- The paper introduces MTGFlow, an unsupervised MTS anomaly detection method that innovates by combining dynamic graph models with entity-aware normalizing flows.
- It leverages a dynamic graph structure to capture evolving interdependencies among entities and achieves fine-grained density estimation for diverse time series.
- Experiments on real-world datasets show up to a 5.0 AUROC% improvement over state-of-the-art methods, highlighting its practical effectiveness.
Detecting Multivariate Time Series Anomalies with Zero Known Label
The paper presents a novel unsupervised approach for anomaly detection in multivariate time series (MTS) called MTGFlow, which is capable of detecting anomalies without the need for any labeled data. This method addresses the challenges associated with complex interdependencies among entities and the diverse characteristics of individual entities in MTS.
Problem and Methodology
The task of detecting anomalies in MTS without labeled data is particularly challenging due to the requirement to estimate the probability distribution accurately, especially when traditional one-class classification (OCC) methods relying on all normal data do not hold up in real-world scenarios. The authors adopt a hypothesis that anomalies will exhibit sparser densities than normal instances and design a model to effectively estimate these densities using dynamic graphs and entity-aware normalizing flow.
Dynamic Graph Structure
The first key innovation is learning dynamic interdependencies among entities using a graph structure learning module. This aspect is crucial because static graphs, as used in previous works like GANF, do not capture the evolving nature of relationships among sensors or entities in real-world applications.
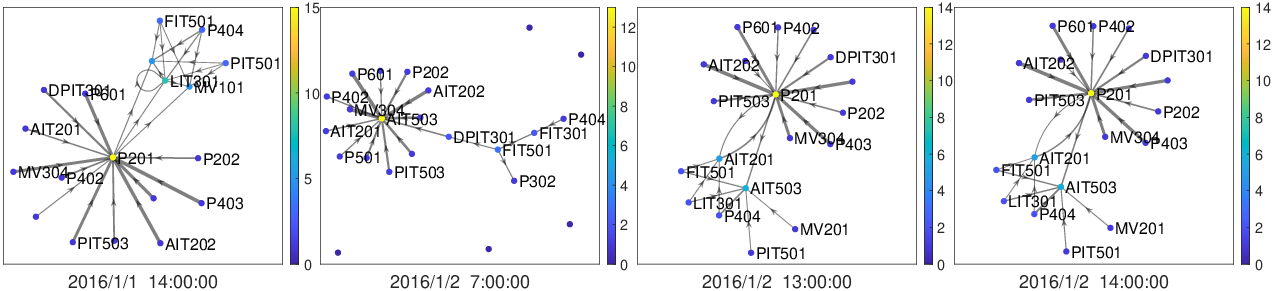
Figure 1: Dynamic graph structure in MTGFlow.
Entity-Aware Normalizing Flow
Secondly, the method employs an entity-aware normalizing flow to estimate the distribution of each entity specifically, rather than applying the same distribution to all entities. By assigning each entity to its unique target distribution, the model achieves fine-grained density estimation, improving the overall accuracy of anomaly detection.
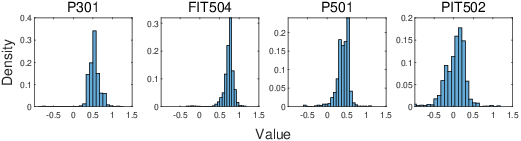
Figure 2: Transformed distributions of multiple entities.
Experimental Results
MTGFlow is evaluated using several real-world datasets, achieving superior performance over state-of-the-art methods such as GANF, DeepSVDD, and USAD. Notably, the method demonstrates an improvement of up to 5.0 AUROC% over existing models, showcasing its ability to effectively learn and adapt to different data characteristics without requiring labeled samples.
Log likelihood variations for anomalies (Figure 3) and comparisons of normalized anomaly scores (Figure 4) between MTGFlow and GANF indicate that MTGFlow shows greater discrimination between normal and abnormal sequences. This superior detection capability is attributed to the model's capacity to dynamically adjust to changing data patterns and capture unique entity behaviors.
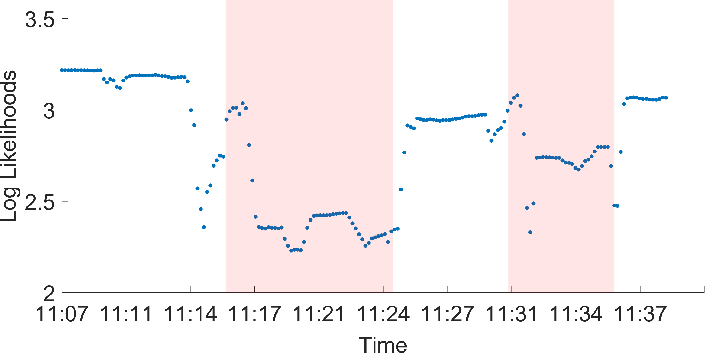
Figure 3: Log likelihoods for anomalies.
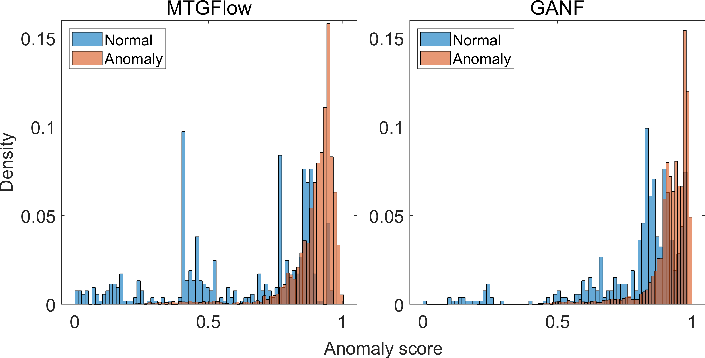
Figure 4: Comparison on normalized anomaly scores between MTGFlow and GANF.
Implications and Future Directions
MTGFlow's approach to MTS anomaly detection via dynamic modeling and entity-aware flows has significant implications for domains where labeled anomaly data is scarce or costly to obtain. By leveraging graph-based dependencies and tailored flow distributions, this work paves the way for more adaptive and robust unsupervised anomaly detection techniques.
The paper's methodology suggests promising directions for further research, such as enhancing the model's scalability and exploring its application to even more diverse types of time series data. Future work could also investigate integrating contextual information to improve interpretability and predictive accuracy.
Conclusion
MTGFlow introduces an innovative framework for unsupervised MTS anomaly detection that effectively overcomes the limitations of existing methods by incorporating a dynamic graph-based approach and entity-aware normalizing flows. Through extensive experimentation and analysis, it has been demonstrated to provide superior performance on benchmark datasets, highlighting its potential for real-world deployment in scenarios with sparse labeled data availability.