- The paper introduces ViDT, which combines Vision and Detection Transformers via a reconfigured attention module to enhance both efficiency and accuracy.
- It employs an encoder-free neck and token matching knowledge distillation to streamline object detection while maintaining competitive average precision.
- Experimental results on the COCO benchmark show that ViDT achieves 49.2 AP with a favorable latency trade-off compared to existing detectors.
The paper "ViDT: An Efficient and Effective Fully Transformer-based Object Detector" (2110.03921) introduces ViDT, a novel object detection architecture that integrates Vision Transformers (ViT) and Detection Transformers (DETR) to achieve state-of-the-art performance with improved computational efficiency. The core innovation lies in the Reconfigured Attention Module (RAM), which enables the use of ViT variants, specifically the Swin Transformer, as standalone object detectors. This is coupled with a lightweight, encoder-free neck architecture and a token matching knowledge distillation technique to further enhance performance and efficiency. ViDT achieves a compelling balance between accuracy and speed, demonstrating its potential for practical applications in object detection.
Key Components and Implementation
ViDT's architecture comprises three main components: a reconfigured ViT backbone, an encoder-free neck, and a prediction head.
The RAM is the cornerstone of ViDT, enabling the integration of ViTs, particularly Swin Transformers, into a sequence-to-sequence object detection framework. RAM decomposes the attention mechanism into three distinct operations:
RAM reuses the projection layers of the Swin Transformer for both [DET] and [PATCH] tokens. Positional encodings are handled differently for each attention type: relative position bias for [PATCH]×[PATCH] attention, learnable positional encoding for [DET]×[DET] attention, and sinusoidal spatial positional encoding for [DET]×[PATCH] attention. The spatial positional encoding is added to the [PATCH] tokens before the projection layer. To minimize computational overhead, the [DET]×[PATCH] cross-attention is applied only at the last stage of the Swin Transformer.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
def reconfigured_attention(query_patches, key_patches, value_patches,
query_det, key_det, value_det):
"""
Reconfigured Attention Module (RAM) for ViDT.
Args:
query_patches: Query embeddings for image patches.
key_patches: Key embeddings for image patches.
value_patches: Value embeddings for image patches.
query_det: Query embeddings for detection tokens.
key_det: Key embeddings for detection tokens.
value_det: Value embeddings for detection tokens.
Returns:
Updated patch and detection token embeddings.
"""
# Patch self-attention (local attention using shifted windows)
updated_patches = swin_transformer_attention(query_patches, key_patches, value_patches)
# Detection token self-attention (global self-attention)
attention_det = torch.matmul(query_det, key_det.transpose(-2, -1)) / math.sqrt(query_det.size(-1))
attention_det = torch.softmax(attention_det, dim=-1)
updated_det_det = torch.matmul(attention_det, value_det)
# Detection token cross-attention (attention over patches)
attention_cross = torch.matmul(query_det, key_patches.transpose(-2, -1)) / math.sqrt(query_det.size(-1))
attention_cross = torch.softmax(attention_cross, dim=-1)
updated_det_cross = torch.matmul(attention_cross, value_patches)
# Combine updated detection tokens
updated_det = updated_det_det + updated_det_cross
return updated_patches, updated_det |

Figure 2: Reconfigured Attention Module (Q: query, K: key, V: value). The skip connection and feedforward networks following the attention operation is omitted just for ease of exposition.
Encoder-Free Neck Structure
ViDT employs an encoder-free neck structure, comprising a decoder of multi-layer deformable transformers. This design choice is motivated by the RAM's ability to directly extract fine-grained features suitable for object detection, eliminating the need for a transformer encoder. The decoder receives multi-scale feature maps {xl}l=1L from each stage of the Swin Transformer and [DET] tokens from the last stage. Each deformable transformer layer performs [DET]×[DET] attention followed by multi-scale deformable attention:
${\rm MSDeformAttn}([\mathtt{DET}], \{ {\bm x^{l} \}_{l=1}^{L}) = \sum_{m=1}^{M} {\bm W_m} \Big[ \sum_{l=1}^{L} \sum_{k=1}^{K} A_{mlk} \cdot {\bm W_m^{\prime} {\bm x^{l}\big(\phi_{l}({\bm p}) + \Delta {\bm p_{mlk}\big) \Big]$
Here, m indexes the attention head, K is the number of sampled keys, ϕl(p) is the reference point, Δpmlk is the sampling offset, and Amlk represents the attention weights. Auxiliary decoding loss and iterative box refinement techniques are incorporated to further enhance detection performance.
Token Matching Knowledge Distillation
The paper introduces a knowledge distillation approach using token matching to transfer knowledge from a large, pre-trained ViDT model (teacher) to a smaller model (student). This leverages the fixed number of [PATCH] and [DET] tokens across different ViDT models. The distillation loss is formulated as:
$\ell_{dis}(\mathcal{P}_{s}, \mathcal{D}_{s}, \mathcal{P}_{t}, \mathcal{D}_{t}) = \lambda_{dis} \Big( \frac{1}{|\mathcal{P}_s|} \sum_{i=1}^{|\mathcal{P}_s|} \norm[\Big]{ \mathcal{P}_s[i] - \mathcal{P}_t[i] }_{2} + \frac{1}{|\mathcal{D}_s|} \sum_{i=1}^{|\mathcal{D}_s|} \norm[\Big]{ \mathcal{D}_s[i] - \mathcal{D}_t[i] }_{2} \Big)$.
Only tokens contributing the most to prediction are matched. P and D represent the sets of [PATCH] and [DET] tokens, respectively, with subscripts s and t denoting the student and teacher models.
Experimental Results
ViDT demonstrates superior performance on the Microsoft COCO benchmark, achieving the best AP and latency trade-off compared to existing fully transformer-based object detectors. Ablation studies validate the effectiveness of the RAM, spatial positional encoding, and auxiliary techniques. Knowledge distillation with token matching further improves performance without compromising efficiency. The paper also shows that decoding layer dropping can expedite inference with minimal impact on accuracy. ViDT achieves 49.2 AP with the Swin-base backbone.
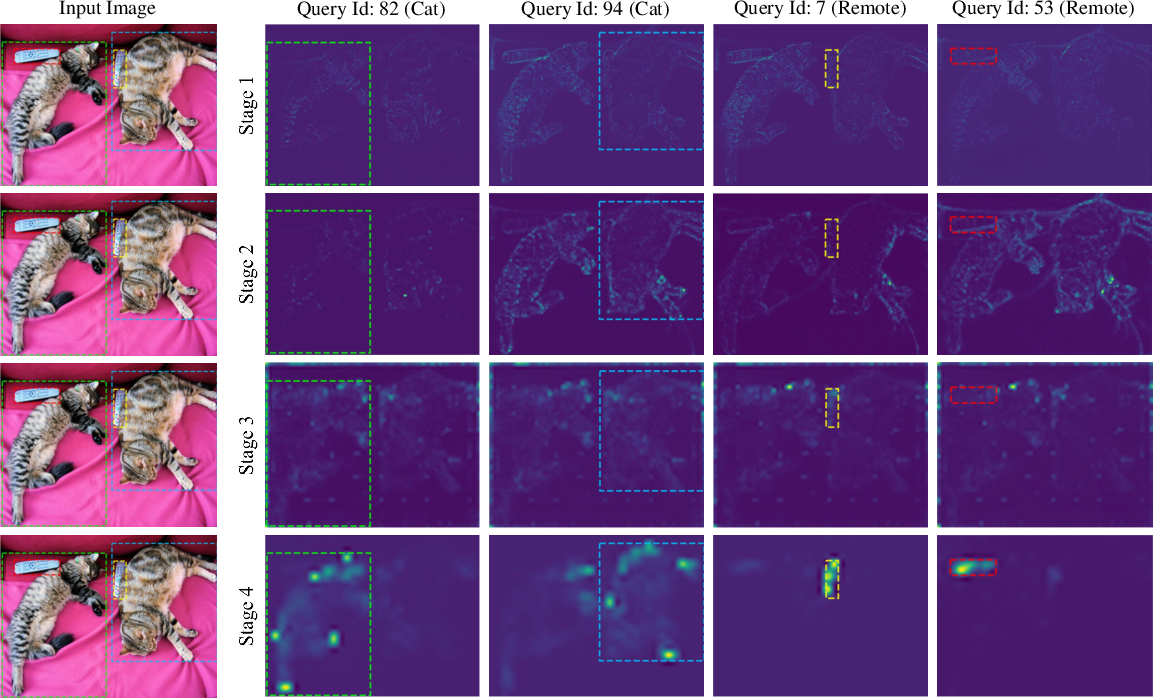

Figure 3: {Visualization of the attention map for cross-attention with ViDT\,(Swin-nano).
Implications and Future Directions
ViDT's architecture offers significant advantages in terms of scalability, flexibility, and efficiency for object detection. The use of RAM allows for the seamless integration of various ViT backbones, while the encoder-free neck reduces computational overhead. The token matching knowledge distillation provides a simple yet effective way to transfer knowledge and improve the performance of smaller models. Further research could explore the integration of ViDT with other efficient vision transformer architectures. Future work could also focus on optimizing the design of the neck decoder and exploring alternative knowledge distillation strategies. The exploration of ViDT's applicability to other vision tasks, such as instance segmentation and object tracking, represents another promising avenue for future research.
Conclusion
ViDT presents a compelling approach to object detection by effectively integrating vision and detection transformers. The reconfigured attention module, encoder-free neck, and token matching knowledge distillation contribute to its high accuracy, efficiency, and scalability. ViDT's performance on the COCO benchmark highlights the potential of fully transformer-based models for complex computer vision tasks.
