- The paper introduces SCVRL, a method that fuses shuffled contrastive and visual contrast objectives to capture both motion and semantic features in videos.
- It utilizes a transformer-based MViT backbone with specialized MLP heads to differentiate temporally shuffled sequences from ordered ones.
- Empirical results on benchmarks like SSv2 and UCF101 demonstrate SCVRL’s superior performance in motion-intensive video action recognition tasks.
An Expert Analysis of "SCVRL: Shuffled Contrastive Video Representation Learning"
Introduction and Objective
The paper "SCVRL: Shuffled Contrastive Video Representation Learning" introduces a novel approach for self-supervised learning in videos, focusing on capturing both semantic and motion patterns. Traditional contrastive learning frameworks, like CVRL, predominantly emphasize semantic representations and overlook temporal dynamics. SCVRL addresses this gap by integrating temporal cues into the contrastive learning paradigm, leveraging a reformulated shuffle detection task within an advanced contrastive framework.
Key Insight: The paper presents a method for encoding motion information alongside visual semantics, which is pivotal for improving video representation quality, especially in contexts where motion is crucial for understanding the content.
Methodology and Implementation
SCVRL incorporates two distinct contrastive objectives: shuffled contrastive learning and visual contrastive learning. The method utilizes a transformer-based architecture, specifically the Multiscale Vision Transformer (MViT), to assimilate these objectives into a cohesive framework.
Shuffled Contrastive Learning: This approach distinguishes between temporally shuffled and ordered video sequences, thus compelling the network to inherently learn motion patterns. Positive pairs are constructed from differently augmented versions of the same video clip, while negatives result from temporal permutations of these clips.
Visual Contrastive Learning: Similar to CVRL, this objective ensures semantic information is preserved by sampling positive pairs from within the same video and negatives from different videos, thus fostering semantic associations.
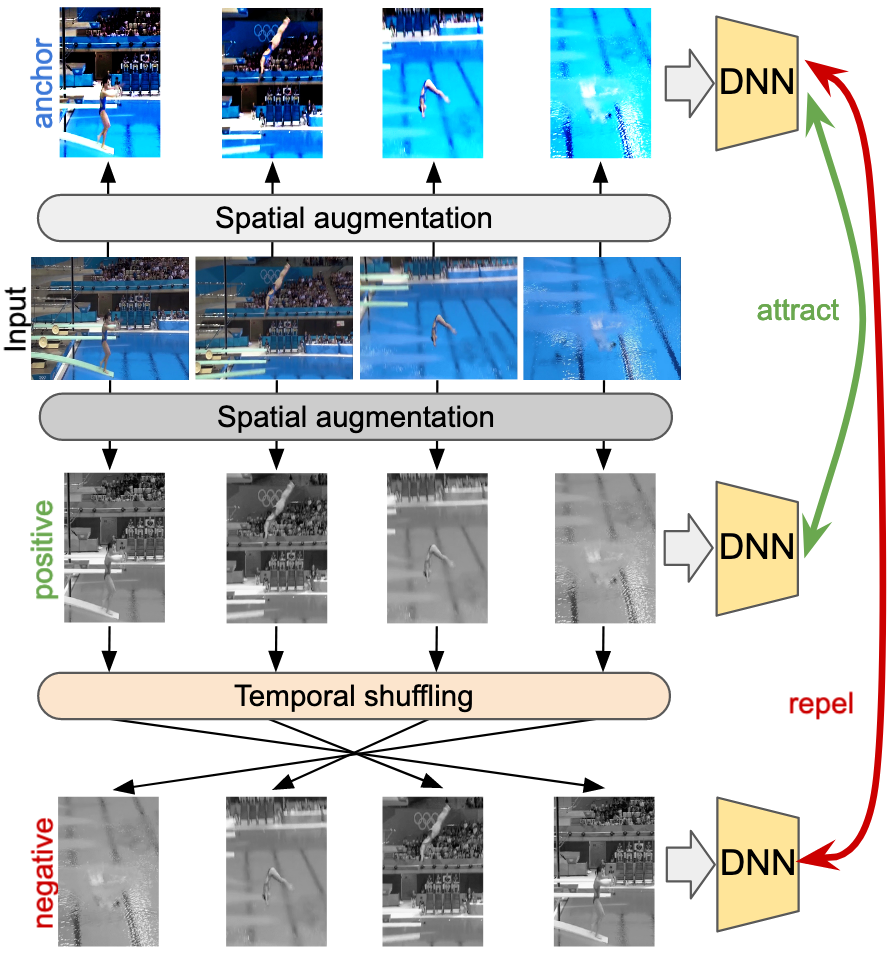
Figure 1: Our temporal contrastive loss reformulates frame shuffling in a contrastive learning framework to inject temporal cues into video representation.
SCVRL's architecture is visually illustrated to demonstrate the dual contrastive objectives of the framework. The methodology details negative sampling across the same video through permutations to ensure learning temporal sensitivity effectively.
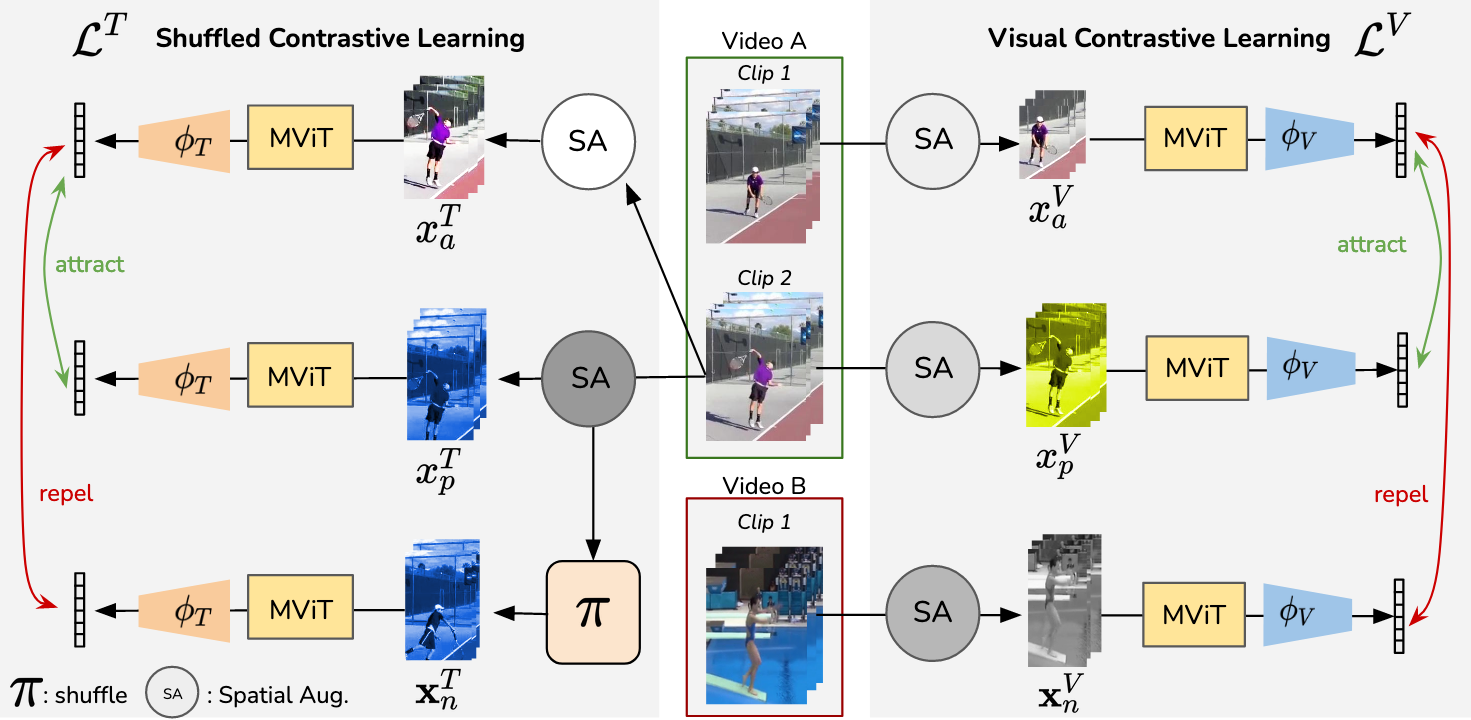
Figure 2: SCVRL's method overview, highlighting its shuffled contrastive learning (left) and visual contrastive learning objectives (right).
SCVRL's reliance on the MViT architecture is strategized for its large temporal receptive field, crucial for discerning motion information across video frames. The use of separate MLP heads for each contrastive objective underlines the need to compartmentalize semantic and temporal learning within the shared MViT backbone.
SCVRL's efficacy was empirically validated across video action recognition benchmarks like Diving-48, UCF101, HMDB51, and Something-Something-v2 (SSv2). Notably, its performance was superior on datasets requiring nuanced temporal understanding, as evidenced in tasks with high-motion action scenarios.
Quantitative Results: SCVRL consistently outperformed standard baselines, exhibiting robustness in learning motion-intensive tasks, reflected in benchmarks with a high dependency on temporal alignment.
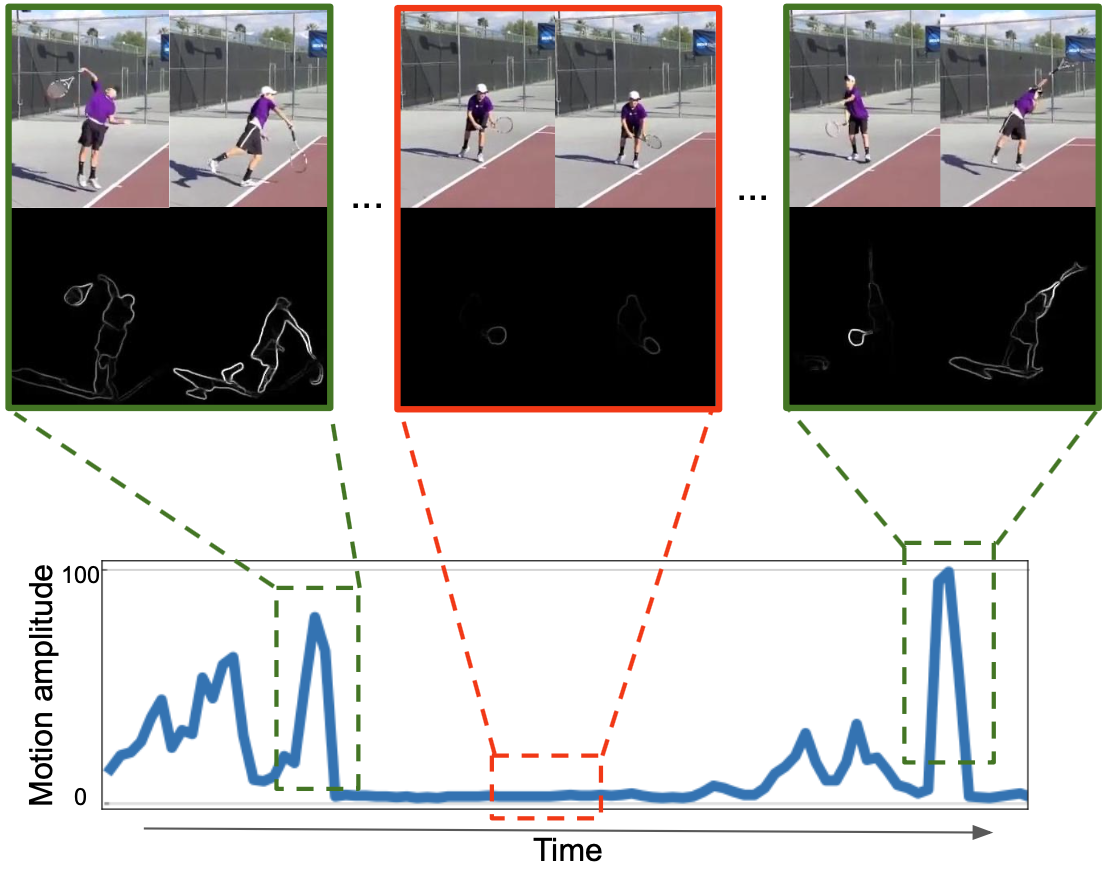
Figure 3: Targeted Sampling indicates clips with high motion, ensuring that shuffling enhances temporal discrimination.
Future Implications and Conclusions
SCVRL signifies a shift in contrastive video learning by emphasizing motion alongside semantics, broadening the application potential of self-supervised representations in dynamic video analysis environments. It bridges a critical gap between static image-based representation and the evolving demands of video content understanding.
Speculative Developments: This framework can be extended to unsupervised settings in video prediction, anomaly detection, and enriched activity recognition, beyond conventional datasets, driving future enhancements in video-based AI diagnostics.
In conclusion, SCVRL advances the frontier of self-supervised video representation learning by ingeniously marrying temporal cues with semantic context, thereby setting a new standard in contrastive learning paradigms. The empirical results substantiate its contribution, offering compelling insights into the dynamism of video content interpretation.