- The paper presents a novel trimap-free approach by integrating a foreground probability map into human mattng for enhanced segmentation.
- It refines human segmentation using a three-branch architecture that combines semantic estimation, probability mapping, and detail fusion.
- Experimental results on the P3M-10k dataset demonstrate significant reductions in SAD and improved connectivity compared to traditional methods.
Semantic Guided Matting Net: An Expert Summary
The paper "SGM-Net: Semantic Guided Matting Net" introduces a novel approach to human matting in the domain of computer vision, aimed at improving the extraction of human figures from natural images without the need for auxiliary inputs like trimaps or background images. The proposed Semantic Guided Matting Net (SGM-Net) leverages a new module that predicts a foreground probability map, enhancing image feature utilization and achieving significant improvements over existing methods.
Problem Statement and Motivation
In image matting, the goal is to extract an accurate alpha matte representing the subject's transparency against the background, crucial for applications in image synthesis and visual effects. Traditional methods, such as MODNet, involve high computational cost due to their complex network structures and reliance on additional inputs, posing challenges for practical deployment. SGM-Net was developed to address these limitations by using a single RGB input for high-quality human matting.
Methodology
SGM-Net Architecture
SGM-Net integrates a foreground probability map into the existing MODNet architecture, allowing finer semantic guidance through a detailed probability analysis of each pixel being part of the foreground.
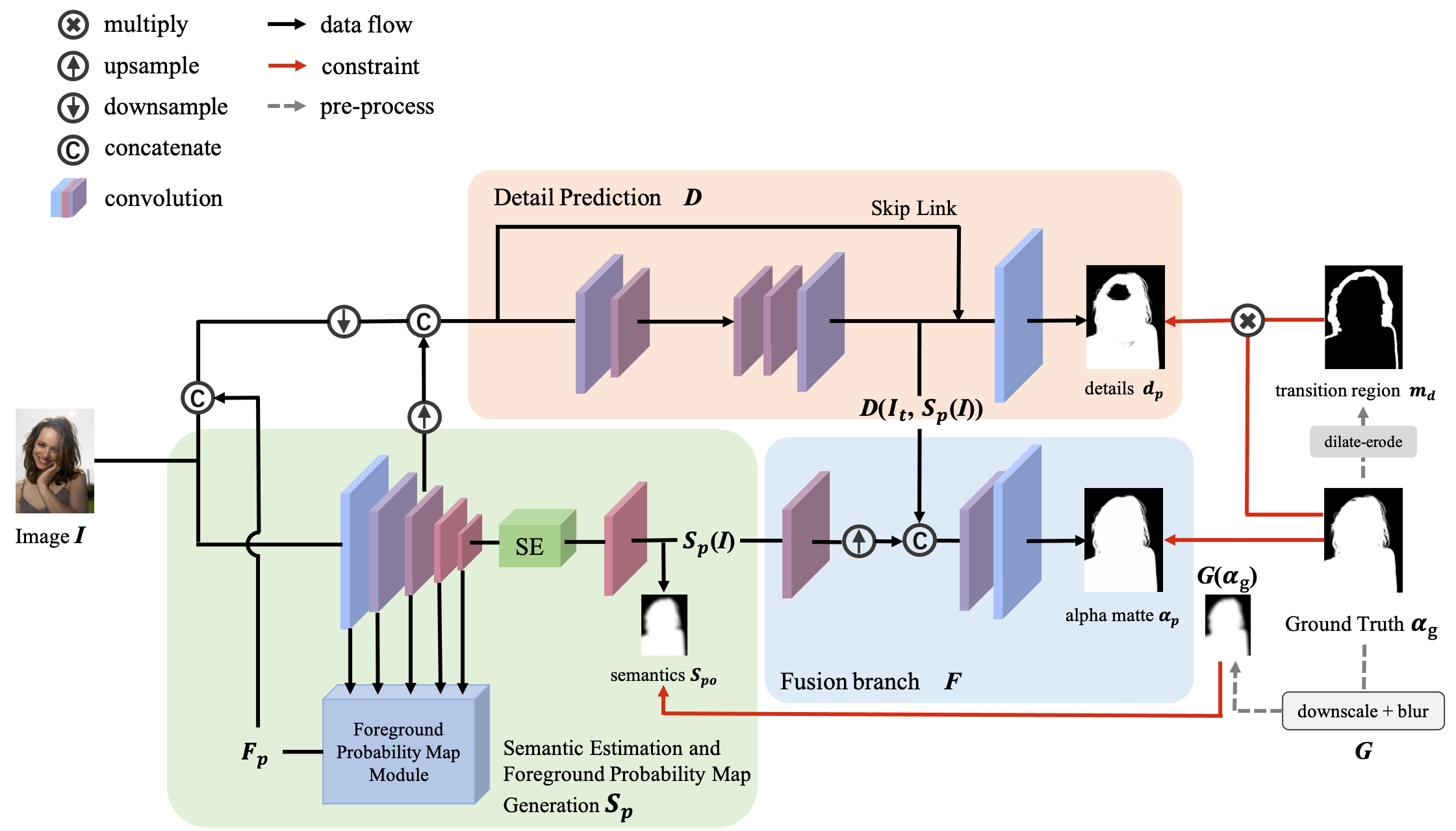
Figure 1: Architecture of SGM-Net. Given an input image I, SGM-Net predicts human semantics Sp(I), foreground probability map Fp, boundary details dp, and final alpha matte αp. All branches are constrained by specific supervisions generated from the ground truth matte αg.
Foreground Probability Map Module
This module predicts the likelihood of each pixel in the input image being part of the foreground. It refines features extracted from a segmentation network and employs an encoder-decoder structure to fuse these features, producing high-resolution alpha mattes without trimap reliance.
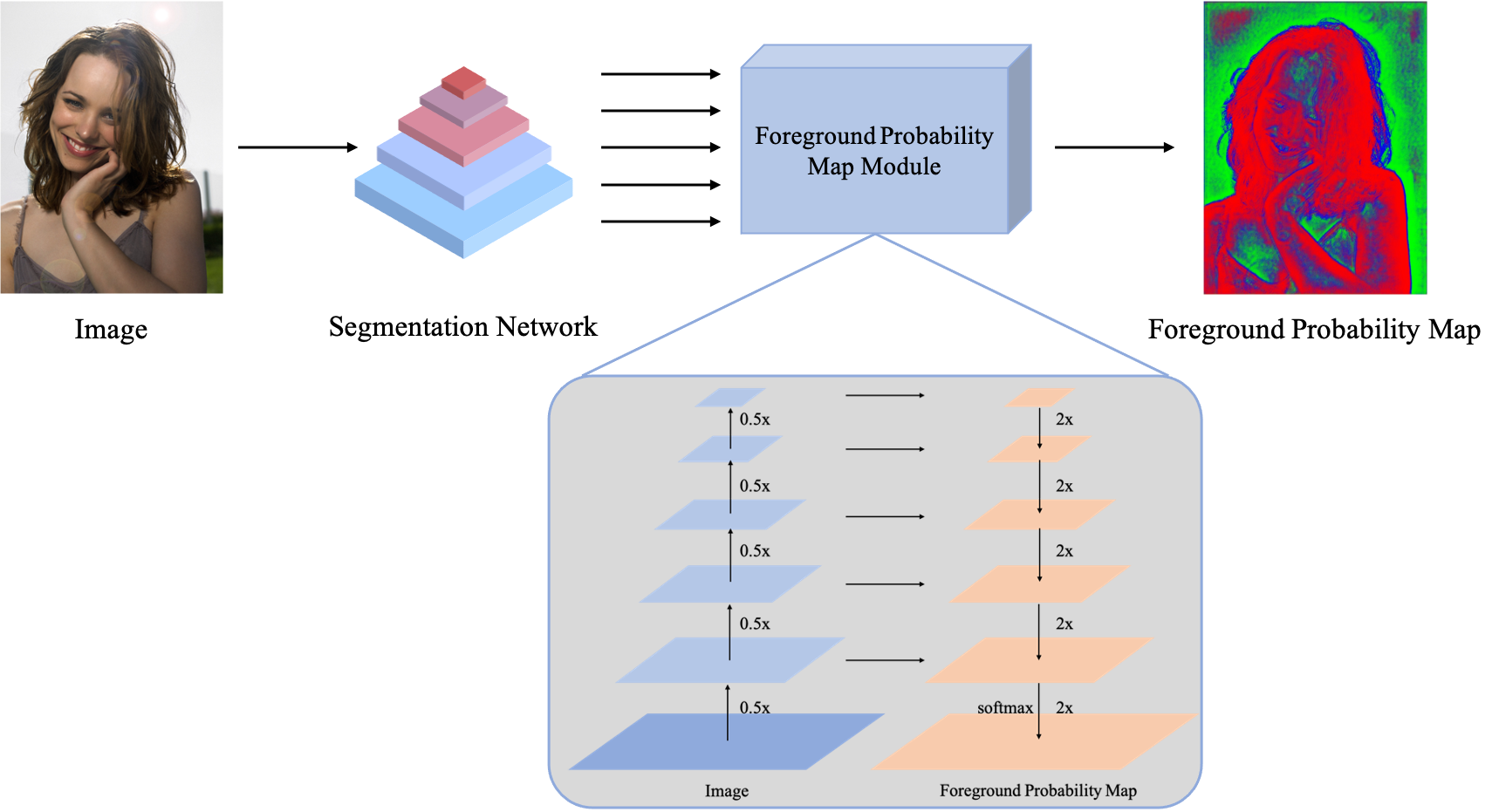
Figure 2: Architecture of Foreground Probability Map Module. The module uses multi-scale features to predict the probability map, which guides the extraction of portrait details.
Semantic and Detail Prediction
SGM-Net processes the input through three branches:
- Semantic Estimation: Coarse semantic understanding is achieved using low-resolution features. It provides a rough human segmentation benchmark to guide finer processes.
- Foreground Probability Map: Developed alongside the semantic branch, it serves as a pivotal input for detail prediction.
- Detail Prediction and Fusion: Focused on high-resolution features, this branch refines fore-edge details and fuses information from previous branches to predict the final alpha matte.
Experimental Results
SGM-Net's performance was evaluated on the P3M-10k dataset and demonstrated significant improvement in all key metrics, including SAD, MSE, and Conn, compared with previous state-of-the-art methods like MODNet.



Figure 3: Alpha matte results by MODNet and our SGM-Net from RGB input.
The results highlighted the model's ability to synthesize composite images with high fidelity against real backgrounds, outperforming traditional trimap-based approaches in realistic scenarios.
Ablation Studies
Ablation studies confirmed the effectiveness of integrating a foreground probability map, which reduced SAD and improved connectivity, underscoring the importance of fine-grained semantic information in enhancing matting accuracy.
Conclusion
SGM-Net offers a robust solution for trimap-free human matting, leveraging semantic guidance and a novel probability map to simplify and enhance matting tasks in dynamic, realistic environments. The design enables superior performance on diverse datasets and extends gracefully to real-world situations, bridging the performance gaps prevalent in previous methodologies without the need for traditional auxiliary inputs. SGM-Net stands as a promising direction for future research in semantic-guided image processing.