- The paper proposes a novel offline RL method that uses expectile regression to estimate upper bounds of Q-values without evaluating out-of-sample actions.
- It integrates a SARSA-style TD backup for updating the Q-function, demonstrating robust performance on various D4RL benchmarks.
- IQL simplifies implementation by avoiding distribution shifts, offering a computationally efficient and scalable solution for offline reinforcement learning.
Offline Reinforcement Learning with Implicit Q-Learning
Introduction
The paper "Offline Reinforcement Learning with Implicit Q-Learning" presents a novel approach to offline RL that avoids significant distributional shift challenges by forgoing the evaluation of unseen actions during training. Traditional offline RL methods typically walk a fine line between improving policies beyond the behavior that generated the training data and maintaining these improvements within in-distribution actions to prevent inaccuracies caused by distributional shifts.
Expectile Regression
The core of the approach hinges on the innovative use of expectile regression rather than conventional quantile regression, which affords an asymmetric squared loss function. This approach enables the method to estimate expectile values that emphasize higher-value outcomes, thereby creating a robust approximation of the stochastic upper bounds of expected returns.
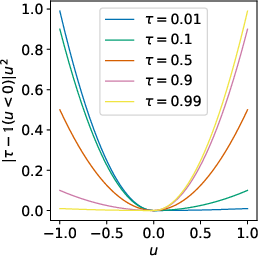
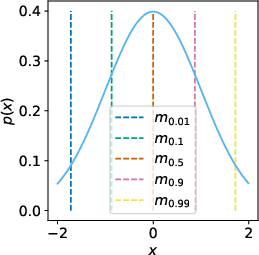
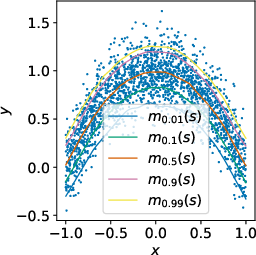
Figure 1: Visual representation showcasing how expectile regression estimates the maximum of a random variable over supported values in an offline RL setting.
Implicit Q-Learning Method
Implicit Q-Learning (IQL) is designed to periodically fit value functions using expectile regression on the existing data, followed by applying a SARSA-style TD backup to the Q-function. This method constructs a robust estimation of optimal Q-values by leveraging only in-sample data actions, circumventing the potential inaccuracies introduced by out-of-sample action evaluations. IQL distinguishes itself by maintaining simplicity in implementation and computational efficiency, requiring just an augmentation of the TD loss function with an asymmetric L2 loss.
Model Implementation
IQL operates in two major phases:
- Value Function Fitting: The value function Vψ(s) is trained with expectile regression to approximate the stochastic upper bounds of the Q-values, thus focusing more on the state-action combinations within the dataset, described by:
LV(ψ)=E(s,a)∼D[L2τ(Qθ^(s,a)−Vψ(s))]
- Q-Function Update: Subsequently, using an MSE loss over these expectiles, it updates the Q-function:
LQ(θ)=E(s,a,s′)∼D[(r(s,a)+γVψ(s′)−Qθ(s,a))2]
Once the Q-function is structured, policies are extracted using advantage-weighted behavioral cloning, thereby facilitating effective decision-making without evaluating non-observed action policies.
Experiments and Results
IQL was extensively evaluated on diverse D4RL benchmarks, with strong performance observed in both locomotion and maze-navigation tasks. Notably, the algorithm demonstrated advantageous results when applied to environments demanding multi-step dynamic programming capabilities.

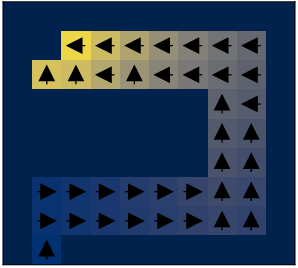

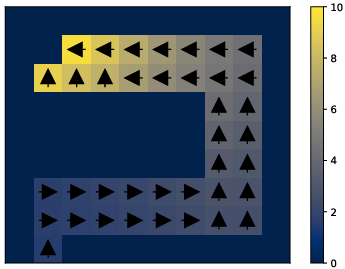
Figure 2: An illustrative U-shaped maze used to benchmark IQL, highlighting its prowess in complex decision-making scenarios where traditional singular-step methods underperform.
Conclusion
The innovative framework proposed in this paper successfully navigates the intricacies of offline RL by wholly sidestepping the direct evaluation of actions not contained within the data, thereby achieving impressive computational efficiency and accuracy gains. This implicit Q-learning system, by encapsulating a multi-step dynamic programming approach and integrating expectile regression, delivers competitive performance against the state-of-the-art, showcasing its potential in advancing offline RL applications across various domains.
By omitting the need for explicit constraints or sophisticated sampling techniques, IQL provides a streamlined solution to offline RL challenges, poised for adoption in scenarios where scalable, robust approximations of value functions are essential.