- The paper provides a global analysis of over 3500 performance results, identifying prevalent and ambiguous metric usage in NLP benchmarking.
- It employs hierarchical mapping and manual curation to reduce 812 metric strings to 187 canonical metrics, clarifying inconsistencies in reporting.
- The findings highlight the need for precise metric reporting and the integration of traditional and emerging metrics to enhance evaluation robustness.
Introduction
Over the past two decades, benchmarking in NLP has evolved significantly, with an expanded repertoire of metrics used to evaluate the performance of various models. While traditional metrics like BLEU and ROUGE were initially dominant, their limitations such as low correlation with human judgment and poor task transferability have driven the development of numerous alternatives. The study conducted by Blagec et al. provides a detailed cross-sectional analysis of metric usage in NLP, focusing on over 3500 performance results sourced from "Papers with Code." The insights reveal not only the prevalent metrics in current practice but also the inherent challenges in their usage and reporting.
Methodology
The analysis derives its dataset from "Papers with Code," utilizing ITO to organize 812 different metric strings reported across numerous benchmarks. A crucial step involved the hierarchical mapping and manual curation of these metrics into canonical forms, reducing them to 187 distinct performance metrics. This process addressed ambiguities and inconsistencies such as synonymous metric names and variants within the same metric family.
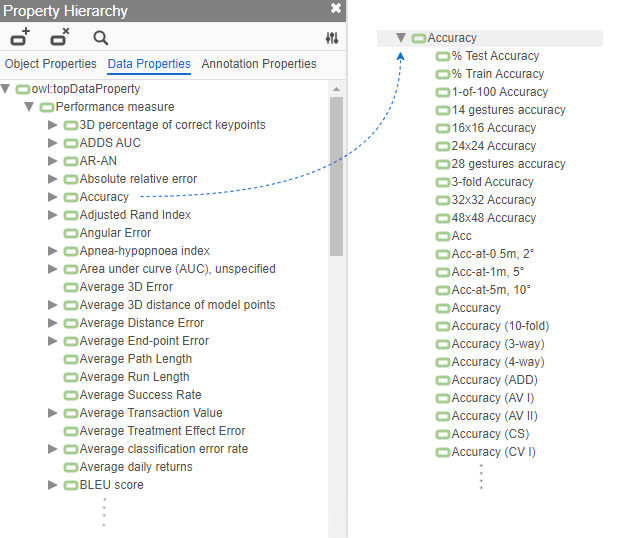
Figure 1: Property hierarchy after manual curation of the raw list of metrics.
Results
Prevalent Metrics in NLP
Bleu score emerges as the most frequently reported metric in NLP benchmarking, used in 61.1% of the datasets. It is prominently employed in machine translation and generation tasks. ROUGE, another dominant metric used across text generation tasks, often correlates with BLEU in its applications. METEOR, despite its advantages in correlating with human judgment, shows limited adoption relative to BLEU and ROUGE.
Co-occurrence of Metrics
The study identifies BLEU as often reported in isolation, whereas ROUGE and METEOR tend to be used in conjunction with other metrics. The analysis of co-occurrence patterns demonstrates that while BLEU and ROUGE are frequently used together, METEOR more consistently accompanies other metrics, reflecting an integrated evaluation approach.
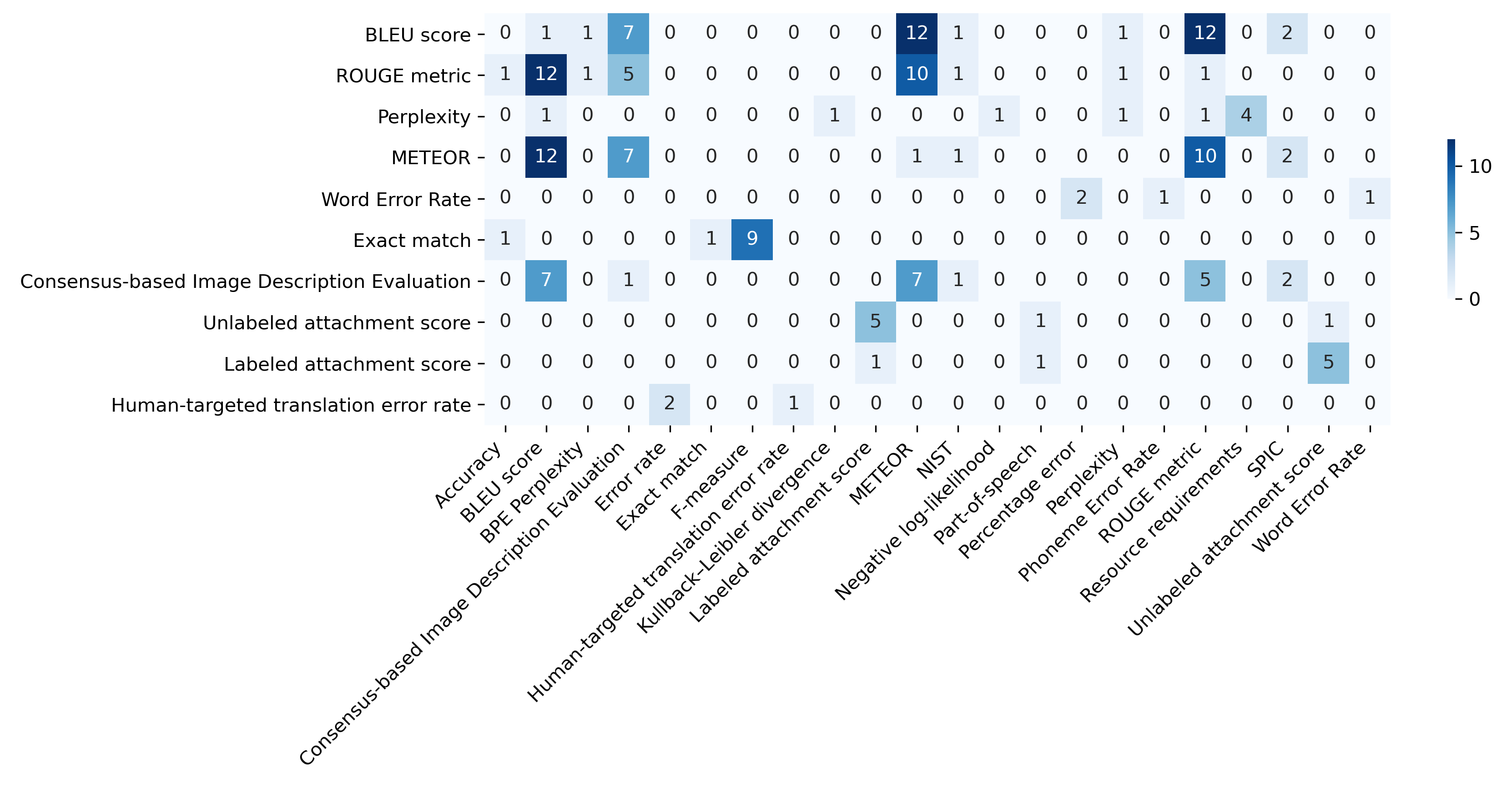
Figure 2: Co-occurrence matrix for the top 10 most frequently used NLP metrics.
Inconsistencies and Ambiguities
The manual curation process underscored significant inconsistencies in metric reporting. For example, ROUGE metrics are often ambiguously reported without specifying the variant, leading to potential misinterpretations when comparing studies. The study highlights the need for clarity and specificity in reporting metrics to facilitate consistent evaluation and replication.
Discussion
The continued reliance on traditional metrics, despite their limitations, poses challenges for accurately assessing NLP model performance. While newer metrics like METEOR++ 2.0 and BERTScore offer enhanced correlation with human judgment and address some of the shortcomings of predecessors, their adoption remains less widespread. The dynamic nature of benchmarks and the evolving landscape of NLP necessitate frameworks that account for multi-dimensional aspects of evaluation, such as robustness and fairness, alongside traditional performance measures.
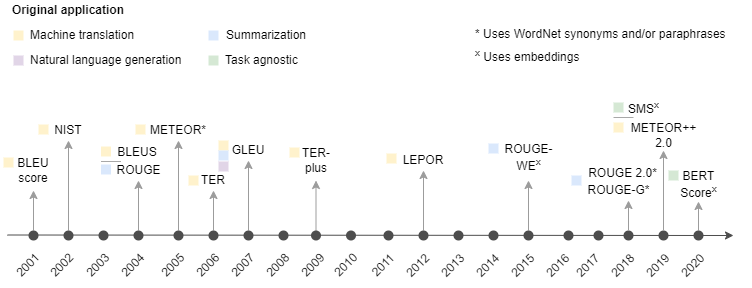
Figure 3: Timeline of the introduction of NLP metrics and their original application.
Recommendations and Future Directions
To advance the state of NLP benchmarking, the study recommends:
- Ensuring precise reporting by clearly stating metric variants and adaptations.
- Leveraging comprehensive metrics that capture diverse performance aspects beyond n-gram matching.
- Increasing the use of reference implementations to enhance reproducibility.
Emerging concepts like bidimensional leaderboards and evaluation-as-a-service frameworks (e.g., Dynascore) represent promising directions, allowing for customizable and holistic evaluation strategies that could incorporate user-defined priorities, thus enhancing the utility of benchmarks amid ongoing advancements in NLP.
Conclusion
The paper provides pivotal insights into the complexities of metric usage in NLP, emphasizing the importance of consistent, clear metric reporting and the adoption of multifaceted evaluation metrics. Future research should focus on developing comprehensive frameworks that integrate newer metrics with traditional ones, offering robust evaluations adaptable to different NLP domains and tasks.
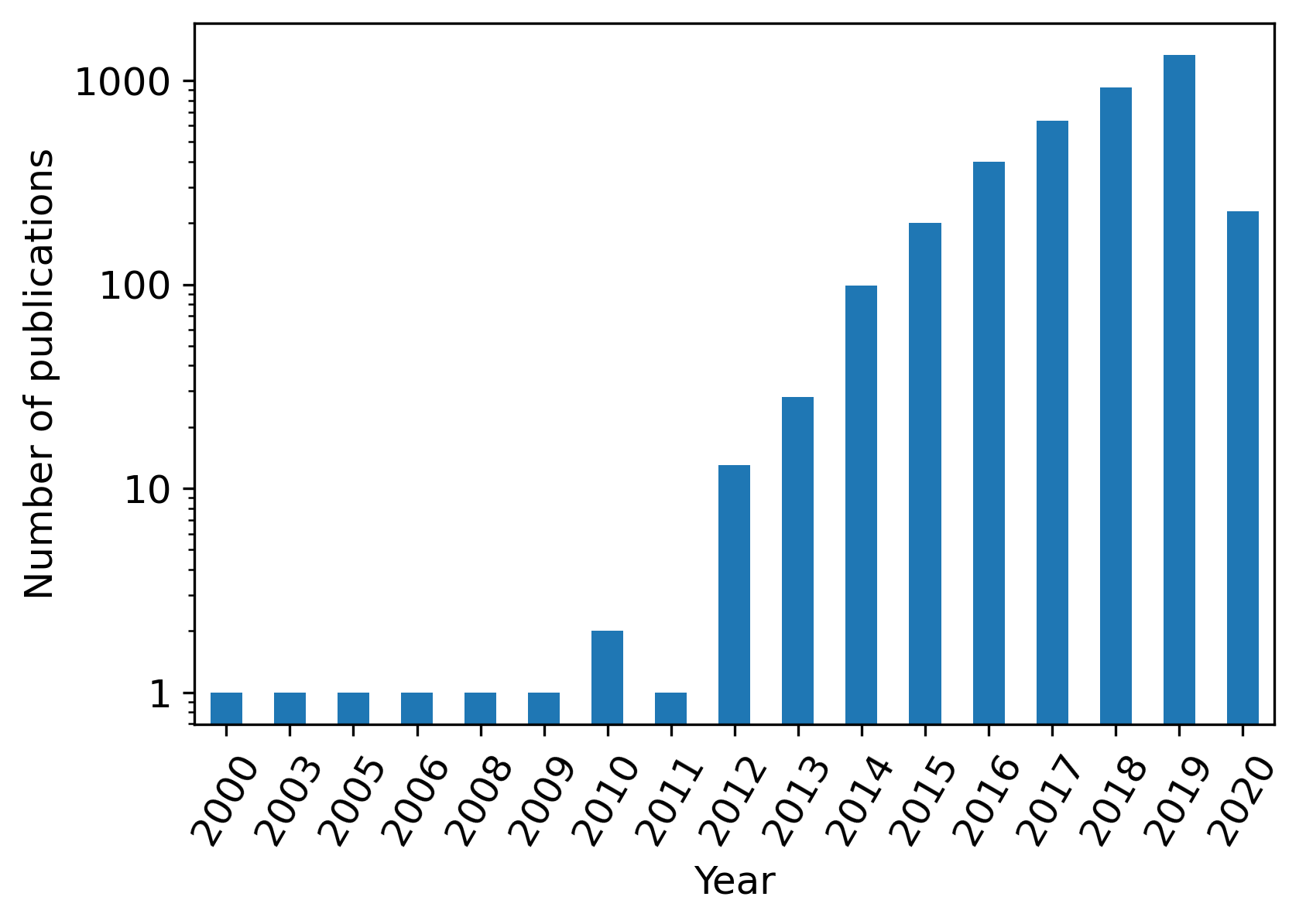
Figure 4: Number of publications covered by the total dataset per year.