- The paper introduces AASIST, integrating graph attention with a RawNet2-based encoder to effectively distinguish genuine from spoofed audio.
- It employs a novel HS-GAL and Max Graph Operation to process both spectral and temporal features, streamlining the anti-spoofing system.
- Experimental evaluation on ASVspoof 2019 shows a 20% decrease in min t-DCF and improved EER, supporting practical deployment.
AASIST: Audio Anti-Spoofing using Integrated Spectro-Temporal Graph Attention Networks
Introduction
The paper "AASIST: Audio Anti-Spoofing using Integrated Spectro-Temporal Graph Attention Networks" (2110.01200) introduces a novel approach to audio anti-spoofing, specifically targeting the challenges associated with effectively distinguishing between genuine and spoofed audio utterances. Traditional systems often rely on complex ensemble systems capable of detecting multiple types of spoofing artefacts across different domains. The proposed solution, AASIST, seeks to streamline this process by integrating spectral and temporal information within a single, comprehensive system, enhancing both efficiency and performance.
Architecture Overview
The architecture of AASIST leverages graph attention networks to model both spectral and temporal features, employing a RawNet2-based encoder to extract high-level representations from raw waveform inputs. The core innovation introduced is the Heterogeneous Stacking Graph Attention Layer (HS-GAL), which facilitates flexible attention mechanisms capable of addressing the unique characteristics of spectral and temporal data.
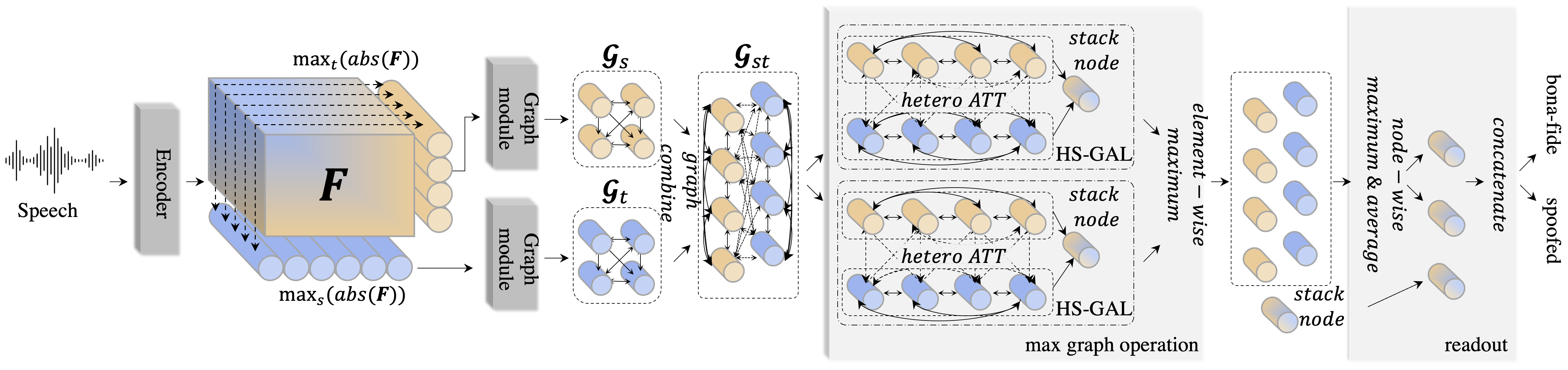
Figure 1: Overall framework of the proposed AASIST. Identical to prior architectures with enhancements in the max graph operation for parallel heterogeneous graph modeling.
The HS-GAL layer is further enhanced by the integration of a novel Max Graph Operation (MGO) designed to encourage the system to focus on salient artefacts via competitive selection, as well as an advanced readout procedure to capture refined global graph representations.
Key Components
RawNet2-Based Encoder
AASIST employs a RawNet2-based encoder that directly processes raw audio waveforms. This encoder is composed of sinc-convolution filters, followed by multiple residual blocks, endowing it with the ability to perform effective spectral and temporal modeling. The output is treated as a two-dimensional spectral representation, feeding into subsequent graph modeling stages.
Graph Attention Networks
Overall, graph attention networks are utilized within AASIST for their ability to attentively weigh connections between audio features, crucial for distinguishing nuanced differences typical of spoofed versus bona fide audio samples. The AASIST model refines this approach with the HS-GAL, specializing in the simultaneous operation on heterogeneous subgraphs—one spectral and one temporal—thereby retaining domain-specific characteristics while facilitating interaction.
Max Graph Operation and Readout
The Max Graph Operation, a vital component of the AASIST model, operates by maximally aggregating information across parallel graph processing channels. This operation ensures robust artifact detection across different spoofing scenarios by dynamically focusing on the most informative graph features. Subsequently, the readout mechanism, which includes averaging, max-pooling of node representations, and the integration of a 'stack' node, crafts a comprehensive global feature set for ultimate classification.
Experimental Evaluation
AASIST was rigorously evaluated on the ASVspoof 2019 Logical Access dataset, demonstrating significant improvements over the state-of-the-art, evidenced by a 20% relative improvement in minimum tandem detection cost function (min t-DCF) and substantial gains in Equal Error Rate (EER) metrics utilized for assessment.
Implications and Future Work
The proposed AASIST model brings forth critical improvements in the audio anti-spoofing landscape by significantly reducing model complexity while enhancing performance, making strides towards practical deployment scenarios, including resource-constrained environments. Future developments may explore further optimizations in graph attention mechanisms or extend this approach to other multimodal spoofing contexts.
Conclusion
The AASIST framework exemplifies an innovative application of graph neural networks in anti-spoofing tasks, enhancing both efficiency and efficacy. It stands as a compelling stride forward in the domain of audio security, setting a robust foundation for further advancements in the detection of increasingly sophisticated spoofing techniques.