- The paper presents a novel TWA approach that optimizes trainable coefficients across historical weight vectors to enhance training efficiency and generalization.
- It leverages low-dimensional subspace training, gradient projection, and distributed GPU computation to reduce required epochs by 30-50% while maintaining accuracy.
- Experimental results demonstrate over 1% accuracy improvements in CIFAR tasks and higher mAP in object detection, highlighting TWA's practical benefits.
Trainable Weight Averaging: Accelerating Training and Improving Generalization
Introduction
The paper "Trainable Weight Averaging: Accelerating Training and Improving Generalization" (2205.13104) introduces a novel approach termed Trainable Weight Averaging (TWA), which presents a significant advancement in subspace training methods for deep neural networks (DNNs). By exploring low-dimensional subspaces during the training of DNNs, TWA facilitates efficient training while simultaneously enhancing generalization performance. This approach diverges from traditional methods, which typically train in large parameter spaces, by constraining the training trajectory to evolve in a much smaller subspace.
Methodology
Trainable Weight Averaging Framework
TWA seeks to optimize the coefficients of multiple historical weight vectors, which are collected throughout the training process, hence enabling efficient weight averaging through linear combinations of these vectors. Unlike stochastic weight averaging (SWA), where averaging of weights is performed with fixed coefficients, TWA allows for the coefficients to be trainable. This flexibility enables the optimizer to adapt more precisely to different stages and scenarios encountered in training, improving robustness and model performance.
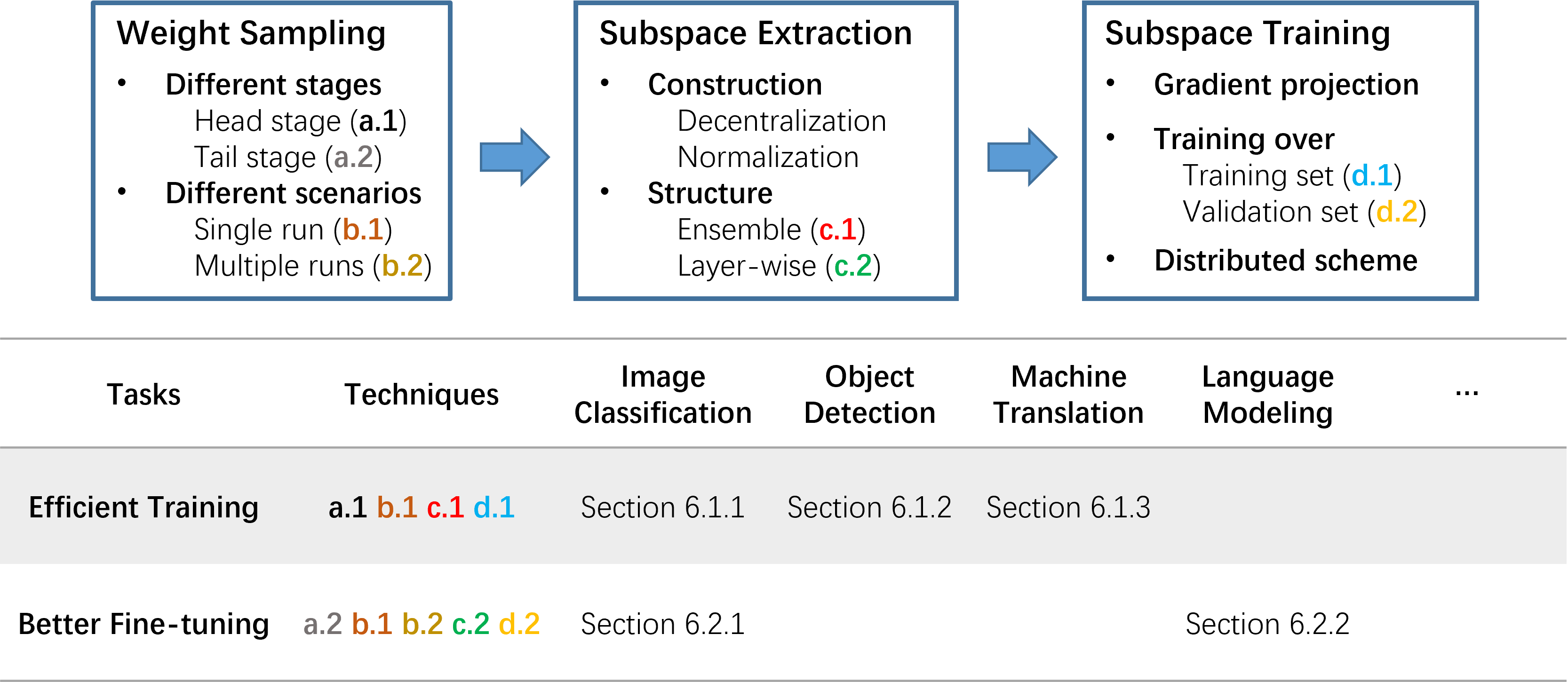
Figure 1: A detailed diagram overview of Trainable Weight Averaging Framework.
TWA operates through several main procedures. The weight sampling process collects weights at various stages of training, followed by subspace extraction, where normalization and decentralization techniques are employed to derive orthogonal subspaces. Subspace training then ensues, involving gradient projection onto the extracted subspaces and efficient distributed computation techniques.
Parallel Distributed Training
To address the computational and memory burdens associated with large-scale DNNs, the authors propose a parallel distributed training scheme. By partitioning weight matrices across multiple GPUs, this scheme allows for efficient computation of gradient projections by distributing the workload evenly, thereby enhancing scalability and reducing training time significantly.
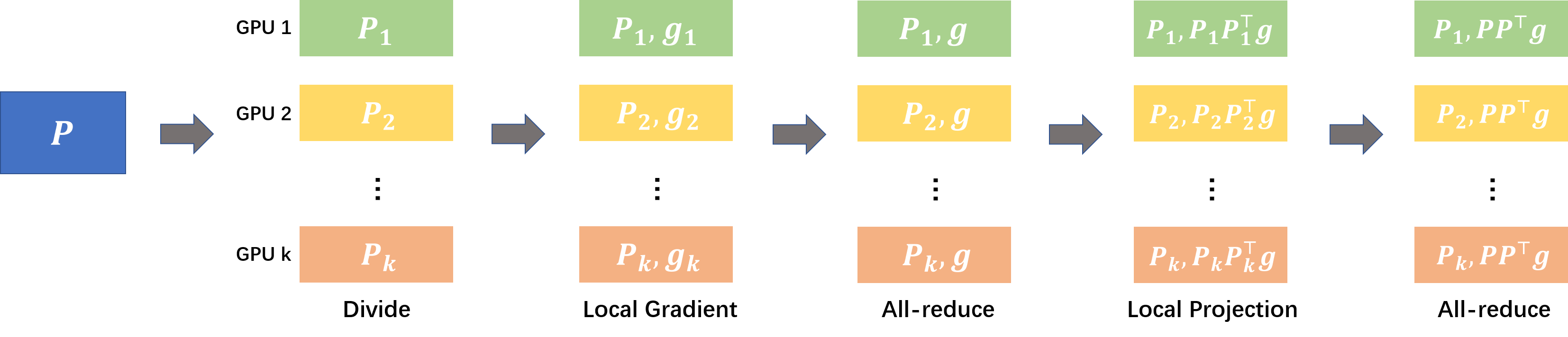
Figure 2: An efficient parallel scheme for subspace training. Suppose that there are k GPUs for distributed training.
Experimental Results
The paper reports extensive experiments across various domains, including image classification, object detection, and machine translation. TWA demonstrates substantial efficacy in reducing computational time, requiring 30-50% fewer epochs to achieve comparable or improved accuracy compared to traditional training methods.
For instance, in image classification tasks on CIFAR-10 and CIFAR-100 datasets, TWA consistently improved accuracy by over 1%, while simultaneously reducing the generalization gap. In object detection using Yolov3 on the COCO dataset, TWA achieved an impressive increase in mean average precision (mAP), outperforming both standard and SWA methods.
Moreover, the application of TWA in enhancing the performance of fine-tuned models over various architectures and configurations showcases its potential for efficient training across diverse machine learning tasks and datasets.
Implications and Future Directions
The proposed TWA framework highlights a shift towards more efficient DNN optimization strategies by leveraging the intrinsic low-dimensional trajectories that characterize the training dynamics of modern neural networks. This paradigm allows for reduced computational overhead and improved generalization, making it a promising direction for future research and development in AI.
Potential avenues for future exploration include extending the TWA methodology to extremely large models, integrating lightweight techniques like adapter tuning, and exploring its applicability in low precision training and quantization scenarios.
Conclusion
The paper presents TWA as a versatile framework capable of accelerating training and enhancing generalization of DNNs through efficient subspace exploration and weight averaging. With a well-documented performance in extensive experiments, TWA holds promise as a transformative approach in both practical applications and theoretical understanding of neural network training methodologies.
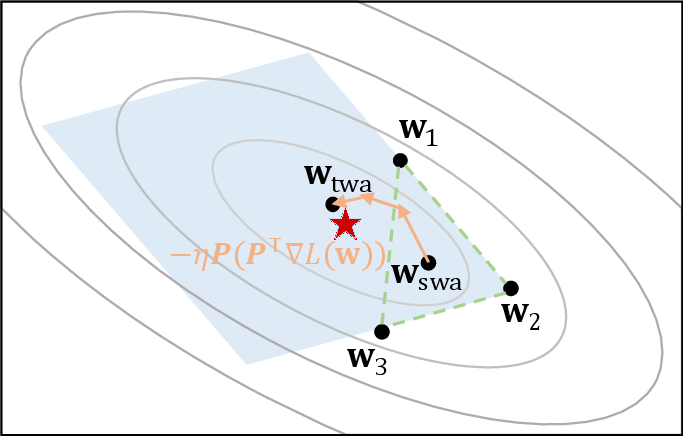
Figure 3: Trainable Weight Averaging intuition. There are three weight points that form a 3-dimensional subspace.
