- The paper introduces PTR-PPO, which significantly enhances PPO performance by integrating prioritized trajectory replay.
- It employs three distinct trajectory priority metrics to effectively handle sparse rewards and improve data utilization.
- The approach maintains learning stability by using truncated importance weights and a parallel learner-actor structure.
Proximal Policy Optimization with Prioritized Trajectory Replay
Introduction
The paper proposes an enhancement to the Proximal Policy Optimization (PPO) algorithm by integrating a Prioritized Trajectory Replay (PTR) mechanism. This combination, referred to as PTR-PPO, is designed to increase sample efficiency, especially addressing the limitations of on-policy DRL methods which typically struggle with data utilization. By leveraging prioritized trajectory replay from old policies, PTR-PPO aims to improve the learning speed and performance of PPO.
Trajectory Priority Design
Three distinct trajectory priority metrics are introduced:
- Max Trajectory Priority: This metric is based on the maximum factor of the one-step experience Generalized Advantage Estimation (GAE) deviation. The intention is to prioritize those trajectories that have the most significant deviations, indicating areas that might benefit the most from learning.
- Mean Trajectory Priority: Here, the metric averages the GAE deviations across trajectories. This approach balances the focus, ensuring that all significant experiences are considered, not just the outliers with the largest deviations.
- Reward Trajectory Priority: This metric uses the normalized undiscounted cumulative reward to prioritize trajectories. It particularly addresses environments with sparse reward signals, prioritizing trajectories that achieve substantial undiscounted cumulative rewards over time.
These metrics are calculated and used to sample trajectories differently, aiming for enhanced efficiency in training the learning agent.
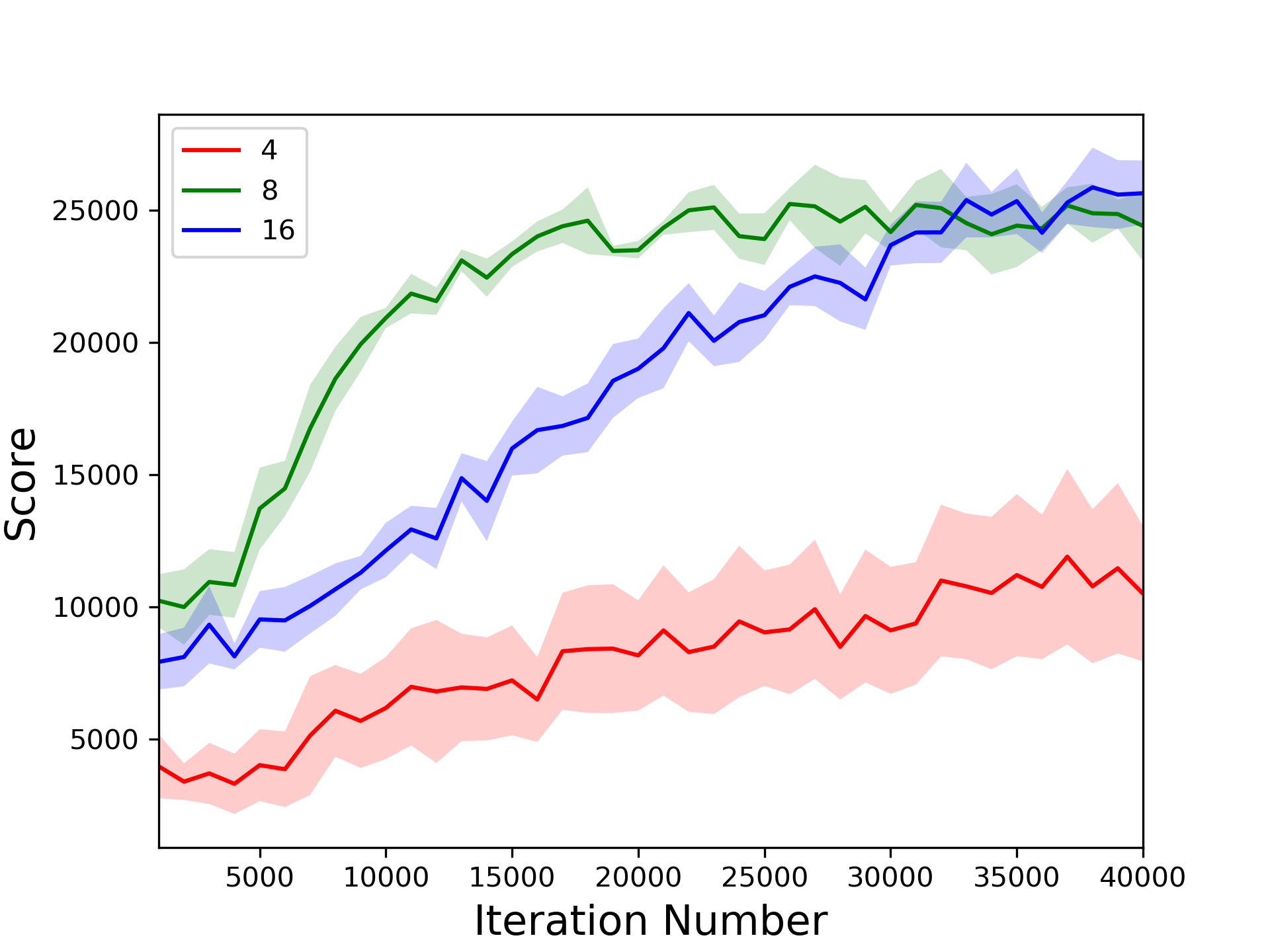
Figure 1: Trajectory priority based on one-step experience GAE deviation. The one-step empirical advantage deviation for each experience in the trajectory is calculated using GAE and the appropriate value is obtained as the trajectory priority using the max and mean operators.
PTR-PPO Algorithm Design
The architecture of PTR-PPO maintains a learner-actor structure, where multiple environments are simulated in parallel. Each trajectory's priority is calculated and stored in a priority memory using a sumtree. Trajectories are then sampled based on their calculated priorities to train the PPO loss function more effectively. Importantly, PTR-PPO introduces truncated importance weights to mitigate the high variance often seen in multistep experience settings. This truncation ensures learning stability by bounding importance weights, maintaining the balance between bias and variance.
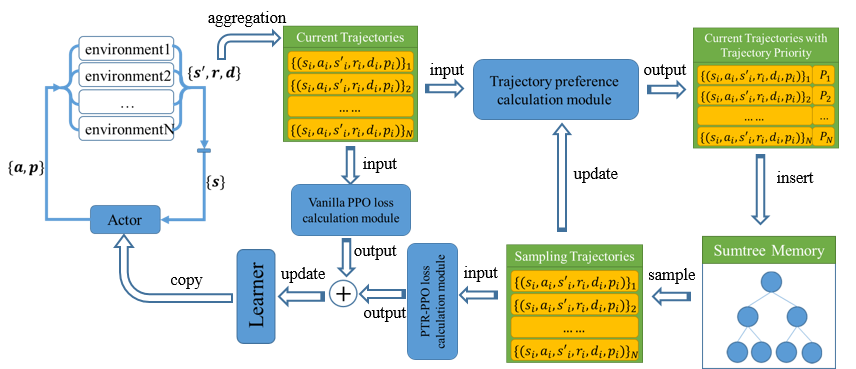
Figure 2: PTR-PPO Algorithm Architecture. The architecture uses a learner-actor design for improved training efficiency.
Experimental Results
The PTR-PPO algorithm was tested against established algorithms like PPO and ACER on a suite of Atari games, showcasing superior performance, particularly in environments with reward sparsity. In five out of the six environments tested, PTR-PPO demonstrated a clear advantage over the baseline methods in terms of final score. The results emphasized the efficacy of prioritized trajectory replay in improving sample efficiency and overall learning outcomes.
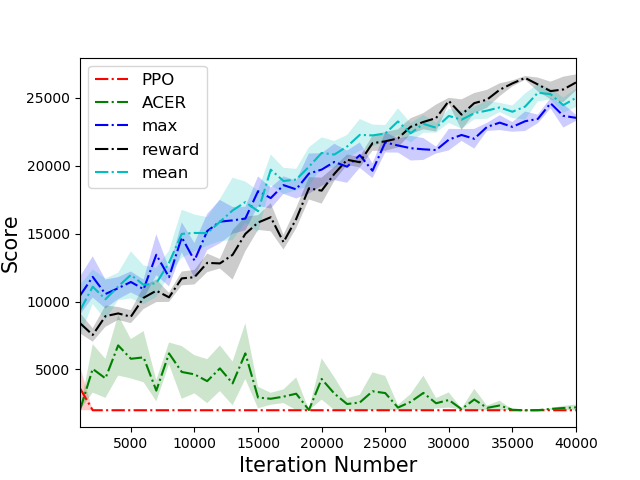
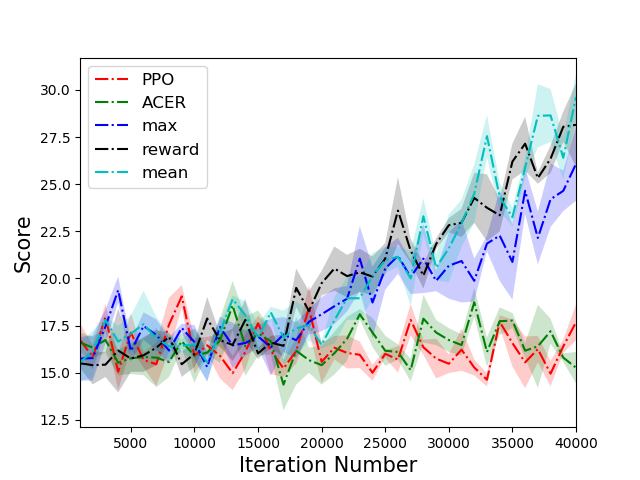
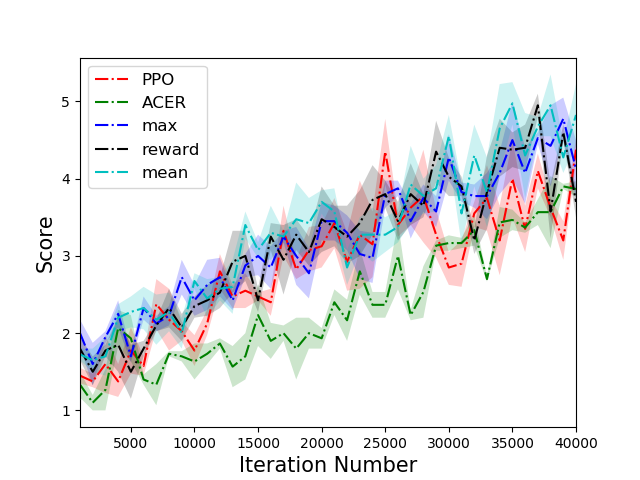
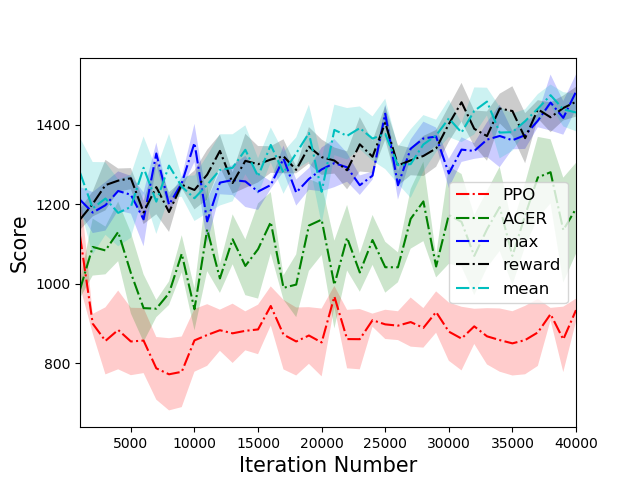
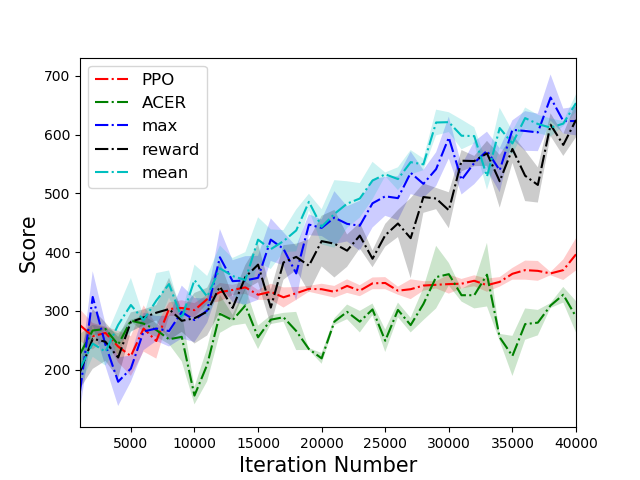
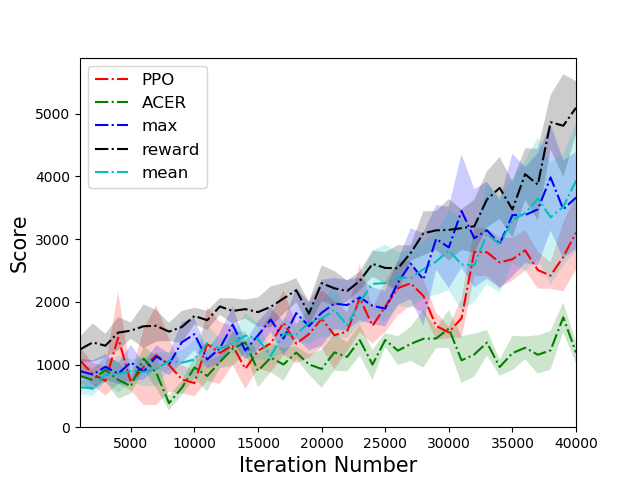
Figure 3: Comparison of scores of different algorithms on 6 tasks. PTR-PPO significantly outperforms PPO and ACER in five environments.
In terms of computational efficiency, the time analysis revealed that PTR-PPO's wall-clock-time efficiency is similar to PPO and superior to ACER. This efficiency is largely due to PTR-PPO's streamlined trajectory sampling and learning approach, which avoids the extensive processing times associated with other methods.
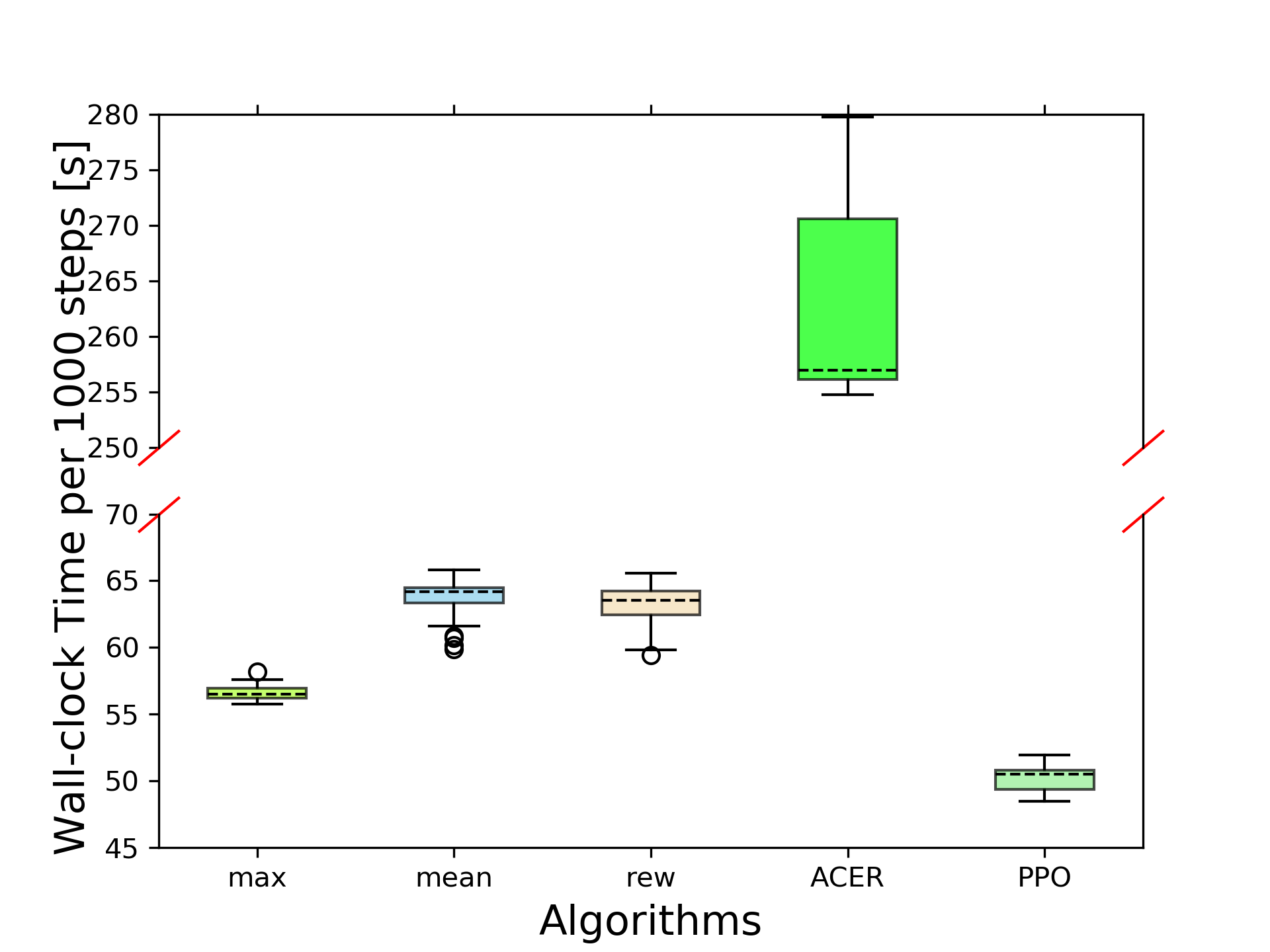
Figure 4: Algorithm comparison in terms of time efficiency on the Atlantis-v0 benchmark.
Implementation Considerations
Computational Requirements
The PTR-PPO algorithm requires a computational setup capable of supporting extensive parallel environment simulations due to its learner-actor architecture. Efficient memory management is critical, particularly for maintaining the priority memory where large amounts of trajectory data and their respective priorities are stored and updated.
Hyperparameters
Key hyperparameters include:
- Priority memory size: A balance is essential here; too small a memory could limit exposure to diverse trajectories, while too large may dilute the impact of recent high-priority trajectories.
- Trajectory rollout length: Impacts the stability and accuracy of GAE calculations. The paper finds 8-step rollouts typically optimal, balancing bias-variance trade-offs effectively.
Conclusion
PTR-PPO represents a significant optimization of the PPO framework, bringing enhanced efficiency through prioritized trajectory replay. This method stands to improve the learning pace and performance in various challenging RL environments, as demonstrated in Atari benchmarks. Future directions might explore dynamic adaptions of priority metrics to further optimize learning trajectories as training progresses. The integration with adaptive trajectory management systems holds potential for further enhancing sample efficiency in DRL applications.