- The paper presents a novel algorithm that learns sample-specific annotator error dependencies through label fusion.
- It leverages weight vectors and confusion matrices, approximated using the Birkhoff-von Neumann theorem, to refine label reliability.
- Extensive experiments on MNIST, CIFAR-100, and ImageNet-100 show improved accuracy over traditional noisy label methods.
Learning from Multiple Annotator Noisy Labels via Sample-wise Label Fusion
Introduction
The paper "Learning from Multiple Annotator Noisy Labels via Sample-wise Label Fusion" (2207.11327) investigates the challenge of training classifiers using datasets with multiple noisy labels. Particularly, it addresses situations where annotators provide inconsistent or erroneous labels due to subjective biases or economic constraints, which is a common occurrence in real-world applications. Unlike existing methods that typically assume uniformity in annotator error parameters across data samples, this study introduces a novel algorithm that learns label error dependencies both annotator-wise and sample-wise.
Proposed Method
The authors propose an algorithm that employs sample-wise label fusion, where for each input data sample, the algorithm simultaneously learns weight vectors and confusion matrices specific to that sample. The confusion matrix captures an annotator's labeling tendencies, while the weight vector adjusts the influence of each annotator's labels on the final label prediction. The method leverages the Birkhoff-von Neumann theorem to approximate these sample-specific parameters, thus making the model computationally feasible.
The training process involves minimizing a composite loss function that includes a KL divergence term between the model's predictions and the approximated clean label, as well as a regularization term to ensure that confusion matrices reflect realistic annotator behavior.
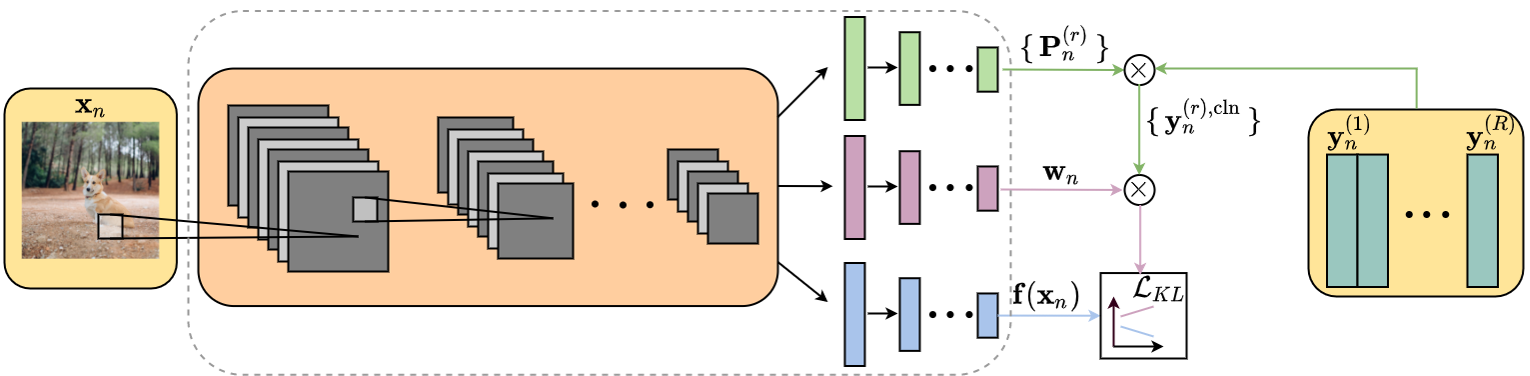
Figure 1: Training flow of the proposed method highlighting the role of confusion matrices and weight vectors in prediction.
Experimental Results
The efficacy of the proposed method is demonstrated through experiments on datasets such as MNIST, CIFAR-100, and ImageNet-100. The method outperformed state-of-the-art approaches like TraceReg and MBEM across various metrics and conditions. For example, on the MNIST dataset under varying annotator skills, the proposed method consistently yielded higher classification accuracy compared to baselines, even in scenarios with considerably noisy labels.
In the experiments, it was shown that when using the proposed method, the learned classifiers closely approached the performance of models trained on clean labels, illustrating the robustness of sample-wise label fusion.
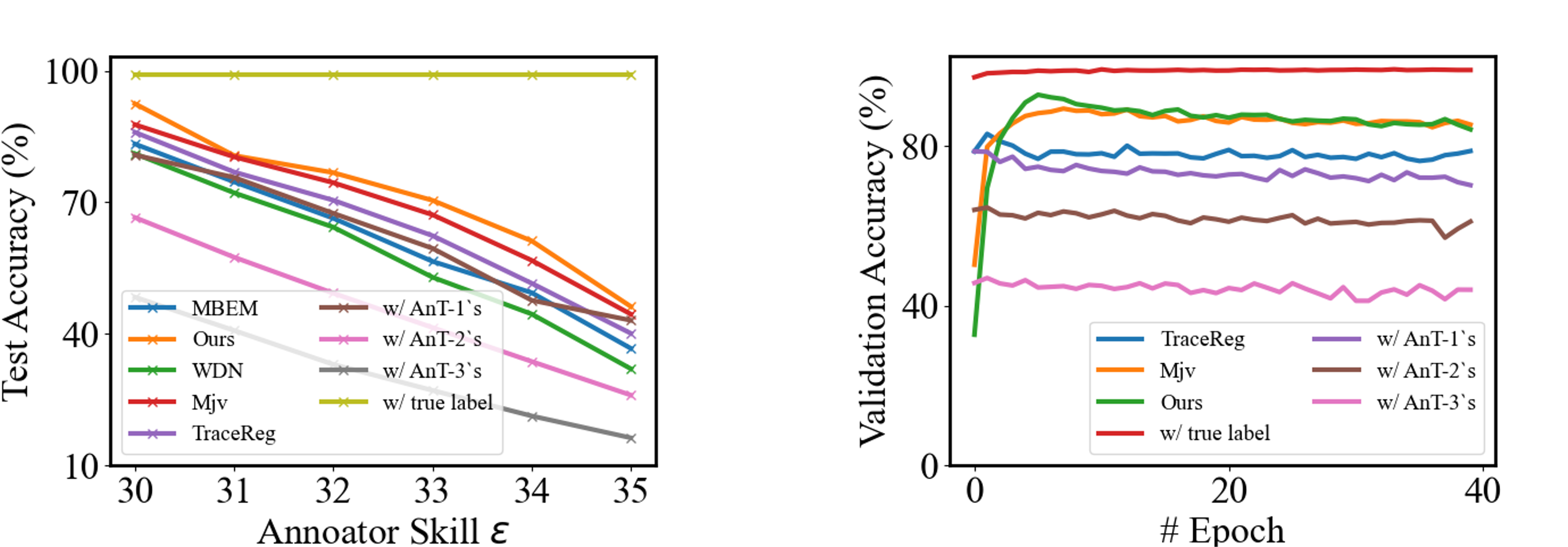
Figure 2: MNIST test accuracies over different annotator skills showing the competitive performance of the proposed method compared to baseline methods.
Theoretical Implications
This research offers significant theoretical contributions by challenging the prevailing assumption of annotator and sample-independent error parameters. It demonstrates that allowing for heterogeneity in error across samples can lead to improved model performance and better noise resilience. This shift in perspective opens new avenues for research in learning from noisy labels, encouraging further exploration of sample-specific parameterizations in machine learning models.
Practical Applications
The implications of this research are particularly relevant in domains where obtaining consistent and accurate labels is challenging, such as medical imaging, where expert opinions may vary. By adopting this method, practitioners can enhance the reliability of models trained on imperfect datasets, ultimately leading to more robust decision-making systems.
Future Directions
Future research could extend this approach to scenarios with a large number of annotators or missing labels by improving the scalability of the model. Additionally, exploring alternative forms of regularization or alternative decomposition methods for confusion matrices could further refine the model's robustness and accuracy.
Conclusion
This study introduces a foundational shift in handling noisy labels by considering sample-wise dependency in annotator error modeling. By implementing this refined approach, the work not only achieves superior numerical performance across various datasets but also advances the theoretical understanding of learning from noisy data, setting a precedent for future research trajectories.