- The paper presents InfoPower, a method that integrates variational empowerment with mutual information maximization to enhance exploration in visual model-based RL.
- The approach leverages contrastive learning and a primal-dual optimization framework to robustly capture latent state representations and prioritize controllable factors.
- Experimental evaluations demonstrate that InfoPower outperforms state-of-the-art baselines in distractor-heavy settings by effectively filtering irrelevant information.
The paper presents InfoPower, an approach to model-based reinforcement learning (MBRL) that integrates variational empowerment with mutual information maximization to improve visual MBRL performance. The method explicitly prioritizes functionally relevant information, achieved through an empowerment-enhanced mutual information-based non-reconstructive framework. This novel objective enables efficient learning in environments with confounding distractions while enhancing exploration, especially under sparse reward conditions.
Model Architecture and Objectives
InfoPower distinguishes itself by incorporating empowerment into both representation and policy learning objectives. A contrastive learning approach captures latent state representations without reconstructing high-dimensional observations, ensuring robustness to irrelevant distractors. Empowerment prioritizes controllable factors, and the representation learning objective enforces this prioritization to learn latent state-space models effectively.
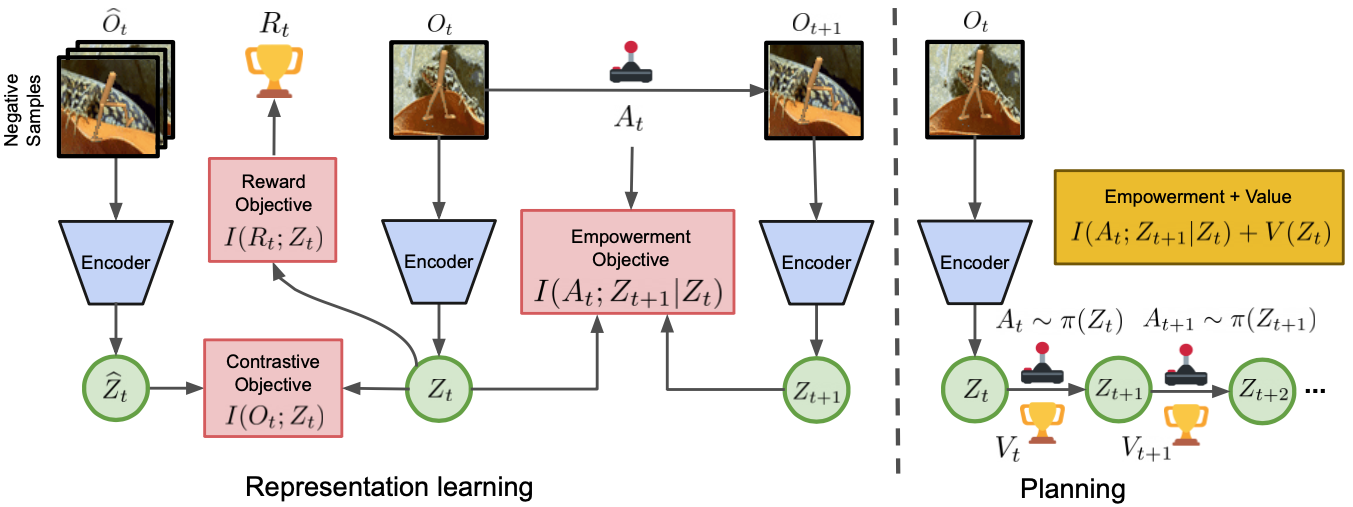
Figure 1: Overview of InfoPower. I(t;Zt) is the contrastive learning objective for learning an encoder to map from image .
Learning Controllable Factors: The empowerment term I(At−1;Zt∣Zt−1) serves as a crucial pillar, guiding the agent towards controllable state configurations. This term ensures that the representations Z prioritize actions with significant effects on future states, promoting exploratory behavior in sparsely rewarding environments.
Implementation Strategy
The implementation of InfoPower requires the optimization of several objectives using lower bounds to mutual information (MI). The core MI terms for contrastive learning are evaluated either through an InfoNCE or NWJ lower bound, favoring the NWJ due to its slight performance improvement in practice.
Primal-Dual Optimization
The constrained optimization captures a hierarchical learning structure where the MI between observations and latents is maximized, subject to constraints emphasizing controllability. The Lagrangian method optimizes primal and dual variables for efficient convergence:
1
2
3
4
5
6
|
initialize_parameters()
while not_converged:
update_primal_parameters()
update_dual_variables()
perform_policy_update()
interact_with_environment() |
Experimental Evaluation
InfoPower demonstrates exceptional performance when evaluated on deep reinforcement learning (RL) benchmarks with distraction-heavy environments, outperforming state-of-the-art baselines such as Dreamer, TIA, and others (Figure 2).
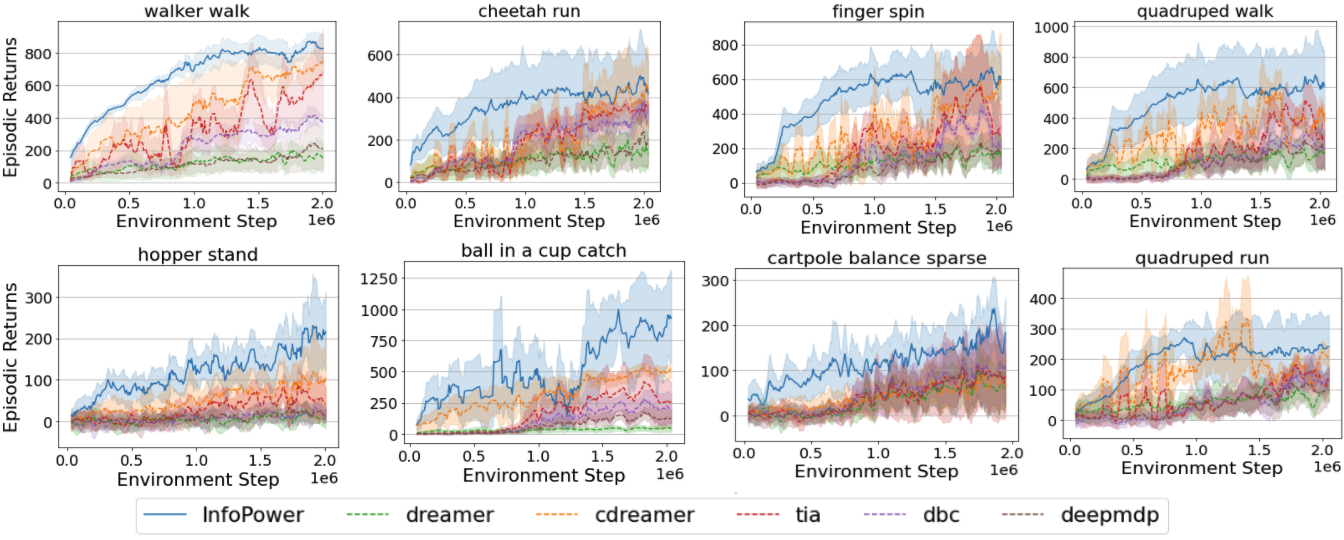
Figure 2: Evaluation of InfoPower and baselines in a suite of DeepMind Control tasks with natural video distractors in the background.
Behavioral Similarity and Exploration
The empirical validation includes measuring the behavioral similarity between learned latents and true simulator states using the proposed metric and t-SNE visualizations. InfoPower's latent representations highly correlated with true states, showcasing its effectiveness in retaining crucial task information while discarding irrelevant distractions.
Ablation Studies
Ablative analysis highlights the indispensable role of the empowerment objective across different stages of representation and policy learning. Variations excluding empowerment significantly reduce performance, particularly in initial training phases where exploration is critical (Figure 3).
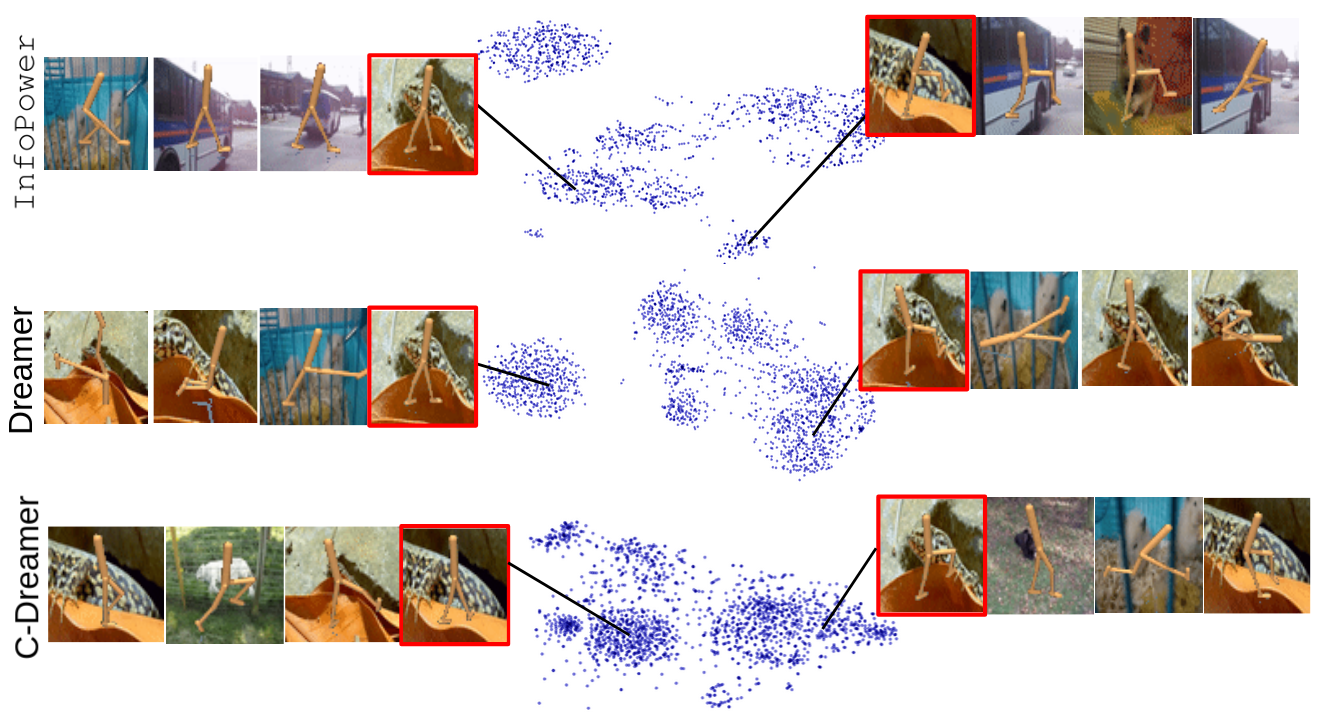
Figure 3: Evaluation of InfoPower and ablated variants in a suite of DeepMind Control tasks with natural video distractors in the background.
Conclusion
InfoPower is a promising approach in visual model-based reinforcement learning with intrinsic prioritization for functionally relevant information. Its empowerment-driven framework facilitates efficient exploration and exploitation in complex visual environments, achieving superior performance to existing RL methods under challenging distractor settings. The research indicates potential future applications in broader RL scenarios, where understanding and prioritizing relevant information can significantly impact the effectiveness of learned policies.