- The paper introduces DGPNet, a novel approach that integrates dense Gaussian Process regression into CNNs for few-shot segmentation.
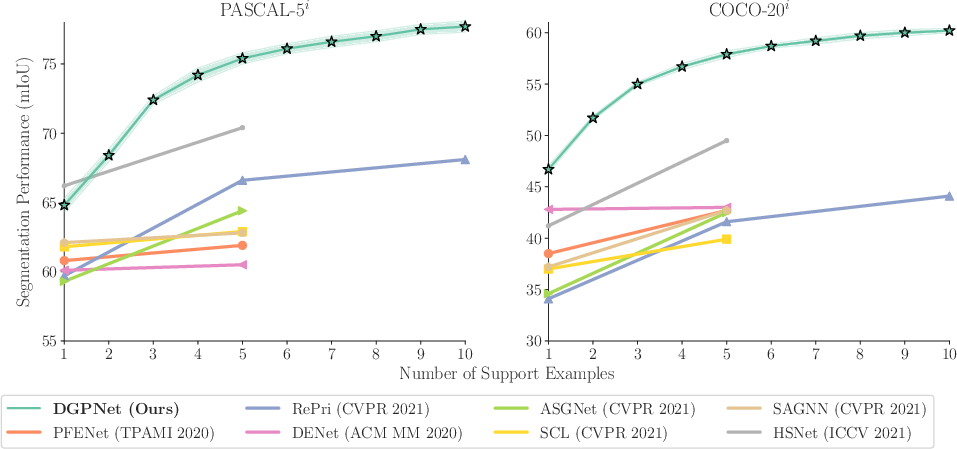
- It captures complex appearance variations and uncertainty, achieving an 8.4 mIoU gain on benchmarks like PASCAL-5^i and COCO-20^i.
- The method scales with larger support sets through learning the GP output space and effective uncertainty modeling for improved mask prediction.
Dense Gaussian Processes for Few-Shot Segmentation
The paper "Dense Gaussian Processes for Few-Shot Segmentation" (2110.03674) introduces a novel approach to few-shot segmentation (FSS) that leverages dense Gaussian process (GP) regression to address the challenges of limited annotated data and significant variations in appearance and context. The proposed method, DGPNet, learns the mapping from local deep image features to mask values using a dense GP, effectively capturing complex appearance distributions and providing a principled means of capturing uncertainty. By integrating the GP as a layer in a CNN and learning the output space of the GP, DGPNet achieves state-of-the-art results on the PASCAL-5i and COCO-20i benchmarks.
Addressing Challenges in Few-Shot Segmentation
FSS aims to segment novel query images given only a small annotated support set. A key challenge is designing a mechanism that effectively extracts and aggregates information from the support set while remaining robust to variations in appearance and context. Specifically, the design of this module must address three key challenges:
- Flexibility of f: The few-shot learner must be able to learn and represent complex functions to segment a wide range of classes unseen during training.
- Scalability in support set size K: The method should effectively leverage additional support samples to achieve better accuracy and robustness for larger support sets.
- Uncertainty Modeling: The network needs to handle unseen appearances in the query images and assess the relevance of the information in the support images.
Dense Gaussian Process Few-Shot Learner
To address these challenges, the paper proposes a dense Gaussian Process (GP) learner for few-shot segmentation. A GP is used to learn a mapping between dense local deep feature vectors and their corresponding mask values. This approach provides several advantages:
The dense GP learner predicts a distribution of functions f from the input features x to an output y. The key assumption is that the support and query outputs are jointly Gaussian:
$\begin{pmatrix}\mathbf{y}_\support \ \mathbf{y}_\query\end{pmatrix} \sim \mathcal{N} \left( \begin{pmatrix} \bm{\mu}_\support \ \bm{\mu}_\query \end{pmatrix}, \begin{pmatrix} \mathbf{K}_{\support\support} & \mathbf{K}_{\support\query} \ \mathbf{K}_{\support\query}\tp & \mathbf{K}_{\query\query} \end{pmatrix} \right)$.
The posterior probability distribution of the query outputs is then inferred based on the rules for conditioning in a joint Gaussian:
$\mathbf{y}_\query|\mathbf{y}_\support, \mathbf{x}_\support, \mathbf{x}_\query \sim \mathcal{N}(\bm{\mu}_{\query|\support},\bm{\Sigma}_{\query|\support})$,
where
$\bm{\mu}_{\query|\support} = \mathbf{K}_{\support\query}\tp(\mathbf{K}_{\support\support}+\sigma_y^2 \mathbf{I})^{-1} \mathbf{y}_\support$,
$\bm{\Sigma}_{\query|\support} = \mathbf{K}_{\query\query} - \mathbf{K}_{\support\query}\tp(\mathbf{K}_{\support\support}+\sigma_y^2 \mathbf{I})^{-1} \mathbf{K}_{\support\query}$.
Learning the GP Output Space and Final Mask Prediction
To further improve the performance, the paper introduces a method for learning the GP output space during the meta-training stage. A mask-encoder is trained to construct the outputs, allowing additional information to be encoded into the outputs to guide the decoder. The decoder transforms the query outputs predicted by the few-shot learner into an accurate mask by processing the GP output mean and covariance, as well as shallow image features.
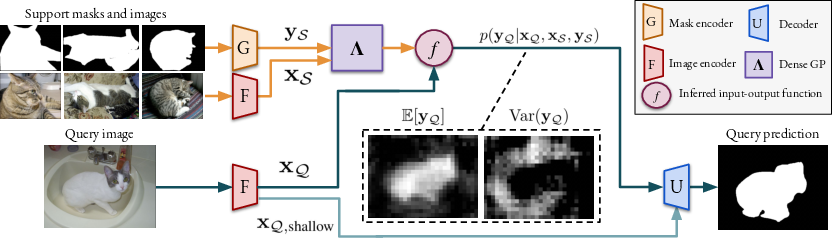
Figure 2: Overview of the proposed approach, showing how support and query images are processed to infer the probability distribution of query mask encodings using Gaussian process regression.
The final mask is predicted by feeding the GP output mean zμ, GP output covariance zΣ, and shallow image features $\mathbf{x}_{\query,\shallow}$ into a decoder U:
$\widehat{M}_\query = U(z_\mu, z_\Sigma, \mathbf{x}_{\query,\shallow})$.
Experimental Results
The proposed DGPNet was evaluated on the PASCAL-5i and COCO-20i benchmarks. The results demonstrate that DGPNet outperforms existing methods for 5-shot by a significant margin, achieving a new state-of-the-art on both benchmarks. Specifically, DGPNet achieves an absolute gain of 8.4 mIoU for 5-shot segmentation on the COCO-20i benchmark compared to the best reported results in the literature when using the ResNet101 backbone.

Figure 3: Qualitative results of the approach with 1, 5, and 10 support samples, showing how performance improves with more support.
The paper also demonstrates the cross-dataset transfer capabilities of DGPNet from COCO-20i to PASCAL. Ablative studies are conducted to probe the effectiveness of different components, including the choice of kernel, the incorporation of predictive covariance, and the benefits of learning the GP output space. The study shows that the SE kernel greatly outperforms the linear kernel and that incorporating uncertainty and learning the GP output space further improves the results.



Figure 4: Qualitative comparison between the proposed model and a baseline in the 1-shot setting from the COCO-20i benchmark.




Figure 5: Qualitative results on challenging episodes in the 1-shot setting from the PASCAL-5i benchmark.






Figure 6: Qualitative results on challenging episodes in the 1-shot setting from the COCO-20i benchmark.
Conclusion
The dense GP learner based on Gaussian process regression offers a promising approach for few-shot segmentation (2110.03674). The GP models the support set in deep feature space, and its flexibility permits it to capture complex feature distributions. It makes probabilistic predictions on the query image, providing both a point estimate and additional uncertainty information. These predictions are fed into a CNN decoder that predicts the final segmentation. The resulting approach sets a new state-of-the-art on 5-shot PASCAL-5i and COCO-20i, with absolute improvements of up to 8.4 mIoU. The approach also scales well with larger support sets during inference, even when trained for a fixed number of shots. This work highlights the potential of GPs for few-shot learning and opens up new avenues for future research. Future work could explore more advanced kernel functions, investigate different architectures for the mask encoder and decoder, and apply the approach to other few-shot learning tasks.