- The paper's main contribution is the VOIN framework that integrates transformer-based object shape completion, residual flow completion, and flow-guided inpainting.
- It achieves improved occlusion handling and flow prediction, significantly lowering endpoint error and enhancing visual quality and temporal consistency.
- The introduced YouTube-VOI benchmark provides diverse scenarios, validating the framework’s robustness in real-world video inpainting applications.
Occlusion-Aware Video Object Inpainting
The paper "Occlusion-Aware Video Object Inpainting" focuses on the development of a self-supervised framework for performing video object inpainting that is both occlusion-aware and object-oriented. The method aims to recover the shape and appearance of occluded objects in videos with a high degree of temporal consistency by leveraging a newly proposed large-scale benchmark called YouTube-VOI.
Problem Setting and Dataset
The primary limitation of conventional video inpainting methods is their lack of object and occlusion awareness, which results in artifacts when dealing with significant occluded regions. This paper introduces occlusion-aware video object inpainting aimed at addressing this gap through the VOIN (Video Object Inpainting Network) framework. The YouTube-VOI benchmark constructed for this work provides comprehensive and diverse training and evaluation scenarios with both visible and occluded object masks across various categories, inducing challenging occlusion cases derived from realistic video content.

Figure 1: Video object inpainting results comparison with state-of-the-art LGTSM, FGVC, and STTN.
The VOIN Framework
VOIN integrates multiple stages of processing: (1) object shape completion, (2) object flow completion, and (3) flow-guided inpainting. The object shape completion uses a transformer-based module to capture spatio-temporal coherence, enabling the recovery of the complete shape of occluded objects. The flow completion leverages a residual learning approach to predict accurate flow within the occluded regions, harnessing sharp motion boundaries and maintaining smooth flow transitions.
Occlusion-Aware Modules
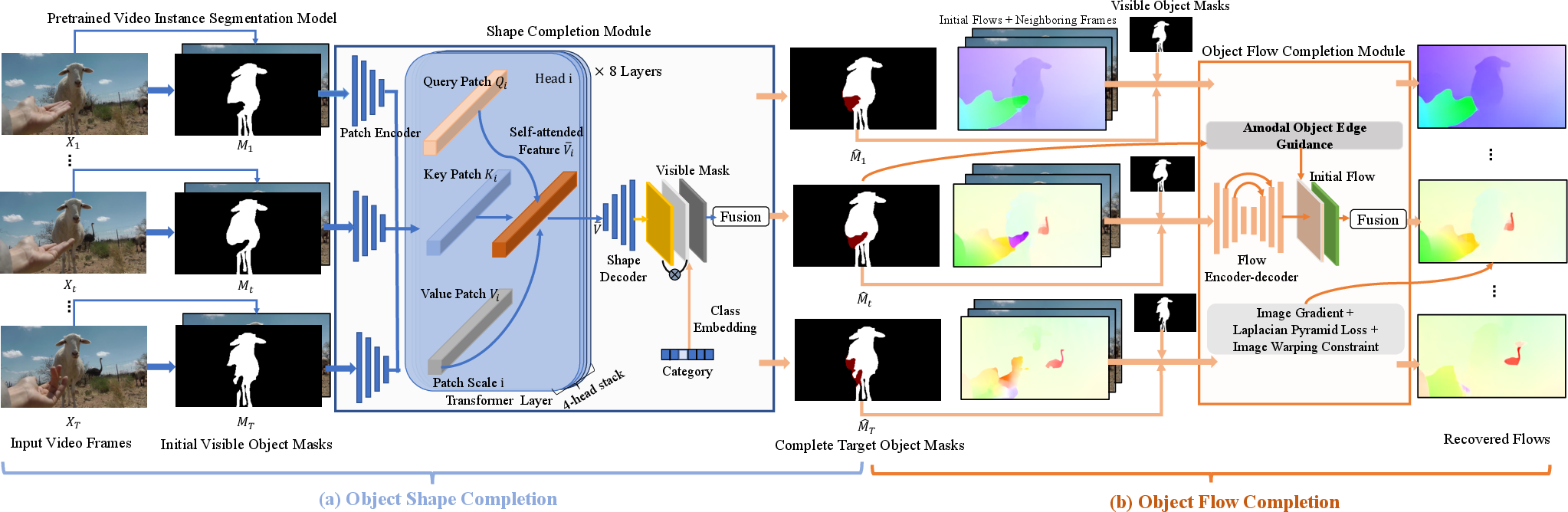
Figure 2: (a) Object shape completion, associating transformed temporal patches and object semantics; (b) Object flow completion with complete flow subject to the amodal object contours.
Flow-Guided Video Object Inpainting
The refined flows drive the pixel propagation to ensure continuity across frames even for temporally distant ones. An occlusion-aware gated generator is proposed to address any remaining unseen regions, utilizing both spatio-temporal multi-class adversarial loss and flow consistency to enhance the completion's realism.
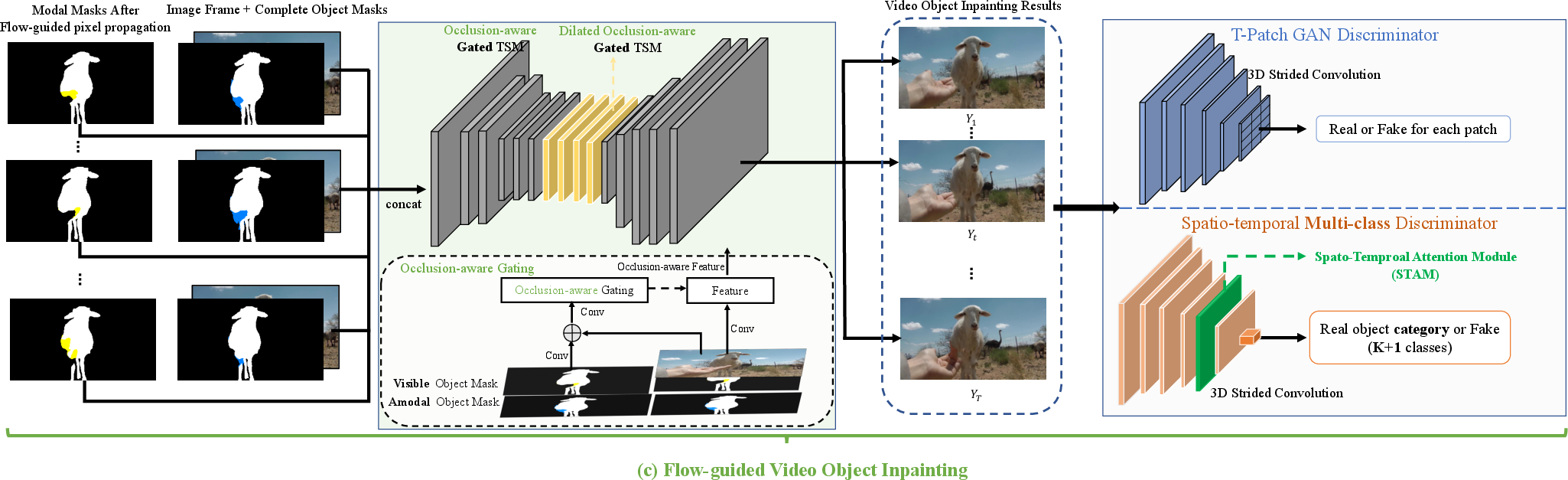
Figure 3: Flow-guided video object inpainting using an occlusion-aware gating scheme.
Experimental Evaluation
The experiments demonstrate VOIN's efficacy over strong baselines in metrics like PSNR, SSIM, and LPIPS on the YouTube-VOI benchmark. The detailed quantitative and qualitative analyses highlight the superiority of VOIN in maintaining spatial detail and temporal coherence across complex dynamic scenes.
Figure 4: Sample visual results of VOIN showcasing robustness given inaccurate mask segmentation.
Notable Findings and Implications
- Flow Completion Improvement: VOIN's flow completion achieves lower endpoint error (EPE) compared with existing methods by leveraging amodal shape guidance and hybrid loss, thus recovering object flows more accurately.
- Occlusion Handling: The occlusion-aware components, such as the improved TSM, inject significant robustness in occlusion conditions leading to better visual quality and temporal consistency.
- Real-world Application Potential: By addressing occlusion concretely, the proposed framework offers promising avenues for applications in video editing, visual effects, and possibly enhancing object tracking performance under occlusion-heavy scenarios.
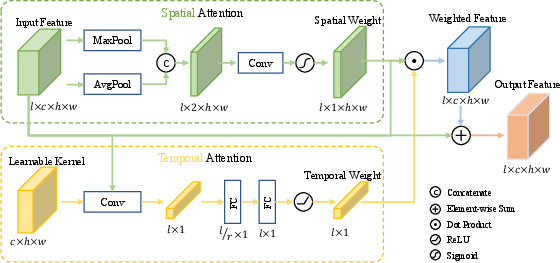
Figure 5: Illustration of the spatial and temporal attention module (STAM), pivotal for enhancing multi-class discriminator performance.
Conclusion
The paper presents a substantial contribution towards addressing the challenges of occlusion-aware video object inpainting. By constructing a novel benchmark and proposing the VOIN framework, the research provides a robust foundation for future advancements in video inpainting and related applications. The integration of spatio-temporal attentiveness and occlusion-aware mechanisms creates a pathway for further exploration of temporally coherent video restoration techniques.
Overall, the findings suggest promising advancements in handling occlusions, a step forward for achieving seamless video object inpainting in realistic scenarios.