- The paper introduces an end-to-end framework that integrates event and frame features to recover sharp images from videos with unknown exposure times.
- The approach utilizes a dynamic feature fusion module with Exposure Time-based Event Selection, achieving up to 6.40 dB PSNR improvement over prior methods.
- The paper demonstrates state-of-the-art performance on both synthetic and real-world datasets, effectively restoring intricate textures under severe motion blur.
Event-guided Deblurring of Unknown Exposure Time Videos
Introduction
The problem of motion deblurring involves recovering sharp images from motion-blurred frames, which arises due to the integration of scene information over time during camera exposure. Traditional methods, especially those leveraging deep learning (DL), have largely assumed fixed exposure times, leading to limitations in real-world scenarios where exposure times can vary dynamically depending on environmental conditions such as lighting. This paper addresses the gap by introducing a novel framework for event-guided motion deblurring, which operates under the assumption of dynamically variable and unknown exposure times.
Methodology
The primary contribution of the paper is the development of an end-to-end learning framework tailored to handle motion deblurring, leveraging the high temporal resolution of event cameras. The framework introduces an Exposure Time-based Event Selection (ETES) module to efficiently utilize event features by estimating their correlation with blurred frame features.
The key components of the proposed method include:
- Event Selection: Unlike prior methods assuming a fixed relationship between exposure time and video frame rate, the paper addresses the problem by estimating temporal correlations to infer exposure phases. The goal is to filter and employ events strictly corresponding to unknown exposure durations.
- Feature Fusion Module: A novel fusion mechanism is proposed to integrate selected event features with frame features, utilizing dynamic convolutions to enhance feature representations. This approach exploits the complementary nature of texture details present in frames and motion cues captured by events.
- Dataset Generation: A new dataset is created using real-world events captured with DAVIS-346 cameras, simulating varying exposure times to train and validate the model, thereby enhancing its adaptability in realistic environments.
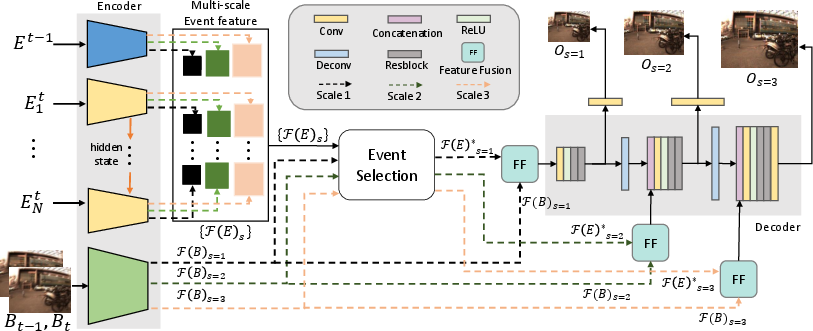
Figure 1: Overview of the proposed framework. For the encoder, blue, yellow, and green boxes represent an event encoder for the past part, a shared RNN-based event encoder for the current part, and a blur-frame encoder, respectively.
Experimental Results
The proposed method was extensively evaluated on both synthetic and real-world datasets, demonstrating superior performance in comparison to both existing frame-based and event-guided deblurring methods. The approach achieves state-of-the-art results across various benchmarks, marked by significant improvements in PSNR and SSIM metrics.
- Synthetic Datasets: The method shows a substantial performance leap over prior models, particularly in challenging scenarios with extreme motion blur. The average improvement in PSNR ranges from 1.66 dB to 6.40 dB against other event-guided techniques.
- Real-world Datasets: On datasets specifically collected for this study, the framework outperforms existing methods by a substantial margin, showcasing its robustness to unsteady motion and varying exposure times. Notably, the proposed method restores fine details in heavily blurred images where others fail.
- Qualitative Evaluation: The paper provides qualitative comparisons indicating the model's capacity to restore intricate textures and edges, even under severe non-linear motion conditions.

Figure 2: Visual comparison on the test split of real-world event datasets.
Implications and Future Work
The implications of this research are profound, as it sets a new baseline for motion deblurring in realistic settings where traditional assumptions about exposure times do not hold. Practically, this could enhance various applications ranging from video restoration to real-time processing in autonomous systems.
Theoretically, this work opens avenues for further exploration into cross-modal learning frameworks that adapt dynamically to temporal variations inherent in real-world environments. Future work could explore optimizing computational efficiency and exploring more complex modalities or combinations of sensory inputs to further improve deblurring performance.
Conclusion
The study proposes a cutting-edge approach to motion deblurring, leveraging the capabilities of event cameras to cope with unknown and dynamically varying exposure times. By addressing a critical limitation in traditional deblurring methods, the paper not only enhances performance but also broadens the applicability of DL-based solutions in practical, dynamic environments.