- The paper introduces an adaptive optimization algorithm that reformulates Nesterov momentum to improve deep model training speed with minimal overhead.
- It achieves faster convergence and lower training epochs compared to AdamW and LAMB on tasks like image classification and NLP benchmarks.
- Empirical and ablation studies validate Adan’s robustness and efficiency across diverse deep learning architectures and large-batch settings.
Adan: Adaptive Nesterov Momentum Algorithm for Faster Optimizing Deep Models
Introduction
The paper discusses Adan, an adaptive optimization algorithm for training deep neural networks (DNNs) that reformulates the standard Nesterov momentum approach to improve optimization efficiency. By integrating Nesterov acceleration into adaptive gradient methods, Adan aims to enhance the convergence speed and robustness across various architectures and training conditions. It specifically targets optimization inefficiencies due to varying optimizer performance across different DNN architectures and the challenges posed by large-batch training.
Algorithm Overview
Adan modifies the traditional adaptive gradient update by employing a new Nesterov momentum estimation, which allows gradient estimation without additional computational overhead at extrapolation points. The algorithm computes the following update rules:
1
2
3
4
5
6
7
8
9
10
11
12
|
⟨ Initialization ⟩
theta_0, eta, beta_1, beta_2, beta_3
m_0 = g_0
n_0 = g_0^2
⟨ Main Iteration ⟩
while k < K:
g_k = compute_gradient(theta_k)
m_k = (1 - beta_1) * m_{k-1} + beta_1 * (g_k + (1 - beta_1) * (g_k - g_{k-1}))
v_k = (1 - beta_2) * v_{k-1} + beta_2 * (g_k - g_{k-1})
n_k = (1 - beta_3) * n_{k-1} + beta_3 * (g_k + (1 - beta_2) * (g_k - g_{k-1}))^2
theta_{k+1} = theta_k - eta * m_k / (sqrt(n_k) + epsilon) |
Theoretical Insights
Adan's complexity for finding an ϵ-approximate stationary point matches the known lower bounds for nonconvex optimization both under Lipschitz gradient and Lipschitz Hessian settings. The analysis shows that Adan can achieve faster convergence compared to existing algorithms such as Adam and AMSGrad, primarily due to its leveraging of Nesterov acceleration's "look ahead" property and dynamic regularization capabilities.
Adan is empirically validated across a variety of tasks, including image classification (CNNs, ViTs), NLP tasks (LSTMs, BERT), and reinforcement learning (PPO on MuJoCo). Adan consistently outperforms state-of-the-art optimizers on these tasks.
- Image Classification: Adan exhibits superior convergence speed, achieving comparable or improved accuracy with fewer training epochs compared to AdamW and LAMB.
- NLP Tasks: It demonstrates robust performance on GLUE benchmarks with BERT and maintains lower perplexity on sequence tasks with Transformer models.
- Reinforcement Learning: Adan enhances performance metrics when used in conjunction with PPO, indicating better stability and efficiency.
Ablation Studies
Ablation studies show that Adan is robust to variations in its hyperparameters (e.g., momentum coefficients), indicating the potential for minimal tuning effort in practical settings. The algorithm also maintains strong performance across different training settings and large-batch scenarios.
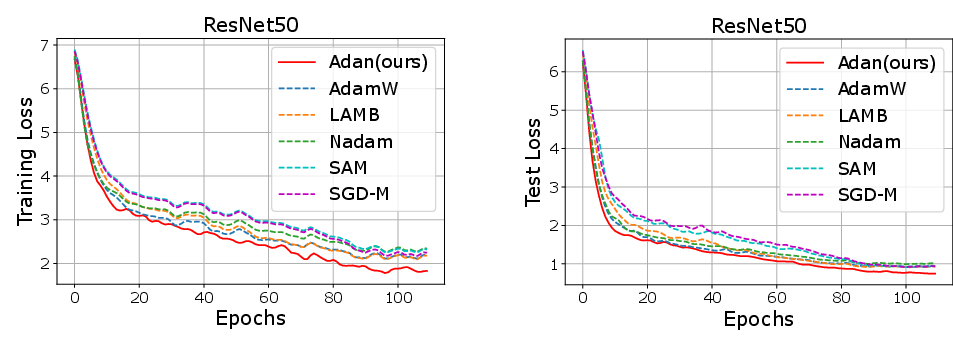
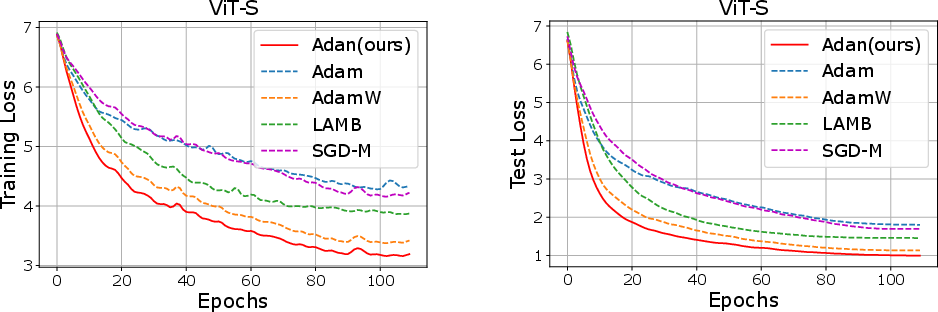
Figure 1: Training and test curves of various optimizers on ImageNet dataset. Training loss is larger due to its stronger data argumentation.
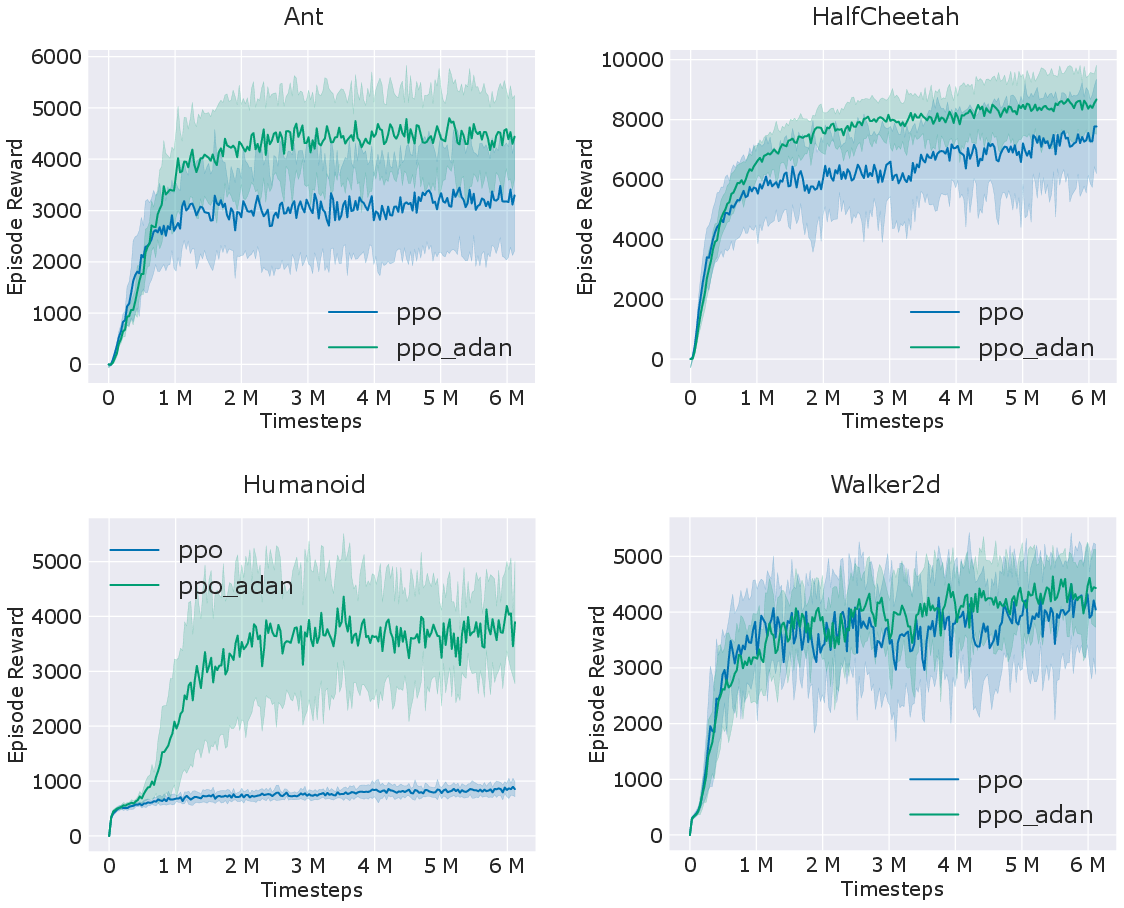
Figure 2: Comparison of PPO and our PPO-Adan on several RL games simulated by MuJoCo. Here PPO-Adan simply replaces the Adam optimizer in PPO with our Adan and does not change others.
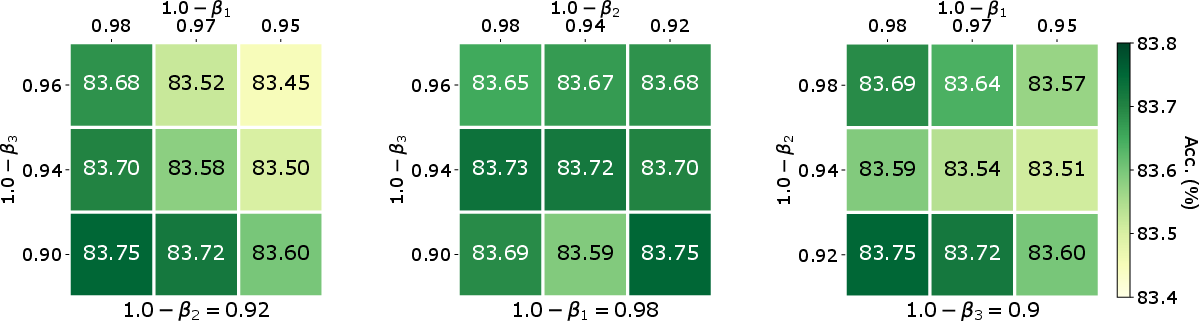
Figure 3: Effects of momentum coefficients (β1,β2,β3) to top-1 accuracy (\%) of Adan on ViT-B under MAE training framework (800 pretraining and 100 fine-tuning epochs on ImageNet).
Conclusion
Adan's integration of Nesterov acceleration with adaptive gradient estimation offers a powerful optimization framework for deep learning models, capable of handling diverse architectures and large-batch regimes. Its theoretical soundness and empirical robustness make it a versatile optimizer that can alleviate the need to carefully select different algorithms for different models or conditions.