- The paper presents a unified cross-modal pre-training approach that leverages code, comments, and AST to enhance both understanding and generation tasks.
- The paper introduces novel mapping functions and training objectives, including multi-modal contrastive learning and cross-modal generation, to effectively capture syntax and semantics.
- The paper achieves state-of-the-art results in clone detection, code search, summarization, and completion, demonstrating its practical impact on code intelligence applications.
Authoritative Summary of "UniXcoder: Unified Cross-Modal Pre-training for Code Representation"
Motivation and Background
Current pre-trained LLMs for source code are typically grouped into encoder-only, decoder-only, or encoder-decoder architectures. Encoder-only models (e.g., CodeBERT) excel at code understanding tasks but are sub-optimal for generation tasks, as the decoder component must be initialized independently. Decoder-only models (e.g., CodeGPT) are efficient in auto-regressive tasks such as code completion but lack bidirectional information critical for understanding. Unified encoder-decoder models (e.g., PLBART, CodeT5) offer broader coverage but do not fully exploit multi-modal code structures, notably neglecting abstract syntax trees (ASTs) and comments that are crucial for semantics and syntax.
UniXcoder addresses these deficits by introducing a unified cross-modal pre-training paradigm that leverages code, comments, and AST structures to achieve superior performance across understanding, generation, and auto-regressive tasks.
UniXcoder takes as input the triplet of source code, comment, and AST, concatenated with a mode-specific prefix token ([Enc], [Dec], [E2D]) that adapts the attention mask for encoder, decoder, or encoder-decoder operation. Importantly, the authors propose a one-to-one mapping function to flatten the tree-structured AST into a sequence that fully preserves structural information, facilitating efficient parallel encoding.
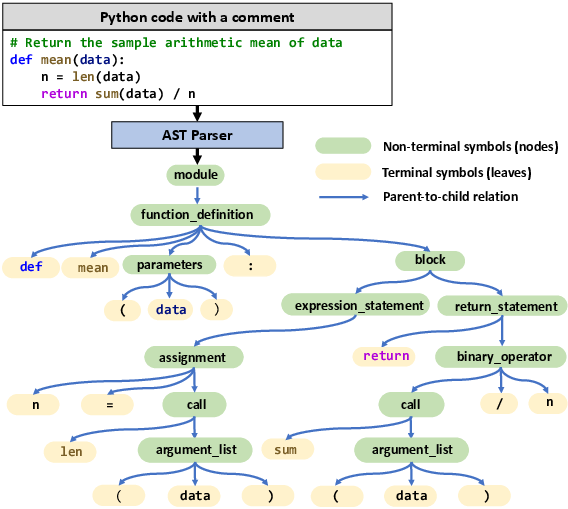
Figure 1: Visualization of a Python function, its associated comment, and the AST flattened via the proposed mapping function for transformer input.
This approach allows the model to ingest rich semantic cues from comments and precise syntactic hierarchies from ASTs, jointly with code tokens, enabling a powerful cross-modal representation.
Model Architecture and Training Objectives
UniXcoder utilizes a shared-parameter, multi-layer transformer, whose behavior is controlled via masked attention matrices and prefix adapters following (Dong et al., 2019). The architecture seamlessly switches between encoder-only, decoder-only, and encoder-decoder modes, covering both understanding and auto-regressive inference scenarios efficiently.
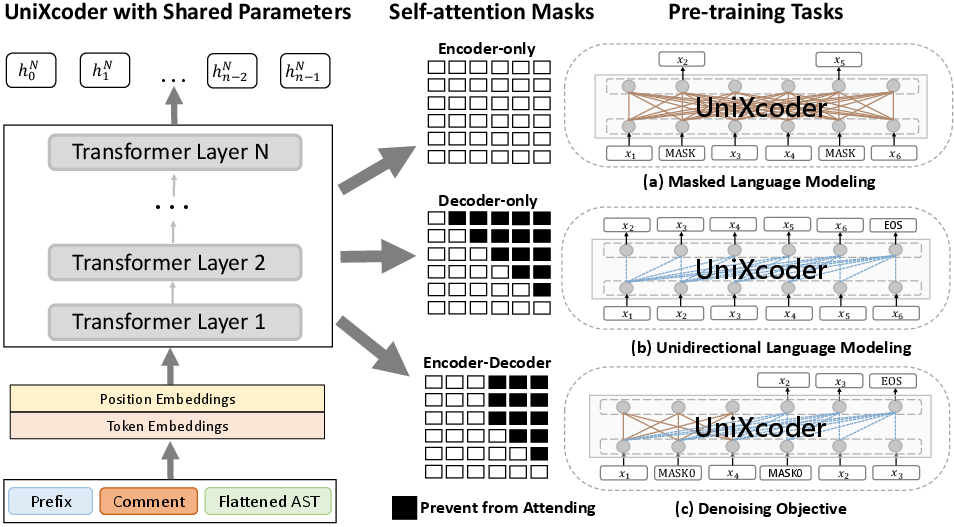
Figure 2: UniXcoder’s transformer architecture with modally organized input, mask-controlled attention, and prefix-driven behavioral adaptation.
Pre-training unifies three canonical objectives:
- Masked Language Modeling (MLM): Bidirectional context prediction for code and comment tokens, leveraging AST-derived syntax.
- Unidirectional Language Modeling (ULM): Left-to-right prediction for auto-regressive completion tasks.
- Denoising Objective: Span-based corruption and reconstruction akin to T5/BART for generation tasks.
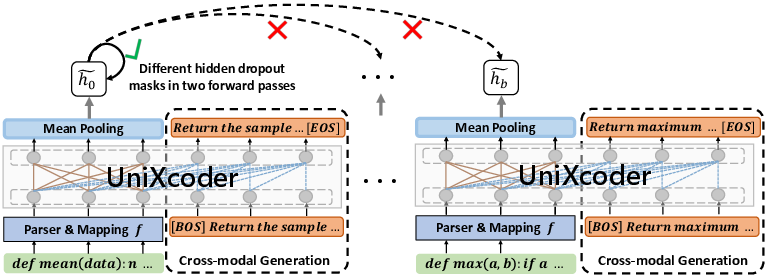
In addition, UniXcoder introduces two specialized objectives to enhance code fragment embedding:
Empirical Results and Analysis
UniXcoder is evaluated across five tasks: clone detection, code search, code summarization, code generation, and code completion, using nine datasets. Additionally, a novel zero-shot code-to-code search task is introduced, leveraging a large corpus from CodeNet.
Understanding and Generation Tasks
UniXcoder achieves state-of-the-art results in clone detection and code search across multiple datasets, outperforming other pre-trained models by notable margins. On generation tasks, such as code summarization and generation, UniXcoder matches or slightly surpasses competitive baselines, especially when normalized for model size and dataset composition.
Code Completion
For line-level code completion, UniXcoder demonstrates superior exact-match and edit-similarity scores over decoder-only and unified models, confirming its efficiency in real-time generation settings.
Zero-shot Code-to-Code Search
UniXcoder’s code fragment embeddings are validated by a zero-shot retrieval task across Ruby, Python, and Java, significantly outperforming prior models—indicating successful semantic alignment of code fragments across languages.
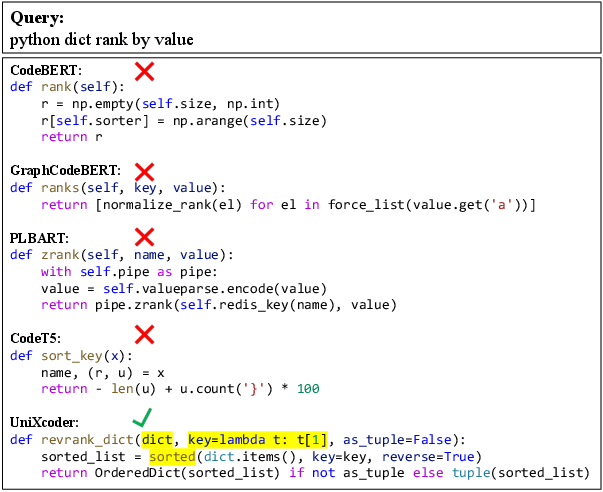
Figure 4: Example code search query on CosQA and comparison of model predictions, highlighting UniXcoder’s semantic retrieval prowess.

Figure 5: Example from zero-shot code-to-code search task showing identical-solution retrieval across Ruby, Python, and Java.
Ablation Studies
Systematic ablation confirms that both comment and AST inputs are critical to performance, with the mapping function for AST flattening outperforming conventional BFS/DFS traversals, as these latter methods do not guarantee structural preservation.
Contrastive and cross-modal generation objectives are shown to boost both understanding and generation results, with contrastive learning being particularly decisive in zero-shot cross-lingual retrieval scenarios.
Implications, Limitations, and Future Directions
The results provide strong empirical evidence for embracing multi-modal cross-modal representations in code intelligence models. The explicit structural encoding of AST, combined with semantic cues from comments, facilitates a unified embedding space that successfully traverses the gap between code understanding and generation.
Practical implications include improved IDE code completion, semantic code search, robust cross-language code retrieval, and enhanced downstream NLP-code hybrid tasks. Theoretically, UniXcoder’s architecture and training protocol serve as a template for future cross-modal representation learning, potentially extending to other structured domains.
Future research avenues include scaling UniXcoder to larger corpora, incorporating additional modalities (e.g., data flow graphs, execution traces), exploring transfer learning across domain-specific languages, and refining cross-modal alignment techniques for further empirical and theoretical gains.
Conclusion
UniXcoder advances unified code representation by integrating multi-modal pre-training over code, comments, and AST, validated by superior performance on understanding, generation, and zero-shot retrieval tasks (2203.03850). Its architecture and objectives demonstrate effective cross-modal alignment and semantic embedding, establishing a robust foundation for follow-up research in code intelligence and cross-lingual code-centric applications.