- The paper introduces the ViT U-Net architecture, combining nnU-Net with Vision Transformers to address continual learning challenges in hippocampus segmentation.
- The methodology employs sequential training using techniques such as Elastic Weight Consolidation and replay-based strategies to enhance forward and backward transfer.
- Experimental results demonstrate improved Dice scores and reduced forgetting, highlighting the effectiveness of the transformer integration in adaptive medical imaging.
The paper "Continual Hippocampus Segmentation with Transformers" explores the integration of Transformer architectures into medical image segmentation tasks, specifically focusing on continual learning scenarios within changing clinical settings. By leveraging the self-attention mechanism of Transformers, the study aims to mitigate catastrophic forgetting, a common issue when models are trained sequentially on evolving tasks without retaining past knowledge.
Implementation of ViT U-Net Architecture
Architecture Design
The proposed ViT U-Net architecture combines the nnU-Net framework with Vision Transformer (ViT) modules, integrating them between the encoding and decoding blocks of the U-Net. This hybrid architecture leverages skip connections from the nnU-Net to feed inputs into the ViT, capturing both high-level and low-level features through two variations of the ViT U-Net:
- High-level version (V1): Utilizes only the first skip connection for ViT input, focusing on high-level features.
- All-level version (V2): Incorporates both first and last skip connections combined via convolutional layers.
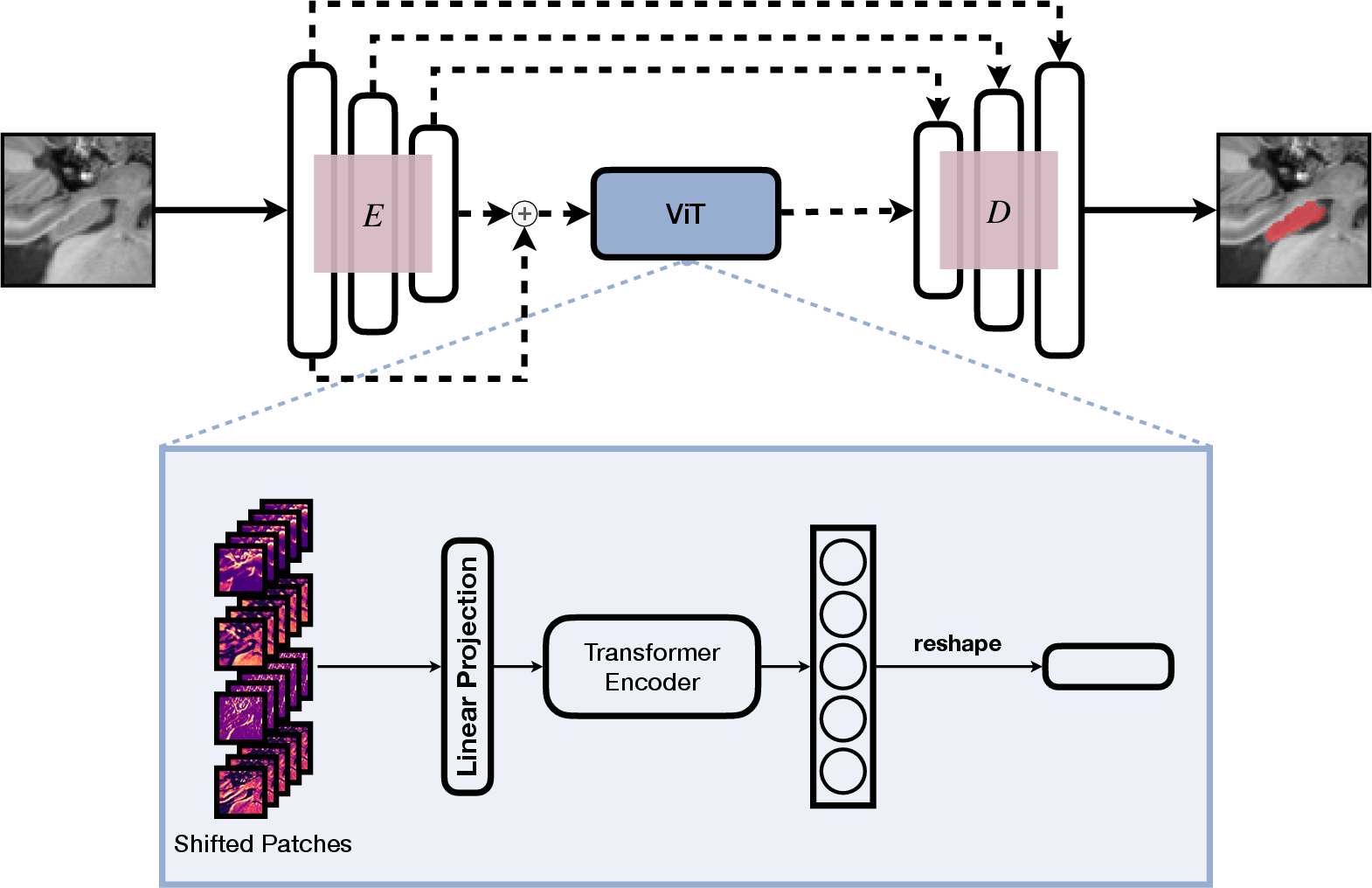
Figure 1: Composition of the nnU-Net and ViT, our proposed ViT U-Net V2. E indicates the encoding and D the decoding blocks of the nnU-Net.
Training Methodology
The models are trained sequentially on a hippocampus segmentation dataset, including T1-weighted MRI scans from various sources. The nnU-Net's pre-processing capabilities are employed to handle dimensionality issues inherent in medical imaging data. Specific continual learning (CL) methods, like Elastic Weight Consolidation (EWC) and replay-based strategies, are applied to evaluate the architecture's performance in retaining past task knowledge.
Role of ViT in Continual Learning
ViT Self-Attention Mechanism
The self-attention in ViT is pivotal for mitigating catastrophic forgetting. Regularizing Transformer components like ViT's attention blocks typically hampers their ability to maintain knowledge across tasks. The experiments demonstrate that ViT's inclusion in the nnU-Net framework notably enhances backward transfer (BWT) and forward transfer (FWT), signifying better knowledge retention and adaptation to new information.
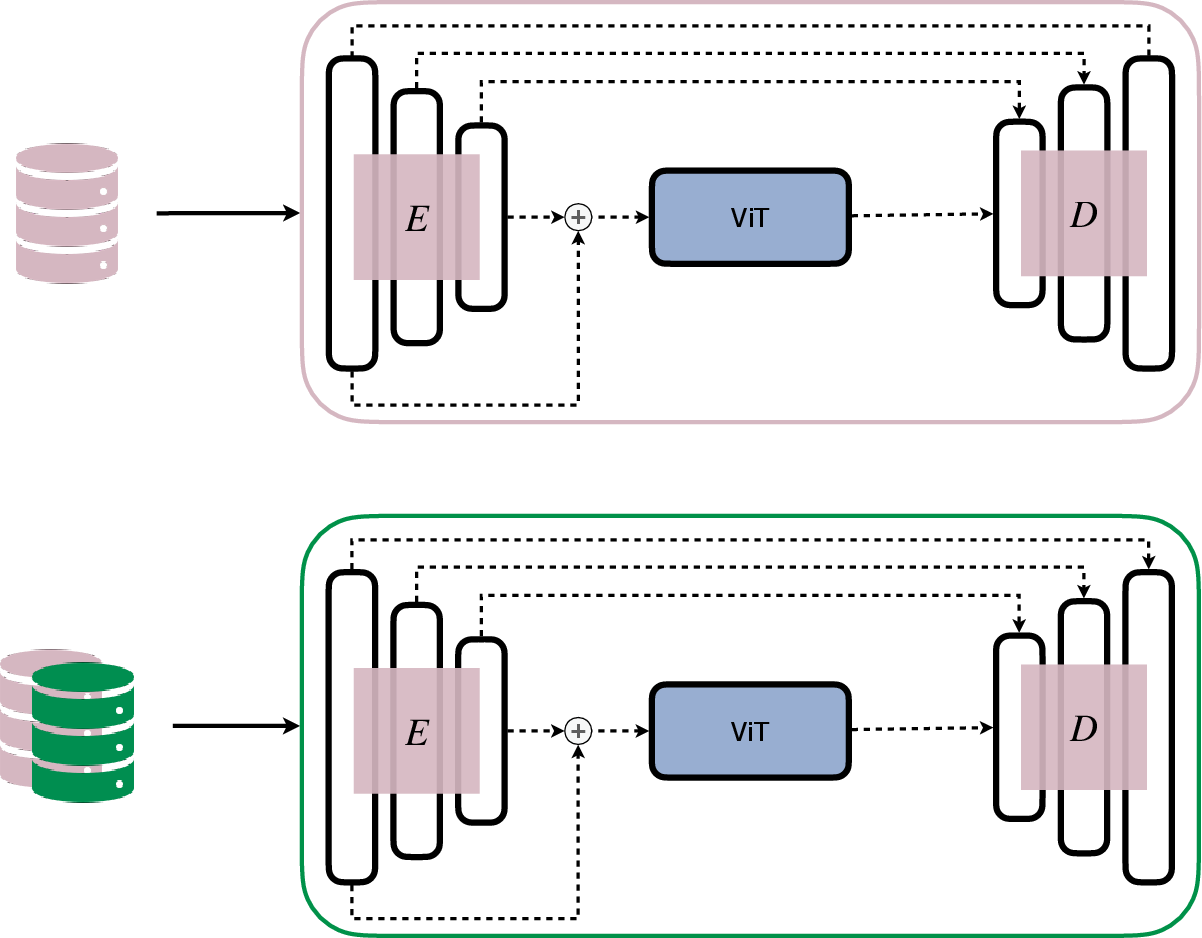
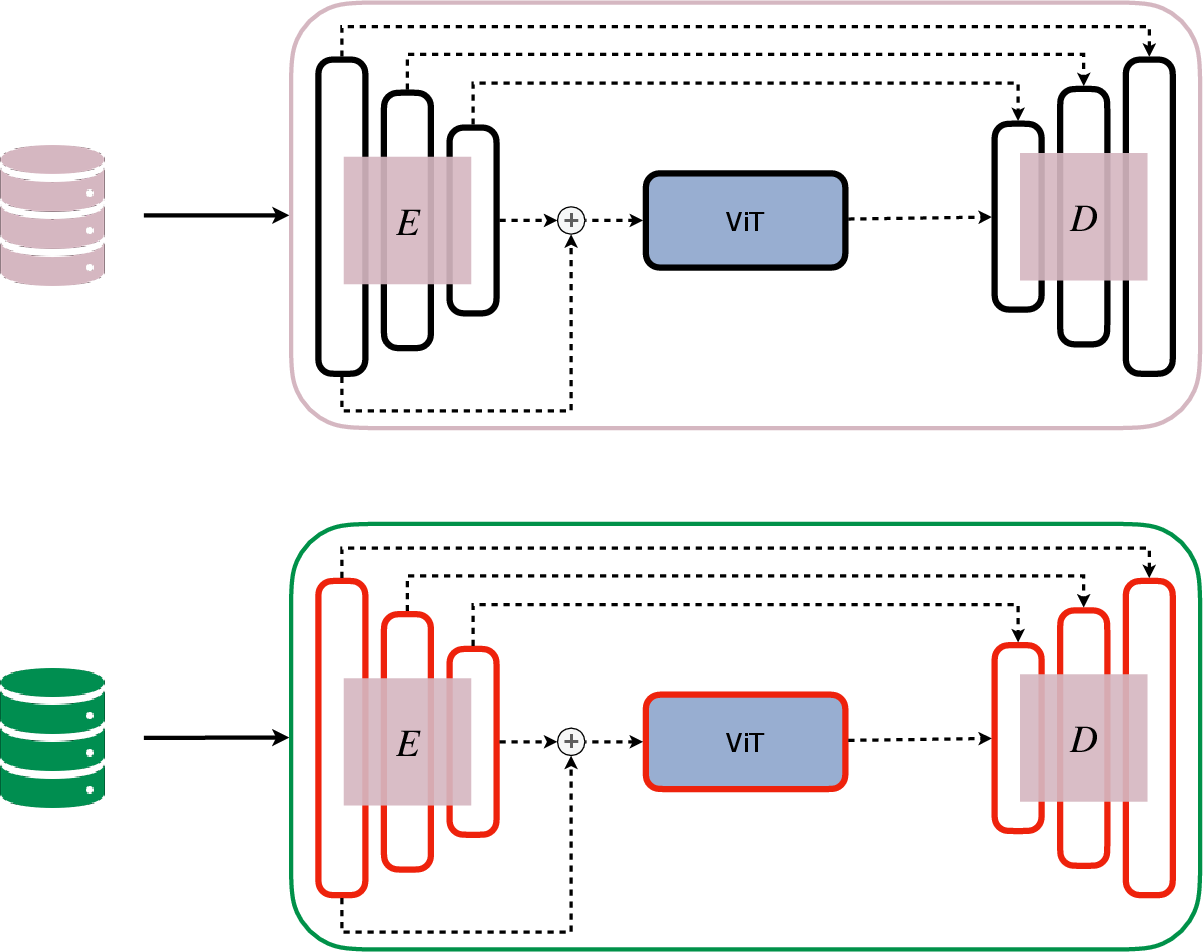
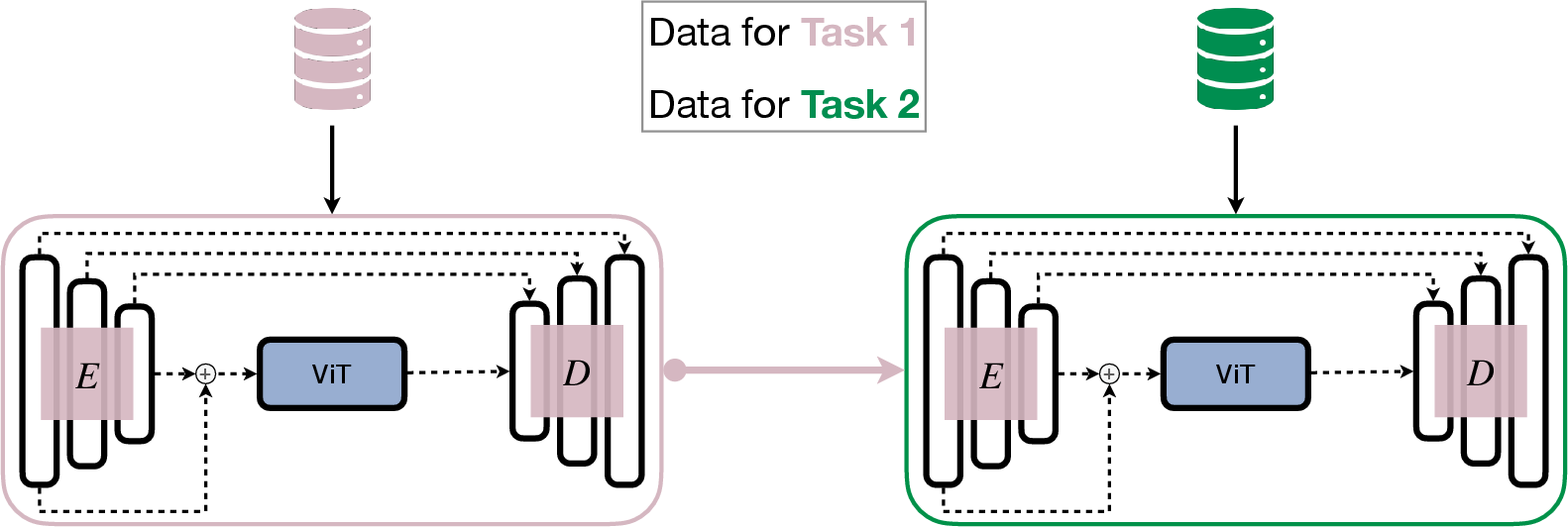
Figure 2: Replay-based approach.
Freezing Strategy and Regularization Analysis
Through experiments freezing either the nnU-Net or the ViT parts after specific tasks, it was observed that keeping the ViT unfrozen helps maintain more prior knowledge. Regularization applied only to specific network components, such as the nnU-Net, allows the model to retain past knowledge without sacrificing adaptability, further solidifying the ViT's role in enhancing CL performance.
The experiments delineate that ViT U-Net configurations excel over traditional nnU-Net frameworks in continual learning setups. Metrics like Dice scores, along with BWT and FWT, provide a quantitative assessment of the proposed architecture's effectiveness. The ViT U-Net, notably when utilizing Shifted Patch Tokenization (SPT) and Locality Self-Attention (LSA), achieves superior segmentation performance across different datasets.
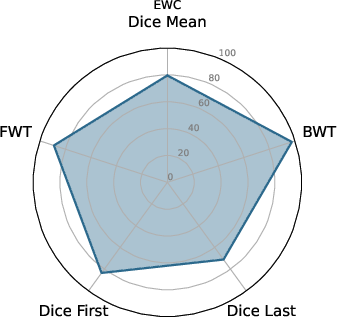
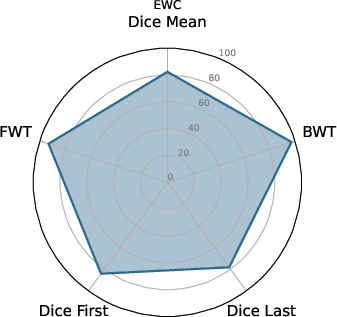
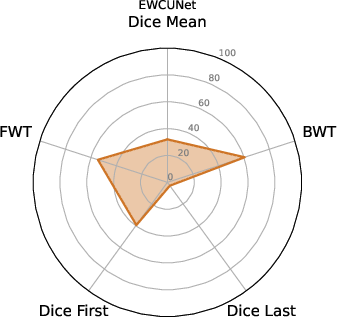
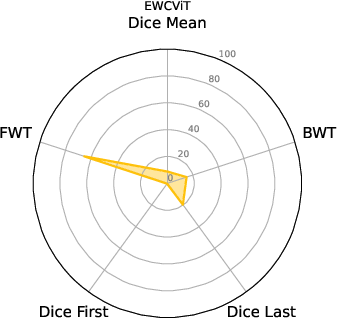
Figure 3: EWC nnU-Net.
BWT and FWT results denote that the ViT U-Net exhibits less catastrophic forgetting and better transfer learning capabilities compared to non-ViT architectures, making it a strong candidate for deployment in environments with dynamic data distributions.
Practical Implications and Future Directions
In clinical contexts, where privacy concerns and evolving imaging methodologies challenge traditional learning paradigms, the proposed ViT U-Net shows promise in maintaining robust performance without the need for vast datasets. Future exploration could focus on reducing the computational overhead of ViT modules and extending their application to other areas of medical imaging beyond hippocampus segmentation.
Conclusion
The integration of Vision Transformers within the U-Net framework for medical image segmentation sets a precedent for leveraging self-attention mechanisms to address catastrophic forgetting in CL scenarios. The ViT U-Net not only improves segmentation accuracy but also enhances knowledge retention across sequential tasks, marking a significant step forward in adaptive medical image processing technologies. These insights offer a foundation for future research leveraging Transformers in complex, task-evolving environments.