- The paper introduces a theoretical framework that categorizes sources of indeterminacy in latent spaces using generator and prior distributions.
- It demonstrates two approaches—fixed latent distributions and triangular flow models—to achieve strong identifiability in generative models.
- The work has practical implications for enhancing disentanglement and causal inference by ensuring unique and accurate latent representations.
Indeterminacy in Generative Models: Characterization and Strong Identifiability
Introduction to Indeterminacy in Generative Models
Indeterminacy in generative models arises due to the inability to uniquely infer latent variables from observed data, even given infinite observations. This paper explores the problem using models like the VAE and ICA, where indeterminacies such as rotational variance in latent spaces persist. Addressing these indeterminacies is key for applications requiring unique latent representations, such as disentanglement, causal representation, and posterior collapse mitigation.
Theoretical Framework for Identifiability
The paper proposes a framework to analyze model identifications using the generator function and prior distribution spaces. Indeterminacies in latent models are categorized into transformations sourced from the generator space and latent distribution space, formalized as () and (z). These transformations must intersect for model identifiability:
- (): Automorphisms formed via generator functions describing possible mappings as combinations of f−1∘f.
- (z): Transports converting one distribution into another within latent space.
The intersection of these sets represents all potential model indeterminacies, aiming towards strong identifiability where a model is fully constrained such that no non-trivial transformations exist beyond the identity mapping.
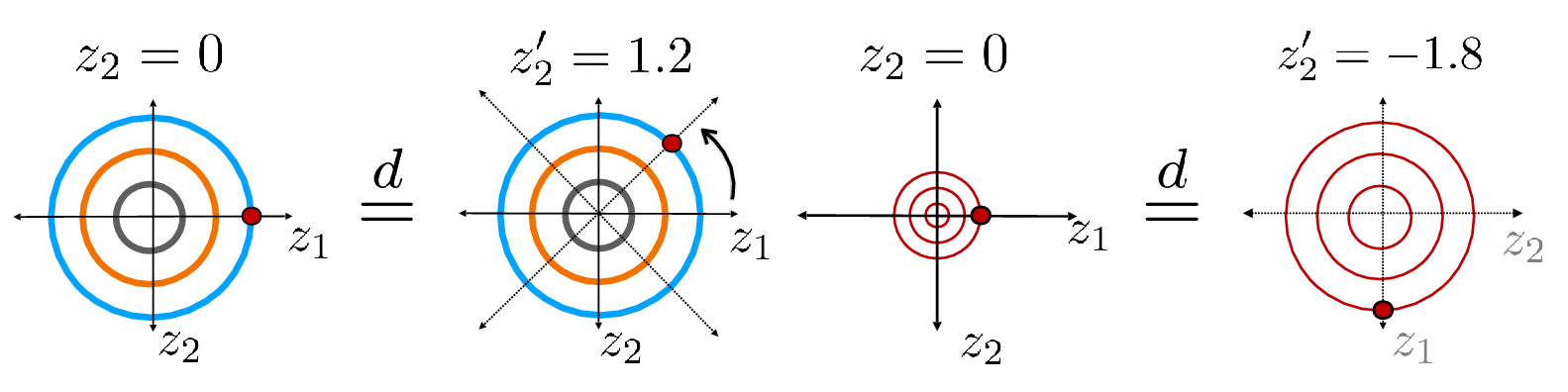
Figure 1: Rotational indeterminacy is fundamental in Gaussian i.i.d.\ models, where each point on the above orbits represent an equivalent solution. If a task gives constant output on each orbit, the task is identifiable even in the presence of model indeterminacies.
Characterizing Strong Identifiability
Strong identifiability—unique latent recovery for all possible observations—requires minimizing indeterminacies via constraints on generator or latent spaces. The paper introduces two approaches to achieve strong identifiability:
- Fixed Latent Distributions: By fixing latent distributions and using multiple distinct environments, the indeterminacy in Gaussian models can be controlled, yielding unique mappings for corresponding observations.
- Triangular Transportations: Monotonic triangular flow models, such as smooth flows, offer identifiability without sacrificing flexibility, integrating concepts from optimal transport theory.
Practical Implications
The framework's implications are extensive. By understanding model identifiability, practitioners can design models with fewer sources of error and greater accuracy in latent representations, enabling more trustworthy applications from simulation studies to causal inference tasks:
- Disentanglement Applications: Ensuring latent shifts (like translations) remain identifiable across models allows exploration of generative capabilities for synthetic data creation.
- Causal Modeling: The ability to pinpoint causal relationships amid observational data boosts model applicability in predictive analytics.
Conclusion
This paper provides a robust theoretical approach to generative model identifiability, centering on reducing indeterminacy through structured latent spaces and careful generator constraints. The intersection of theoretical rigor and practical applications paves the way for further research into ensuring robust identifiability, expanding generative modeling's effectiveness across domains.
For future work, researchers might explore other forms of constraint applications or assess the finite-data limitations impacting inductive generalizations from the proposed framework.
Figure 1: Rotational indeterminacy is applied within Gaussian i.i.d models, showing equivalence across varied orientations in data space.