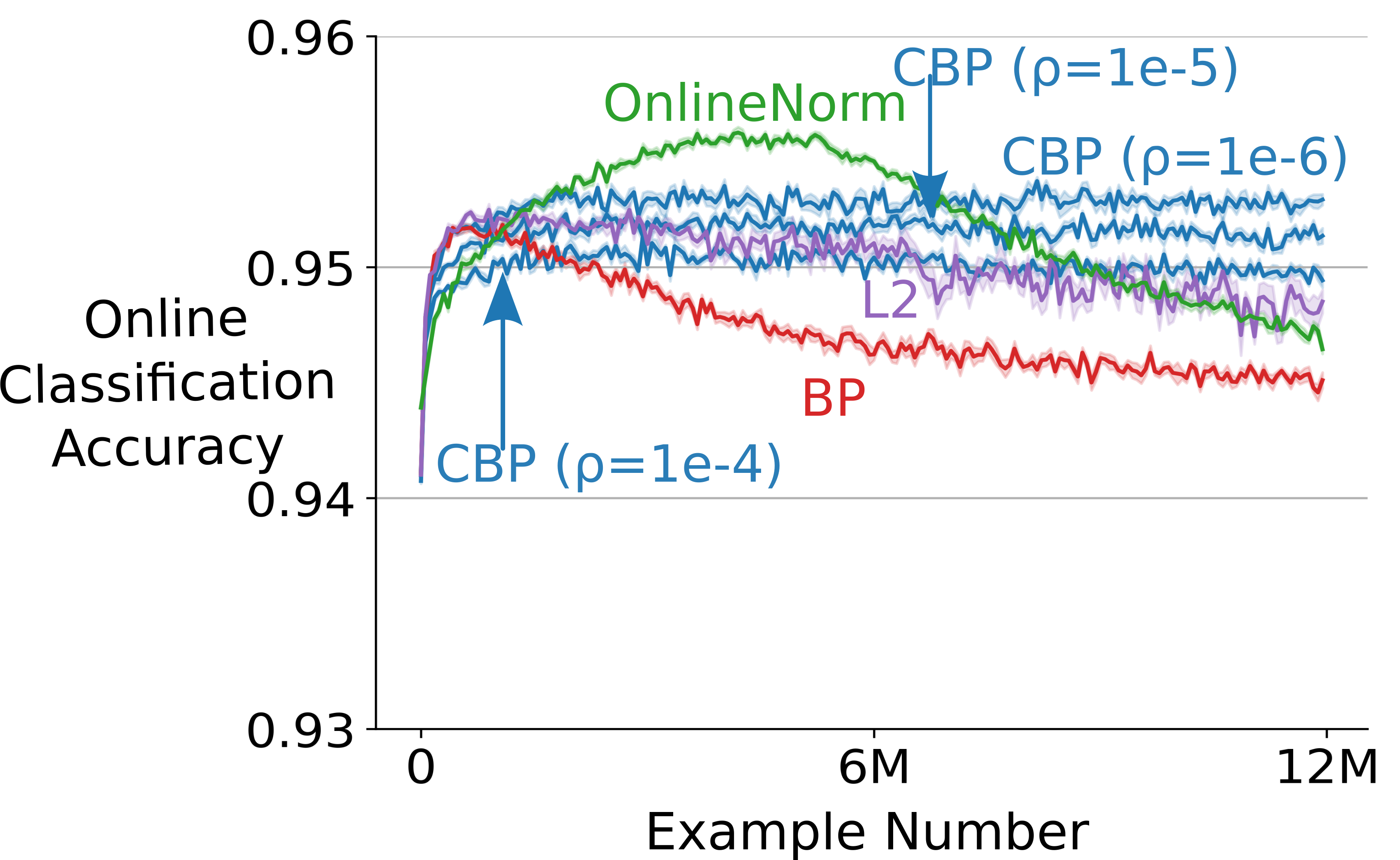
- Backprop adapts well at first, but its performance steadily gets worse as the data changes again and again. This happened in both supervised learning (Bit-Flipping, Permuted MNIST) and reinforcement learning (Slippery Ant).
- CBP stays flexible and maintains good performance over long periods with many changes. It keeps “plasticity” from fading because it continually injects fresh randomness.
- Common fixes that try to keep weights small or normalized (like L2 regularization or OnlineNorm) help sometimes, but they are not consistently stable across different problems and settings. CBP was more robust.
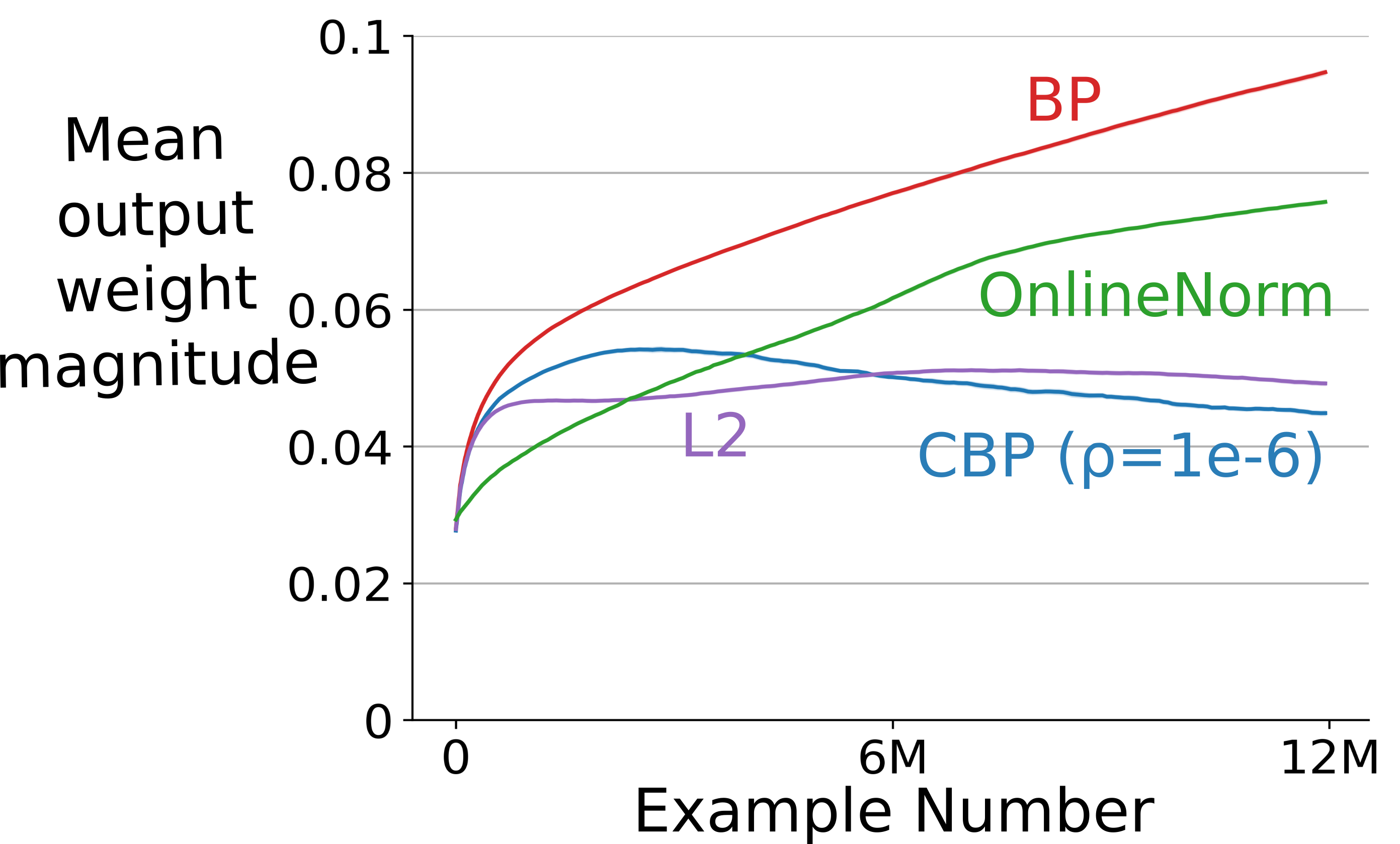
- They observed that in Backprop, weight magnitudes tend to grow over time, which can slow or destabilize learning. CBP counteracts this and also preserves diversity in features—not just small weights—by sampling new features directly from the original random distribution.
Why does this matter?
- Many real-world systems—like robots, online apps, and games—face constantly changing situations. They need models that can keep adapting without breaking down.
- The paper shows that standard Backprop alone is not enough for continual learning when there are many changes. This is an important, previously overlooked problem: “decaying plasticity.”
- CBP offers a simple, practical extension that you can add to existing neural network training to improve long-term adaptability, without big extra costs.
Limitations and future work
- The “tester” that decides which features to replace uses heuristics (rules of thumb). It works well, but more principled or theoretically grounded testers could make CBP even better.
- The authors expect future research to build on this idea, much like past work tackled “catastrophic forgetting.”
Key takeaways
- Backprop’s strength fades over long, changing environments; its plasticity decays.
- Continual Backprop (CBP) keeps the network fresh by regularly adding random features and removing weak ones.
- CBP adapts better over time than standard Backprop, L2 regularization, or OnlineNorm in the tested settings.
- CBP is a natural, low-cost extension to Backprop designed for continual learning.
Knowledge Gaps
Below is a concise list of the key knowledge gaps, limitations, and open questions the paper leaves unresolved. Each point is framed to suggest concrete directions for future research.
- Lack of theory for “decaying plasticity”: no formal analysis explaining why/when Backprop’s adaptability declines under extended tracking, nor conditions under which it does not.
- No tracking or dynamic-regret guarantees: CBP lacks theoretical bounds on tracking error, stability, or adaptation rate as a function of non-stationarity (e.g., drift rate, change frequency).
- Heuristic tester: utility metric and generate-and-test policy are heuristic; no principled derivation (e.g., from information gain, Fisher curvature, or control of dynamic regret).
- Missing ablations toward causal mechanisms: the paper hypothesizes several beneficial properties of initialization (small weights, non-saturation, diversity) but does not isolate causal effects with controlled interventions or measurements (e.g., saturation metrics, gradient norms, feature diversity).
- Incomplete sensitivity analysis: only partial sweeps are shown (ρ and weight decay). Little analysis of the maturity threshold m, decay rate η, and their interaction with step size, optimizer, and non-stationarity rate.
- No adaptive scheduling: replacement-rate ρ and maturity m are fixed; no adaptive policies that adjust replacement intensity to observed drift or confidence.
- Generator design is fixed: new features are always sampled from the initial distribution; no exploration of learned, data-dependent, or diversity-promoting generators, nor of how the choice of initialization distribution impacts performance.
- Replacement policy granularity: feature selection/removal is per-unit with absolute-value utilities; no study of structured replacements (e.g., convolutional channels, attention heads) or group-wise criteria.
- Computational overhead claims unquantified: CBP is said to have “same computational complexity” as Backprop, but the per-step cost and memory overhead of utility tracking and replacements are not characterized (big-O and constants, GPU throughput).
- Scalability to large models: no benchmarks on modern large-scale architectures (e.g., ResNets, Transformers) or training regimes (data-parallel, mixed precision, distributed synchronization of replacements).
- Architectural generality not tested: claims applicability to “arbitrary feed-forward networks” but no experiments with CNNs, RNNs/LSTMs, attention/Transformers, residual/skip connections, or normalization-heavy models (LayerNorm, RMSNorm).
- Interaction with normalization: only OnlineNorm is tested; interactions with BatchNorm (streaming variants), LayerNorm, and weight standardization remain unexplored.
- Mini-batch training: experiments are fully online; effects of CBP under standard mini-batch regimes (with shuffling, momentum, LR schedules) are not evaluated.
- Baseline coverage: comparisons omit several continual/adaptive methods (e.g., EWC/SI/MAS, OGD/A-GEM, replay buffers, meta-gradients, progressive nets, MAML-like methods, dropout/noise-regularized baselines).
- Retention vs adaptation trade-off: the study focuses on adaptation and does not measure forgetting; unclear how CBP impacts long-term retention or how to balance plasticity and stability.
- RL safety and stability: replacing features online in policy/value networks may induce abrupt behavior changes; no analysis of stability, safety constraints, or trust-region-compatible replacement rules.
- RL generality: only one non-stationary RL setting (friction changes in Ant with PPO). No evaluation across algorithms (SAC, DDPG, off-policy methods), environment types (POMDPs, multi-agent, sparse rewards), or drift patterns (gradual/sudden/recurring).
- Non-stationarity taxonomy: experiments cover semi-stationary (covariate shift) and one RL setting; no coverage of label/target drift in supervised learning, concept drift types, or adversarial/seasonal drift.
- Overparameterized regimes: decaying plasticity is shown for modest-capacity networks; unclear whether highly overparameterized models (common in practice) exhibit the same degradation and whether CBP still helps.
- Replacement side effects: zeroing outgoing weights for new features could slow their integration or create gradient starvation; no study of alternative initialization of outgoing weights or warm-start strategies.
- Bias-correction details and correctness: the utility equations include bias-corrected running averages; their statistical properties, numerical stability, and implementation robustness are not analyzed.
- Utility design alternatives: adaptation-utility uses inverse incoming weight magnitude; no comparison to curvature-aware or optimizer-aware metrics (e.g., Fisher, Hessian trace, per-parameter LR in AdamW).
- Removal impact on function continuity: while mean-corrected contribution is intended to mitigate bias shifts, there is no empirical audit of functional continuity or prediction drift upon replacement events.
- Adaptive capacity: CBP keeps capacity constant; no exploration of dynamic capacity growth/shrinkage, mixture-of-experts routing, or sparsity-inducing mechanisms aligned with continual adaptation.
- Hyperparameter selection online: best settings are chosen via offline sweeps; no mechanisms for online hyperparameter adaptation/tuning under non-stationarity (e.g., bandit/meta-gradient schemes).
- Robustness to noise: behavior under label noise, outliers, or non-stationarity confounded by noise is not evaluated.
- Data realism: permuted MNIST constitutes extreme pixel permutations; applicability to realistic image/video streams (temporal correlations, local shifts) is untested.
- Feature granularity and interpretability: the notion of a “feature” is unit-level; implications for interpretability and for structured features (kernels/heads) are not studied.
- Distributed consistency: how to coordinate feature replacement and utility statistics across workers/nodes in distributed training is not addressed.
- Exploration/uncertainty: persistent randomness may interact with uncertainty estimation and exploration (especially in RL); effects on calibration and exploration efficiency are not measured.
- Change-point detection: CBP uses blind periodic replacement; no comparison with change-detection-triggered replacement or multi-timescale mechanisms aligned to drift dynamics.
- Reproducibility details: several implementation specifics (exact seeds, code availability, full hyperparameter settings for all runs) are missing or relegated to appendices, limiting independent verification.
Collections
Sign up for free to add this paper to one or more collections.