- The paper provides a unified theoretical analysis of AdaQL and AdaMB, delivering regret guarantees via the zooming dimension approach.
- It introduces data-driven hierarchical partitioning that adapts discretization granularity, resulting in exponential improvements over traditional methods.
- Empirical validation on synthetic controls confirms that the adaptive methods reduce storage and computational overhead in RL tasks.
Adaptive Discretization in Online Reinforcement Learning
Reinforcement learning (RL) has become a critical framework for developing data-driven decision-making systems. As compute resources and data availability continue to grow, there is an increasing need for efficient algorithms that can harness the inherent structure of complex domains. This paper, "Adaptive Discretization in Online Reinforcement Learning" (2110.15843), provides a theoretically-grounded approach to adaptive discretization in online RL, addressing key challenges in designing algorithms that adapt to the geometric structure of the problem space. The proposed algorithms, AdaQL and AdaMB, exploit data-driven hierarchical partitioning, offering substantial improvements in sample complexity while maintaining low storage and computational overhead.
The paper tackles the intrinsic difficulties associated with discretization in RL, emphasizing two persistent issues: determining the discretization granularity and identifying optimal instances for refinement. Previous approaches predominantly explore heuristic solutions, yet this work delivers a comprehensive theoretical analysis of tree-based adaptive methods, applicable to both model-free and model-based scenarios. Through leveraging problem-specific geometric structures—quantified by the "zooming dimension"—the authors establish guarantees that scale more favorably than traditional assumptions reliant on ambient dimensions.
Zooming Dimension: This concept, originally appearing in bandit settings, is a central component of this work. It measures the complexity of RL problems in terms of state-action subsets that possess near-optimal properties. Instead of scaling directly with the ambient dimension, the paper demonstrates how adaptive algorithms exhibit improved performance by focusing on covering these lower-dimensional sets within the entire space.
Major Contributions
The key contributions of this paper include:
- Unified Theoretical Analysis: AdaMB and AdaQL algorithms are comprehensively analyzed, providing regret guarantees in terms of the zooming dimension, leading to exponential improvements over existing bounds by scaling exponentially with the problem's zooming dimension rather than its ambient dimension.
- Algorithmic Flexibility: By requiring only mild local assumptions on process metrics, the approaches can adapt gracefully to local adjustments, sidestepping extensive parametric modeling challenges.
- Empirical Validation: The algorithms are empirically validated through synthetic control tasks, showcasing their efficiency and adaptability in terms of regret, time complexity, and space complexity metrics.
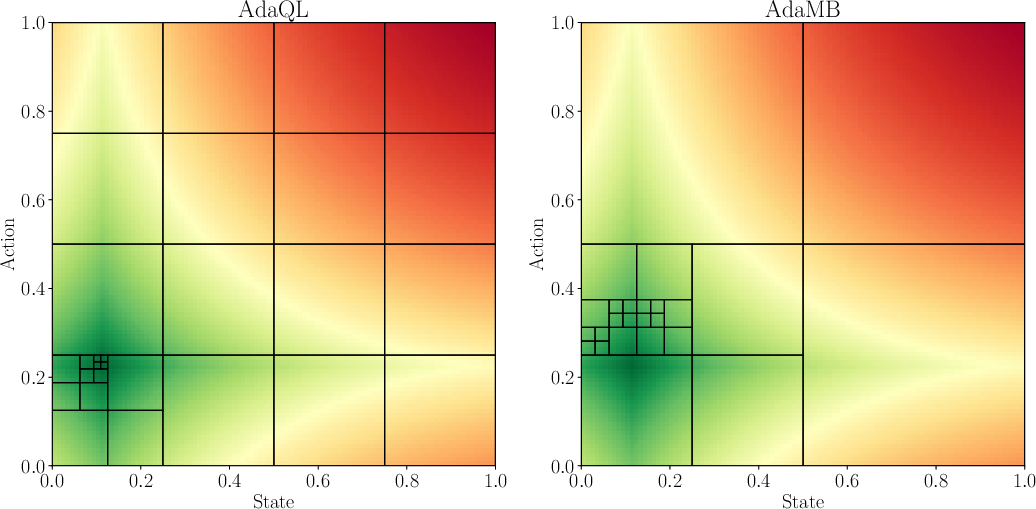
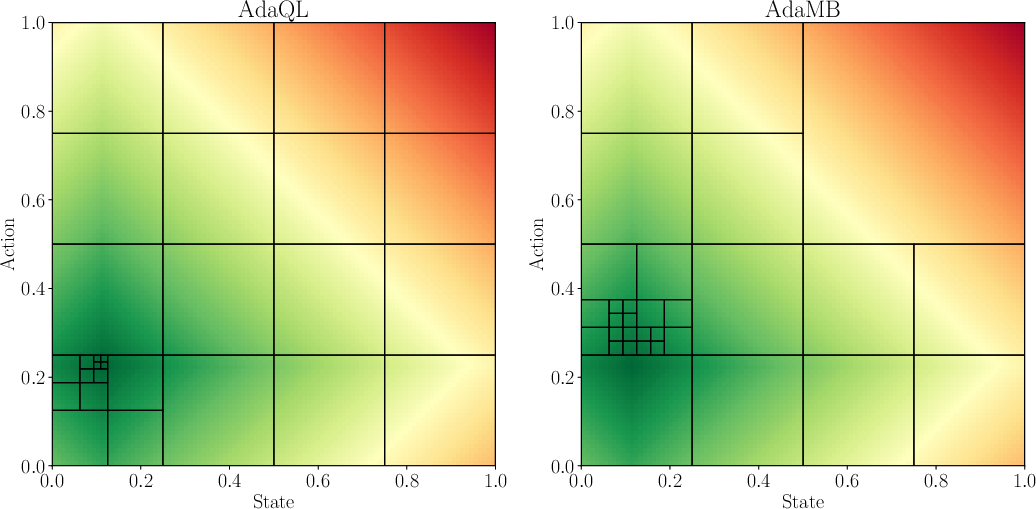
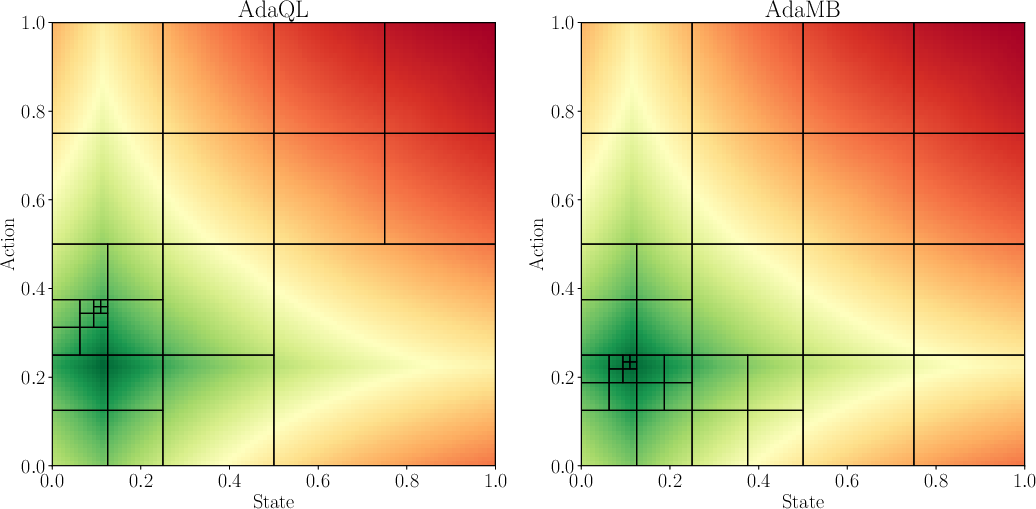
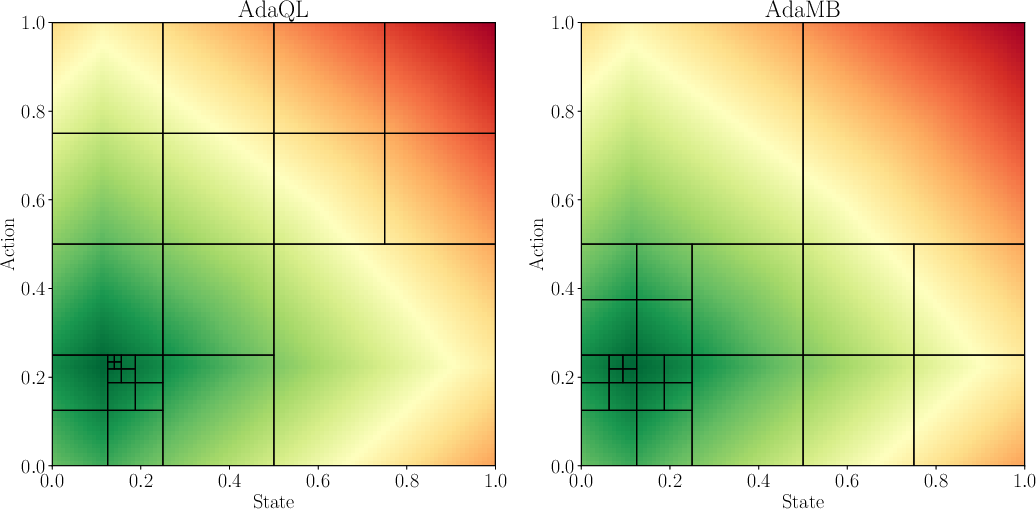
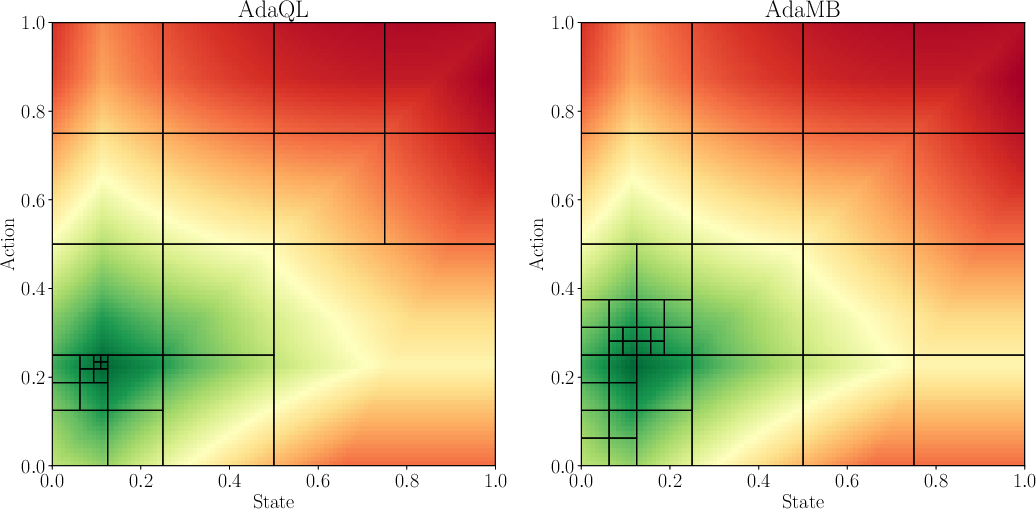
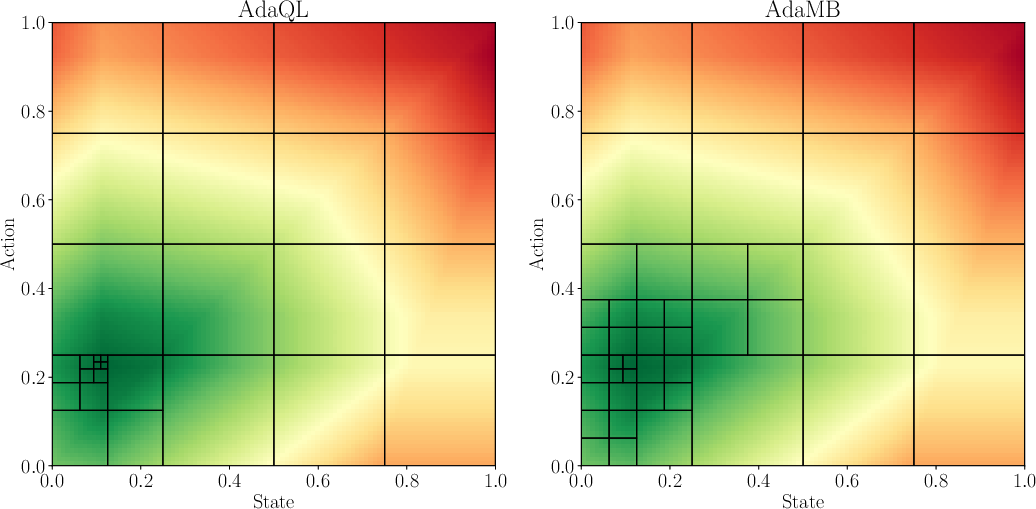
Figure 1: Comparison of the discretization observed between AdaMB and AdaQL for the oil environment with d = 1 at step h = 2. The underlying colors correspond to the true Q_2\star function where green corresponds to a higher value. In all of the results similar patterns were observed validating the adaptive discretization approach.
Practical and Theoretical Implications
The proposed algorithms not only achieve strong theoretical bounds but also demonstrate practical applicability, particularly suited for domains constrained by computational burden and storage requirements. As many modern RL applications, including resource allocation and memory management systems, demand lightweight controllers, AdaMB and AdaQL present viable solutions that balance computational efficiency and algorithmic robustness. The theoretical insight into zooming dimension represents a significant advancement, offering a refined perspective on RL problem complexity traditionally overlooked by ambient dimension metrics.
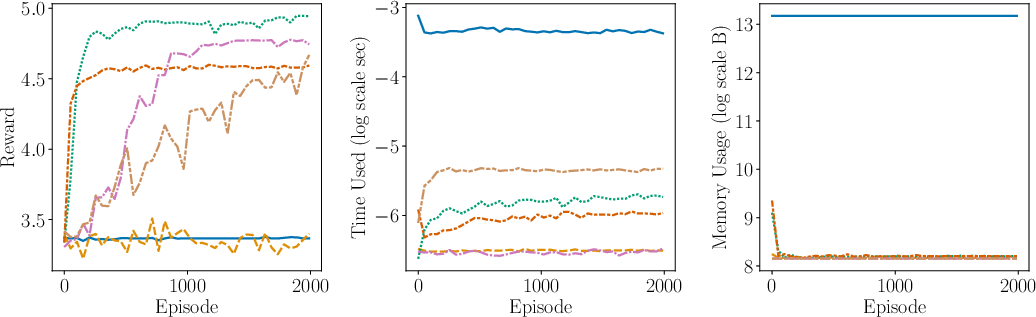
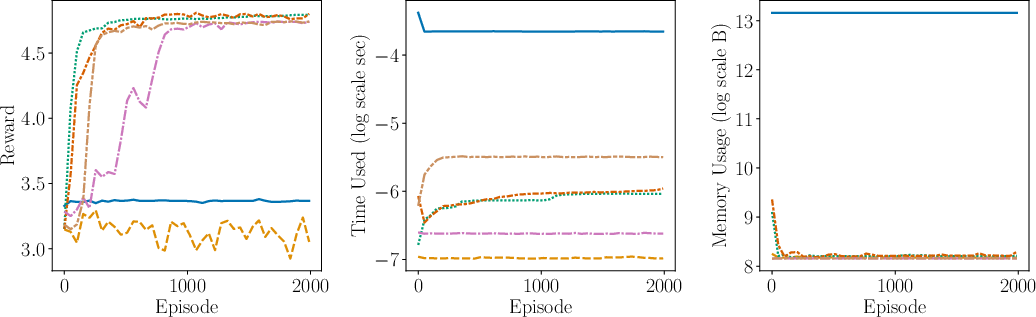
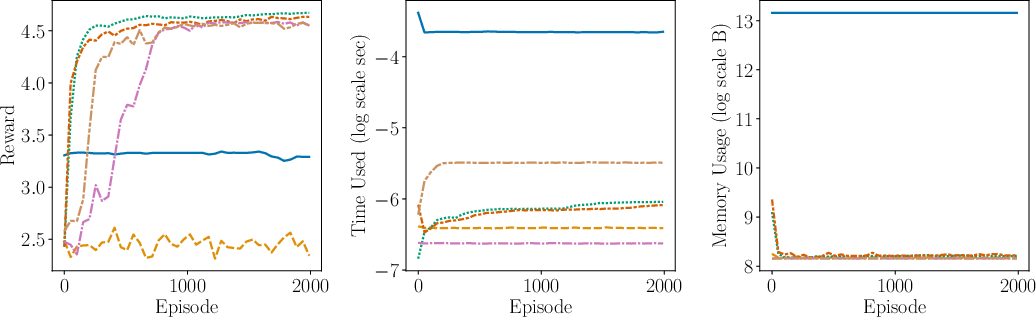
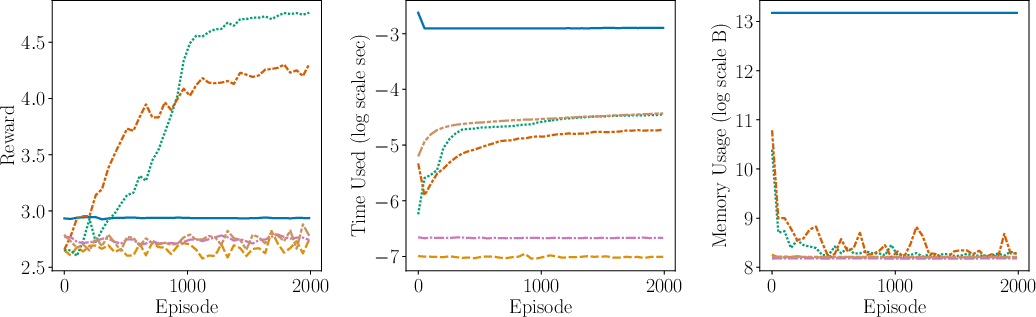
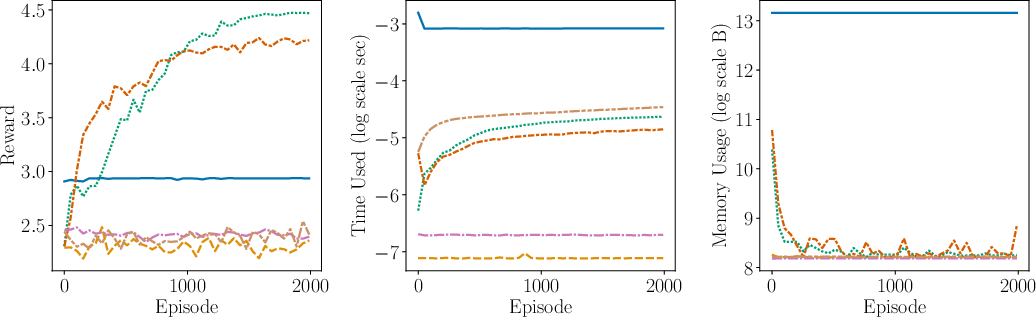
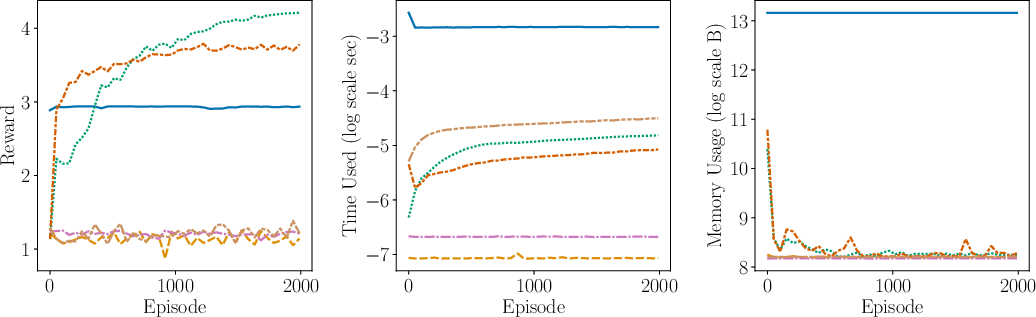

Figure 2: Comparison of the performance (including average reward, time complexity, space complexity) between AdaMB, AdaQL, EpsMB, EpsQL, Random, and SB PPO for the oil environment with Laplace rewards. We see that adaptive discretization algorithms outperform their uniform discretization counterparts, showcasing superior adaptability and efficiency.
Future Directions
This work opens several avenues for future research, particularly in refining concentration bounds for transition distributions and exploring non-parametric methods in greater depth. Further investigations into the optimal space and time complexity constraints, possibly accelerated by hardware advancements, remain critical. Additionally, leveraging insights into zooming dimensions to enhance metric space modeling would be invaluable for extending adaptive discretization algorithms to more complex RL settings.
Conclusion
"Adaptive Discretization in Online Reinforcement Learning" provides a significant contribution to RL research, articulating novel algorithms that elegantly balance adaptability and efficiency. By bridging theoretical analysis with practical implementation, the paper establishes a foundation for superior RL solutions grounded in problem-specific geometry—a perspective long essential for navigating the increasingly varied landscapes of RL applications. The implications for operations research and computing systems are profound, with potential for substantial improvements in both theoretical guarantees and empirical performance.
