- The paper introduces QuALITY, a dataset that evaluates question answering on long passages, requiring comprehensive reading rather than skimming.
- It details a rigorous crowdsourcing and dual-validation process that yields challenging questions, with nearly half labeled as QUALITY-HARD.
- Baseline models like Longformer and RoBERTa achieve only 55.4% accuracy compared to 93.5% humans, highlighting the need for improved long-context strategies.
QuALITY: Question Answering with Long Input Texts, Yes!
The paper "QuALITY: Question Answering with Long Input Texts, Yes!" introduces QuALITY, a dataset designed to test models on the comprehension of long-document inputs. This dataset primarily focuses on multiple-choice QA, utilizing English passages averaging around 5,000 tokens, far exceeding the input length current models typically handle. QuALITY aims to overcome the limitations of prior datasets that rely heavily on short contexts and skimming techniques for answering questions.
Data Collection Methodology
The construction of QuALITY involves a meticulous crowdsourcing process ensuring questions require comprehensive passage understanding. The pipeline mandates that writers read entire passages before crafting questions, which are subsequently validated both with timed (speed validation) and untimed methods.
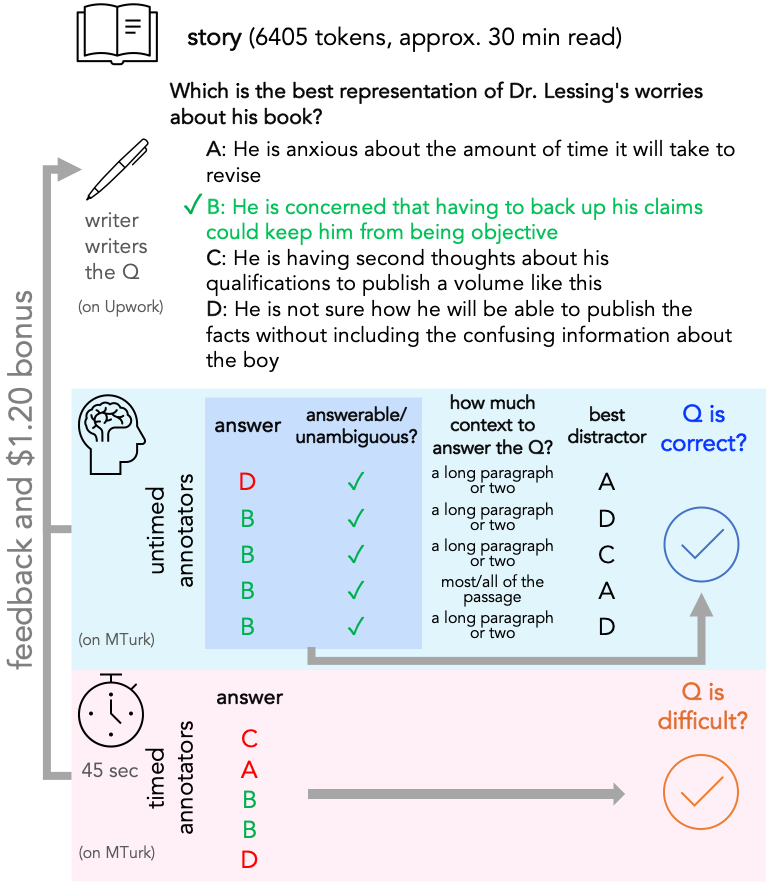
Figure 1: The crowdsourcing pipeline with an example validating question difficulty based on annotators' performance.
This dual-validation, costing approximately $9.10 per question due to its complexity, identifies challenging questions that cannot be easily answered through keyword search or skimming, thus forming the QUALITY-HARD subset.
Dataset Characteristics
QuALITY's dataset composes 6,737 questions, with 49.9% classified under QUALITY-HARD. The dataset sources include CC-BY licensed long texts from Project Gutenberg, Slate articles, and other nonfiction pieces, ensuring a diversity in passage topics and complexity.
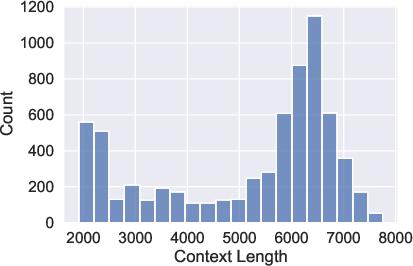
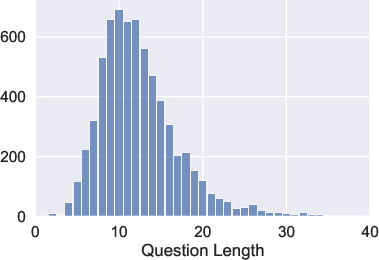
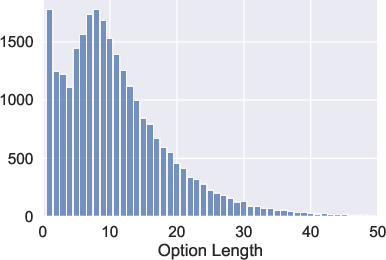
Figure 2: Article and question lengths highlight the extensive context provided for each question, necessitating deeper comprehension.
The average passage is significantly longer than any existing QA dataset, underscoring the challenge by rendering skimming ineffective, as evidenced by model performance metrics and the lexical analysis that confirms the inadequacy of simple lexical overlap strategies.
Baseline evaluations incorporate models such as Longformer, RoBERTa, and DeBERTaV3, with an emphasis on adapting encoding strategies to manage the extended input lengths. The methodology involved both full-context and extractive approaches, attempting to circumvent memory constraints by segment retrieval.
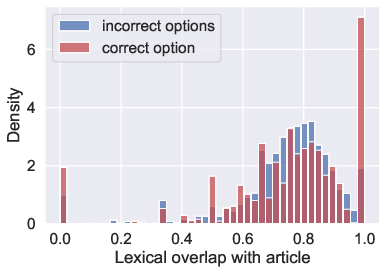
Figure 3: Lexical overlap among answer options with the article, indicating the insufficiency of term-based prediction methods.
Results reveal a stark gap between model and human performance, with the best model accuracy at 55.4% compared to human accuracy of 93.5%. The robustness of extractive methods, particularly those employing DPR for context selection, showcases a marginal performance edge, emphasizing the challenge of long-document comprehension.
Implications and Future Work
The introduction of QuALITY sets a new benchmark for long-document QA, with potential applications in domains requiring extensive comprehension, such as legal document review and educational assessments. The dataset paves the way for the development of more proficient models capable of handling voluminous inputs.
Future work may focus on enhancing model architectures to expand context window capabilities, alongside an exploration of alternative retrieval-augmentation techniques to improve extractive performance. Moreover, the dataset can be instrumental in fostering advancements in multi-step reasoning tasks and holistic document understanding.
Conclusion
QuALITY presents a pivotal resource in advancing NLP's capability in long-document question answering, addressing both foundational and immediate challenges in model scalability and comprehension depth. While current models lag considerably behind human performance, QuALITY offers a rigorous testbed for continuous improvements in natural language understanding systems.