- The paper introduces LaTr, a layout-aware transformer that integrates text and spatial layout cues to enhance scene-text VQA performance.
- It employs a novel 2-D spatial embedding mechanism and document-based pre-training to mitigate OCR errors and sparse text issues.
- Experimental results show improvements of +7.6% on TextVQA, +10.8% on ST-VQA, and +4.0% on OCR-VQA benchmarks.
LaTr: Layout-Aware Transformer for Scene-Text VQA
Introduction
The paper "LaTr: Layout-Aware Transformer for Scene-Text VQA" introduces LaTr, a Layout-Aware Transformer designed for Scene Text Visual Question Answering (STVQA). This task demands complex reasoning across multiple modalities such as text, spatial layout, and visual data. The paper explores the pivotal role of language and layout, demonstrating significant advantages in leveraging document-based pre-training for STVQA tasks.
 *Figure 1: The Role of Language and Layout in STVQA. *
*Figure 1: The Role of Language and Layout in STVQA. *
Methodology
Layout-Aware Architecture
LaTr employs a novel architecture by integrating a multimodal encoder-decoder transformer with spatial embeddings. The pre-training focuses solely on text and layout cues, effectively exploiting scanned documents to capture varied layout information. This approach circumvents the sparse text challenges observed in natural image datasets, facilitating improved spatial reasoning and semantic understanding.
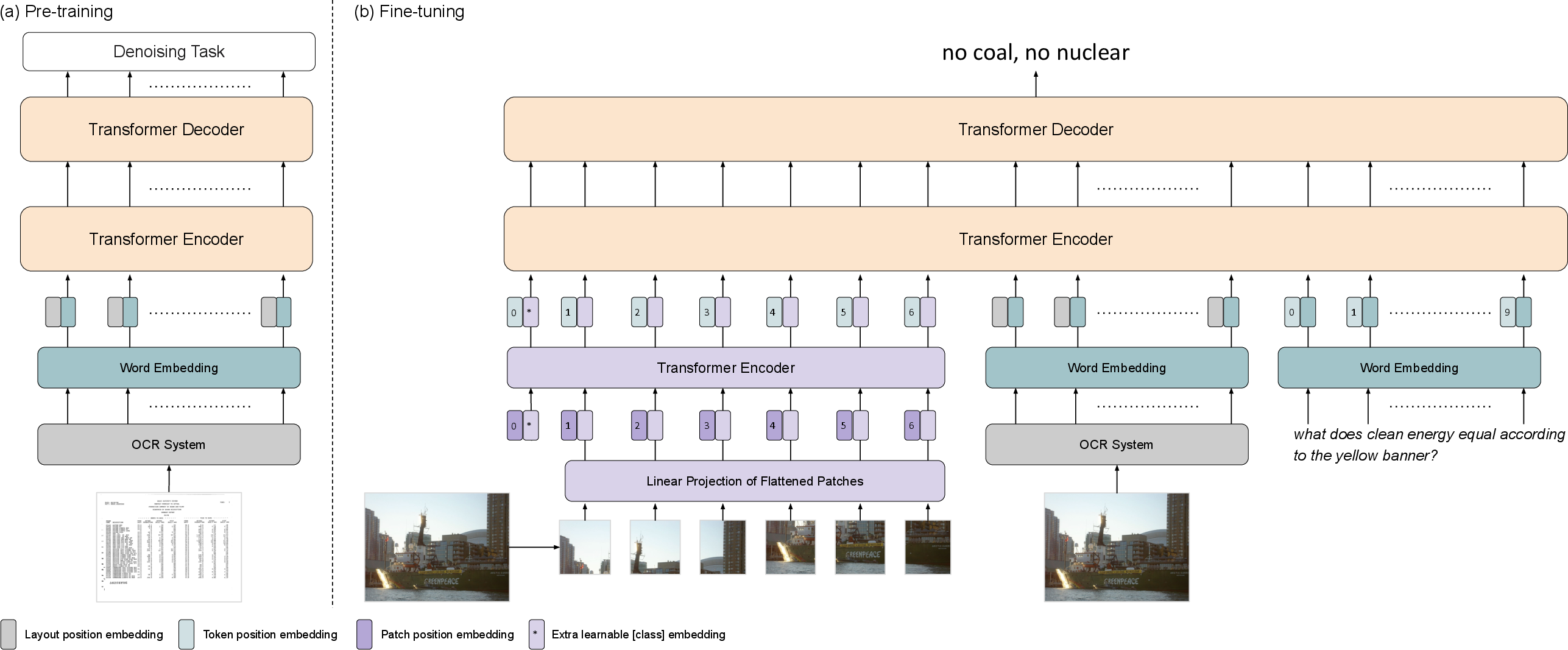
Figure 2: An overview of LaTr. (a) In pre-training, language modality with text and spatial cues are used to model interactions. (b) In fine-tuning, ViT visual features supplement the model.
Spatial Embedding Mechanism
The paper leverages 2-D position embeddings to enhance the semantic representation, drawing a parallel with document understanding tasks that benefit substantially from layout alignment. By encoding OCR tokens' bounding boxes as spatial embeddings, LaTr achieves superior spatial-contextual integration with text data.
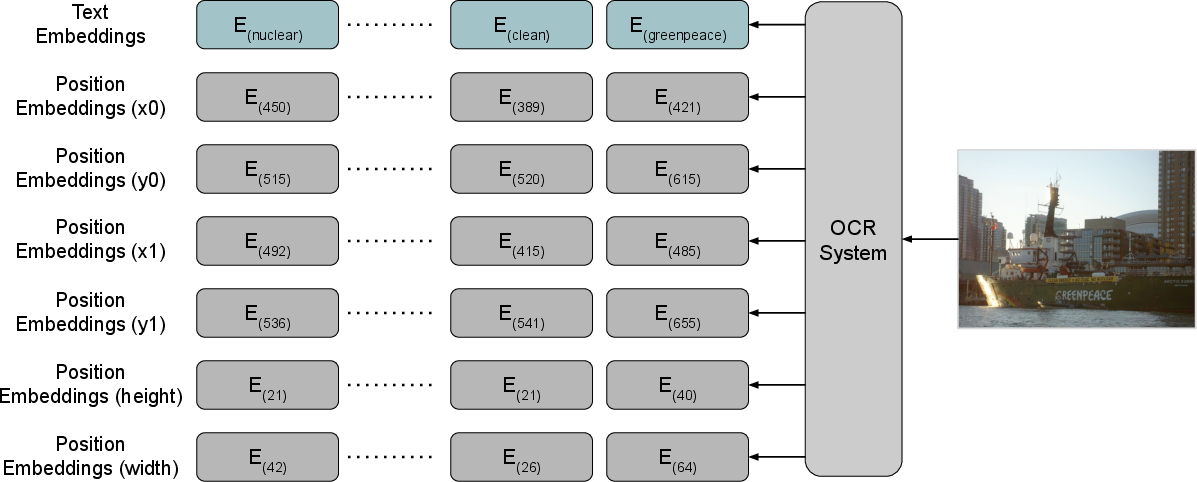
Figure 3: Layout Position Embedding, demonstrating how spatial embeddings enrich semantic representations.
Experimental Results
LaTr demonstrates outstanding performance across several benchmarks such as TextVQA, ST-VQA, and OCR-VQA, outperforming existing methods by significant margins (+7.6% on TextVQA, +10.8% on ST-VQA, and +4.0% on OCR-VQA). The architecture excels in scenarios with OCR errors, a common issue in STVQA tasks, due to its robust vocabulary-free decoding capability and document-derived pre-training.
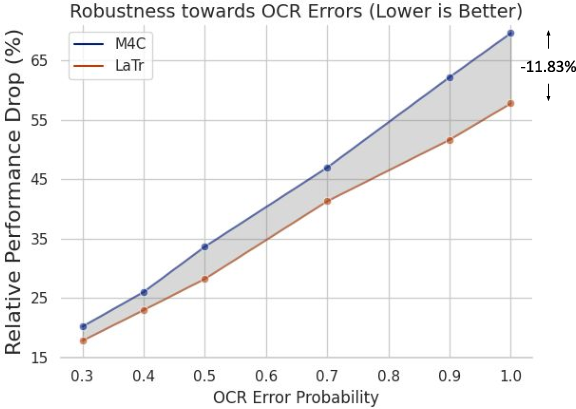
Figure 4: Robustness towards OCR Errors showcasing LaTr's resilience compared to existing methods.
Discussion and Implications
Language and Layout Bias in STVQA
A substantial portion of STVQA tasks can be tackled using only text and layout information, reflecting a dataset bias rather than inherent task complexity. This insight emphasizes the need for benchmarks that truly integrate visual features to evaluate models comprehensively across all modalities. The current data often exhibit biases, such as over-reliance on vocabulary, which LaTr addresses through its generative model and layout-aware design.

Figure 5: Dataset Bias or Task Definition illustrating different question types based on required information.
Future Prospects
The non-reliance on explicit visual data during pre-training provides avenues to scale using large document repositories. This methodology encourages leveraging abundant scanned documents for improved model pre-training, thereby strengthening spatial semantics without increased complexity.
Conclusion
The paper presents significant advancements in STVQA by focusing on the symbiotic relationship between language and layout within documents. The layout-aware transformer architecture positions LaTr as a formidable approach, offering state-of-the-art performance and setting a new precedence in multimodal reasoning tasks. The future direction should aim at recalibrating the STVQA benchmarks to ensure that visual features are indispensable, pushing the VQA field towards more balanced, comprehensive models.