Depth-CUPRL: Depth-Imaged Contrastive Unsupervised Prioritized Representations in Reinforcement Learning for Mapless Navigation of Unmanned Aerial Vehicles
Published 30 Jun 2022 in cs.RO and cs.AI | (2206.15211v2)
Abstract: Reinforcement Learning (RL) has presented an impressive performance in video games through raw pixel imaging and continuous control tasks. However, RL performs poorly with high-dimensional observations such as raw pixel images. It is generally accepted that physical state-based RL policies such as laser sensor measurements give a more sample-efficient result than learning by pixels. This work presents a new approach that extracts information from a depth map estimation to teach an RL agent to perform the mapless navigation of Unmanned Aerial Vehicle (UAV). We propose the Depth-Imaged Contrastive Unsupervised Prioritized Representations in Reinforcement Learning(Depth-CUPRL) that estimates the depth of images with a prioritized replay memory. We used a combination of RL and Contrastive Learning to lead with the problem of RL based on images. From the analysis of the results with Unmanned Aerial Vehicles (UAVs), it is possible to conclude that our Depth-CUPRL approach is effective for the decision-making and outperforms state-of-the-art pixel-based approaches in the mapless navigation capability.
The paper introduces Depth-CUPRL, integrating unsupervised depth estimation and contrastive learning to overcome high-dimensional observation challenges in UAV navigation.
It employs a SAC-based RL algorithm with a prioritized replay buffer, achieving up to 99.2% success rates and faster convergence in simulated environments.
The methodology outperforms traditional pixel-based techniques by effectively transforming raw images into robust depth maps for obstacle avoidance and efficient mapless navigation.
Depth-CUPRL: Depth-Imaged Contrastive Unsupervised Prioritized Representations in Reinforcement Learning for Mapless Navigation of Unmanned Aerial Vehicles
Introduction
The paper introduces Depth-CUPRL, a novel approach combining depth image estimation, contrastive learning, and reinforcement learning (RL) to navigate UAVs without predefined maps. Traditional RL methods struggle with high-dimensional observations, such as raw pixel images, leading to inefficient learning. Depth-CUPRL addresses this by utilizing depth map estimations to enhance navigation capabilities. This integration aims to outperform existing pixel-based RL techniques in UAV mapless navigation.
Methodology
The Depth-CUPRL methodology involves several steps for pre-processing and learning:
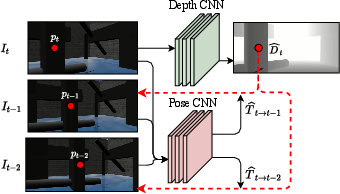
Depth Estimation: Depth maps are generated using a trained depth estimation CNN, leveraging monocular image inputs. This unsupervised learning approach derives depth maps from sequences of images, guided by geometric consistency across frames (Figure 1).
Figure 1: Unsupervised Depth estimation architecture. The depth network takes the current as input and outputs a depth map Dt.
Network Architecture: The architecture consists of three main networks:
Depth estimation CNN to produce depth maps.
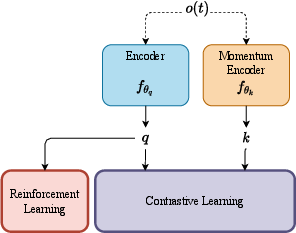
Contrastive learning structure inspired by CURL (Contrastive Unsupervised Representations for RL), which uses contrastive losses to improve data representation (Figure 2).
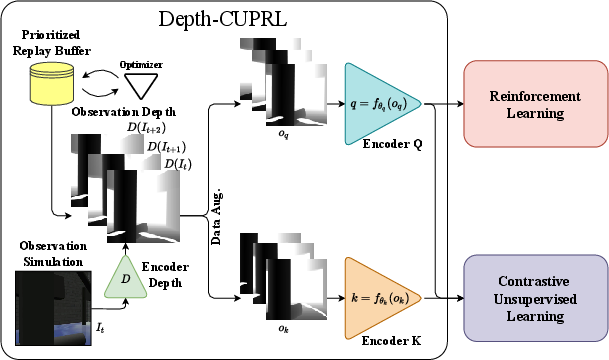
Reinforcement Learning: A SAC-based (Soft Actor-Critic) RL algorithm is employed for navigation and obstacle avoidance. The network inputs are depth images that pass through CURL to learn representations, combined with prioritized experience replay to enhance learning efficiency.
Figure 3: System of Depth-CUPRL: The observations are passed through a network that generates the depth images. These depth images are stored in a replay memory, and it is sampled memories in the buffer to make the Contrastive and Reinforcement Learning.
Prioritized Replay Memory: This memory allows more critical transitions to be replayed more frequently, focusing learning on significant past events, thereby improving sample efficiency in the training process.
Experimental Setup
The experimental setup involves simulations run in a Gazebo-based environment, optimized for UAV control using ROS. A Hydrone-based UAV is simulated, focusing on the mapless navigation in environments populated with obstacles (Figure 4).
Figure 4: First environment.
The UAV's performance is monitored in two different simulated environments, focusing on success in navigation tasks, collision rates, and reward efficiency across episodes.
Results and Analysis
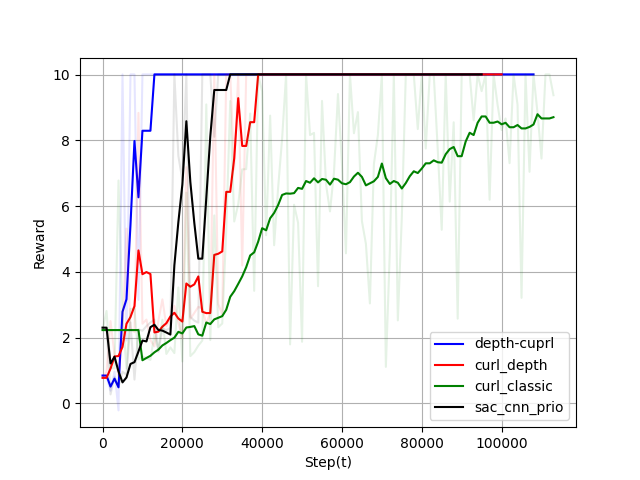
The results demonstrate that Depth-CUPRL achieves significant improvements in success rates and convergence speeds compared to traditional pixel-based RL and non-contrastive depth-based approaches:
Environment 1: Depth-CUPRL successfully completes all navigation episodes without collisions.
Environment 2: Even in a more complex setup, Depth-CUPRL achieves a 99.2% success rate, outperforming all other tested models in efficiency and robustness.
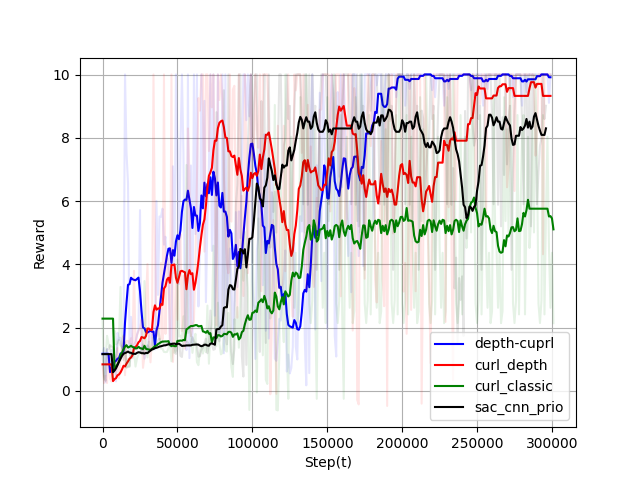
Figure 5: Moving average of the reward over 100000 and 300000 training steps for the first and second environment, respectively.
Discussion
Depth images significantly enhance RL performance by providing more robust environmental representations than raw pixels. Prioritized learning combined with contrastive learning yields faster convergence and higher success rates, demonstrated in complex UAV navigation tasks.
Conclusion
Depth-CUPRL presents a promising direction for improving UAV navigation using depth information and optimized learning techniques. The integration of prioritized replay and contrastive learning offers reliable and efficient mapless navigation, setting the stage for further exploration in both aerial and underwater autonomous systems. Future work will focus on adapting these techniques to diverse environments and potentially applying them to real-world UAV systems.