- The paper introduces a lightweight late interaction mechanism that leverages residual compression and denoised supervision to reduce the token-level storage footprint.
- It employs BERT-based dual encoding with a MaxSim operator to compute token similarities, significantly enhancing retrieval accuracy.
- Evaluations on MS MARCO and diverse benchmarks demonstrate improved MRR@10 and robust zero-shot performance across both in-domain and out-of-domain tasks.
ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction
Introduction
ColBERTv2 presents a sophisticated approach in the domain of neural information retrieval, advancing the state-of-the-art by leveraging lightweight late interaction coupled with residual compression and denoised supervision. This paper focuses on overcoming the substantial space footprint associated with token-level decomposition in late interaction models by introducing an efficient compression mechanism. The model improves retrieval effectiveness within and outside the training domain, supported by comprehensive evaluations on a diverse set of benchmarks.
The proliferation of neural information retrieval models has highlighted various architectural paradigms, including single-vector and late interaction models. ColBERTv2 builds upon the latter, initially introduced by the original ColBERT model, which utilizes a multi-vector representation at the token level to enhance retrieval accuracy through a token-specific similarity scoring mechanism. However, this approach traditionally requires significant storage resources.
Previous advancements in neural IR have explored multiple directions to enhance retrieval quality and efficiency. These include vector compression techniques, such as product quantization, and various strategies to improve single-vector models' effectiveness through enhanced supervision methods. ColBERTv2 differentiates itself by combining advanced residual compression to reduce footprint and novel denoised supervision, aligning with the evolving needs in IR.
Methodology
Late Interaction and Modeling
ColBERTv2 utilizes BERT for dual-encoding of queries and passages, followed by a projection to a lower-dimensional space suitable for late interaction. The retrieval process involves multi-vector similarity computation via a "MaxSim" operator, which aggregates the maximum cosine similarities between tokens of queries and passages.
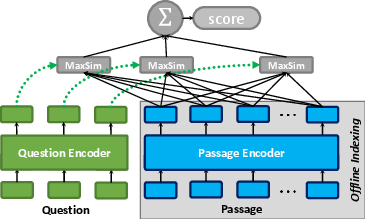
Figure 1: The late interaction architecture, given a query and a passage.
Supervision and Representation
A crucial advancement in ColBERTv2 is the introduction of denoised supervision, combining hard-negative mining and cross-encoder distillation, thereby enhancing the robustness and effectiveness of token-level modeling. Concomitantly, the model leverages residual compression, significantly reducing storage requirements by encoding token vectors into centroids and approximate residuals.
Indexing and Candidate Retrieval
The indexing phase involves clustering token embeddings into centroids, followed by residual encoding of passage vectors. During retrieval, ColBERTv2 efficiently generates candidates by leveraging centroid proximity and compressed vector representations, enabling high recall rates with reduced computational overhead.
Evaluation
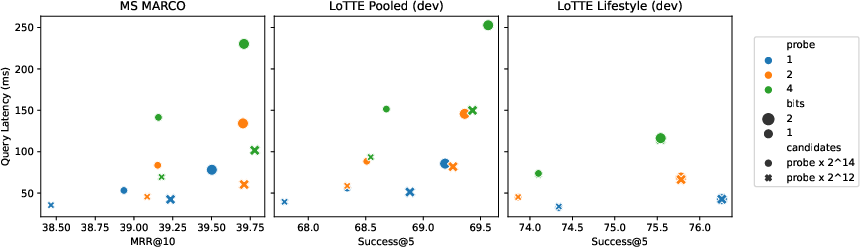
ColBERTv2's performance is rigorously evaluated on both in-domain (MS MARCO) and out-of-domain (BEIR, Wikipedia Open QA, LoTTE) benchmarks, consistently demonstrating superior retrieval quality.
Conclusion
ColBERTv2 represents a significant step in advancing neural retrieval models, achieving an optimal balance of quality and efficiency. Its design principles, emphasizing late interaction and efficient representation, have broad implications for future research in IR and beyond. The introduction of datasets like LoTTE also enriches the understanding of model performance across diverse and challenging retrieval tasks.
Further exploration can integrate more sophisticated compression techniques and refined training paradigms, propelling models like ColBERTv2 towards even broader real-world applicability and efficacy.