- The paper introduces BERTopic, which integrates SBERT-based embeddings with a novel class-based TF-IDF to enhance topic coherence and distinction.
- It employs UMAP for dimensionality reduction and HDBSCAN for clustering, resulting in superior performance on diverse datasets compared to classical topic models.
- The model supports dynamic topic modeling by recalibrating term frequencies over time, enabling real-time analysis of evolving textual data.
BERTopic: Neural Topic Modeling with a Class-Based TF-IDF Procedure
This essay presents a detailed exploration of the "BERTopic: Neural topic modeling with a class-based TF-IDF procedure" (2203.05794), focusing on its methodology, implementation, and implications within the domain of topic modeling using neural embeddings.
Introduction to BERTopic
BERTopic introduces an innovative approach to topic modeling that addresses inherent limitations in classical methods such as LDA and NMF by integrating neural embeddings and a class-based TF-IDF procedure. This model capitalizes on the semantic richness of pre-trained transformer-based embeddings, allowing for more coherent topic representation. By leveraging Sentence-BERT (SBERT) for document embeddings and employing a class-based TF-IDF, BERTopic enhances topic coherence and diversity across various datasets.
Methodology
Document Embeddings
BERTopic utilizes SBERT to convert documents into dense vector representations, optimizing clustering by facilitating semantic comparisons in vector space. This approach assumes semantic similarity among documents sharing the same topic, thus enhancing clustering reliability as embedding techniques evolve.
Document Clustering
To handle high-dimensional embedding spaces and optimize clustering, BERTopic employs UMAP for dimensionality reduction followed by HDBSCAN for clustering. UMAP effectively preserves local and global structures, crucial for maintaining topical integrity, while HDBSCAN accommodates varying density clusters, essential for distinguishing noise from meaningful clusters.
Topic Representation
The heart of BERTopic is its class-based TF-IDF, which redefines traditional TF-IDF to measure word importance in clusters rather than individual documents. By treating all documents in a cluster as a single entity, this variation identifies terms that differentiate one cluster from another, ensuring coherent and distinct topic representation.
Dynamic Topic Modeling
BERTopic extends its capabilities to dynamic topic modeling, maintaining a global topic representation while allowing for temporal variation in local representations. This is achieved by recalculating term frequencies at different time points against a static IDF, permitting temporal analysis without re-embedding documents.
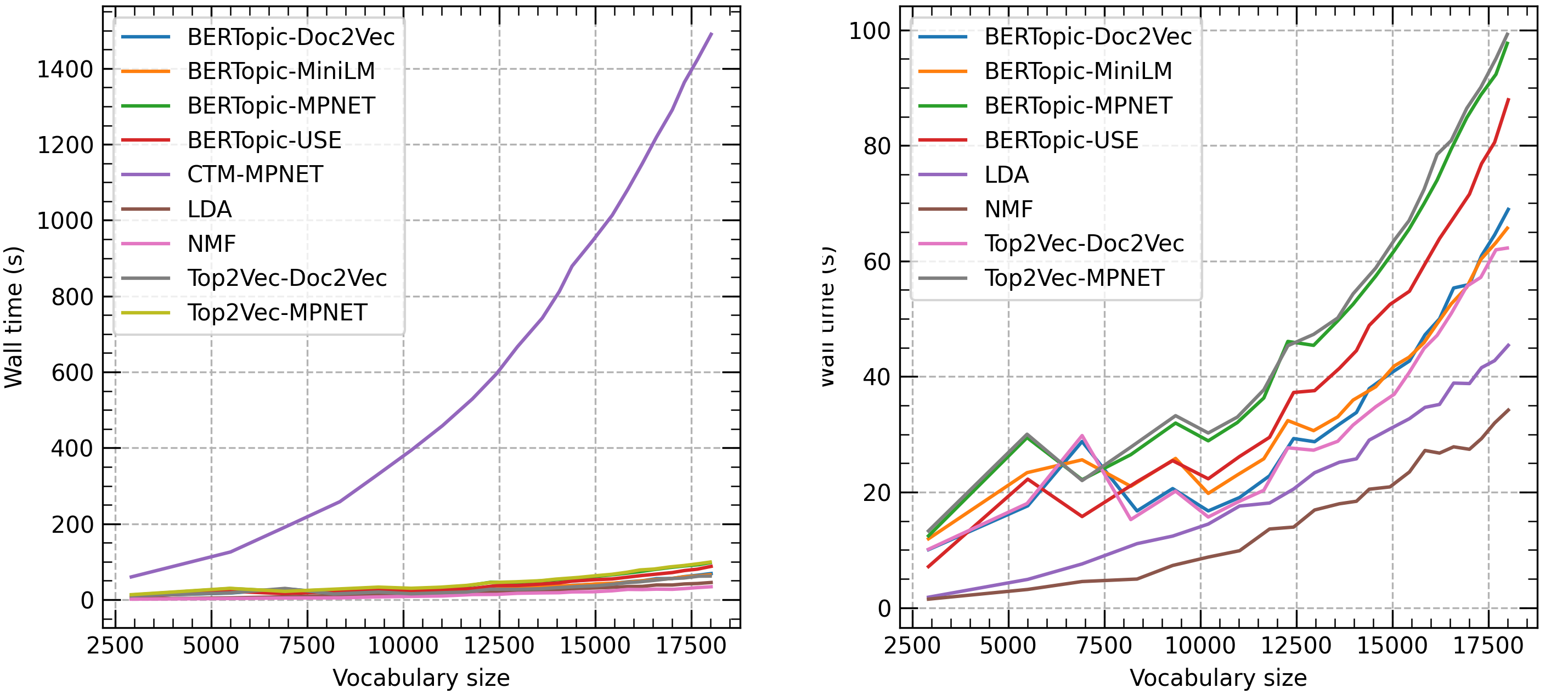
Figure 1: Computation time (wall time) in seconds of each topic model on the Trump dataset. Increasing sizes of vocabularies were regulated through selection of documents ranging from 1000 documents until 43000 documents with steps of 2000.
BERTopic demonstrates robust performance across diverse datasets such as 20 NewsGroups, BBC News, and Trump's tweets. It consistently delivers high topic coherence and diversity scores, particularly excelling on datasets with minimal preprocessing. However, it faces competition from CTM, which occasionally surpasses it in topic diversity.
BERTopic's adaptability is mirrored in its consistent performance irrespective of the LLM used, with the "all-MiniLM-L6-v2" model offering a particularly balanced trade-off between competitive performance and computational efficiency. The model's dynamic topic modeling capabilities reveal its strength in temporal analysis, outperforming classical methods in scenarios with inherent temporal structures.
Implementation Considerations
Computational Requirements
BERTopic's reliance on pre-trained transformer embeddings necessitates significant computational resources, particularly when employing LLMs. The availability of a GPU significantly enhances embedding efficiency, which is integral for practical applications where rapid processing of extensive datasets is required.
Practical Implications
The model's flexibility, allowing separation of embedding processes and topic generation, facilitates its application across various domains. Its adaptability to improved LLMs posits BERTopic as a future-proof solution, potentially benefiting applications ranging from dynamic content analysis to real-time document clustering.
Conclusion
BERTopic advances topic modeling by effectively integrating neural embeddings with a novel TF-IDF variation to produce coherent and diverse topic representations. Through its flexible architecture and dynamic modeling capabilities, BERTopic offers a potent tool for uncovering latent themes in large-scale textual data, promising broad applicability and significant potential for further development in aligning with ongoing advancements in LLM technologies.