- The paper introduces a human-AI pipeline that combines 97 subreddit classifiers with crowd-sourced annotations to identify norm violations.
- The paper employs bootstrap sampling to estimate violation rates, revealing 6.25% in 2016 and 4.28% in 2020 on Reddit.
- The paper highlights the need for enhanced automated detection and community moderation strategies to improve online safety.
Measuring the Prevalence of Anti-Social Behavior in Online Communities
Introduction
The paper "Measuring the Prevalence of Anti-Social Behavior in Online Communities" introduces a robust method to quantify the prevalence of anti-social behavior on Reddit, a major online platform. The study is motivated by the need to empirically measure the extent of anti-social behaviors such as personal attacks and bigotry amidst growing concerns about the social impact of such behaviors in online communities. The authors develop a human-AI pipeline to identify norm violations and employ bootstrap sampling to estimate prevalence rates, providing a methodological advancement in understanding the scope of moderation challenges online.
Human-AI Pipeline for Identifying Violations
The core innovation of this study is the implementation of a human-AI pipeline designed to identify comments that violate widely accepted platform norms. The pipeline integrates 97 subreddit-specific classifiers trained on a balanced dataset of moderated and unmoderated comments. These classifiers, tuned for high recall, are used to flag potential norm violations. Human annotators, trained through a gated instruction process, then validate these flagged comments, ensuring both high precision and recall in detecting violations.
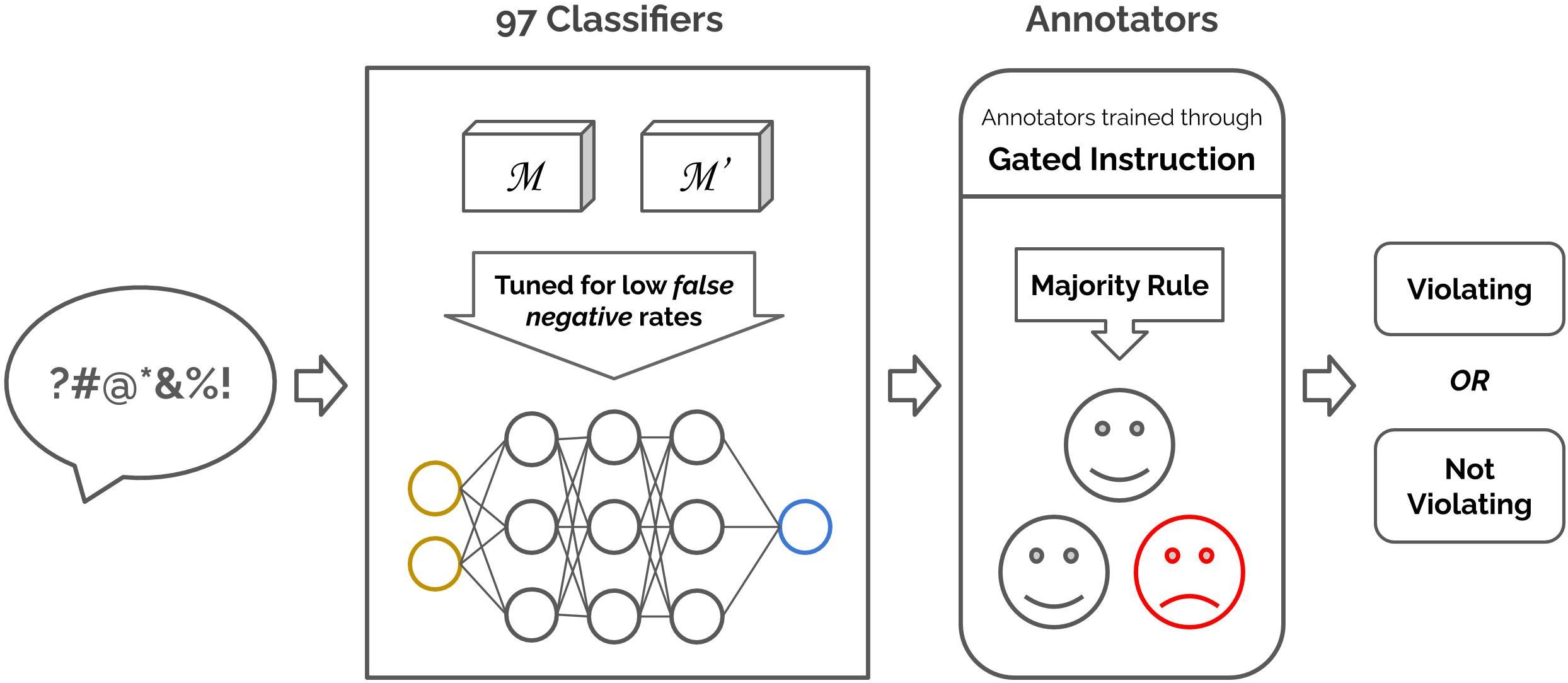
Figure 1: An illustration of the human-AI pipeline for identifying violating comments. Our pipeline includes 97 subreddit classifiers that are trained using a balanced dataset of moderated and unmoderated comments, and human annotators who are trained through gated instruction.
Annotation and Crowd-Sourced Validation
A critical component of the pipeline is the use of crowd-sourced annotators from Amazon Mechanical Turk, who undergo a rigorous training and testing phase. The annotators are tasked with verifying whether flagged comments violate any of the eight macro norms identified for the study. This approach ensures the accurate classification of comments while maintaining the scalability of the annotation process.

Figure 2: Interface for introducing the task description and eight macro norms to a new annotator. The interface is used for training and testing.
Estimation Using Bootstrap Sampling
To capture the uncertainty inherent in the sampling and classification process, the authors apply a bootstrap sampling technique. This method enables the estimation of the proportion of unmoderated comments violating community norms across multiple simulations, thus providing robust confidence intervals for the rate of norm violations. The results indicate that a significant proportion of comments remain unmoderated, with moderators catching only a fraction of the violations.
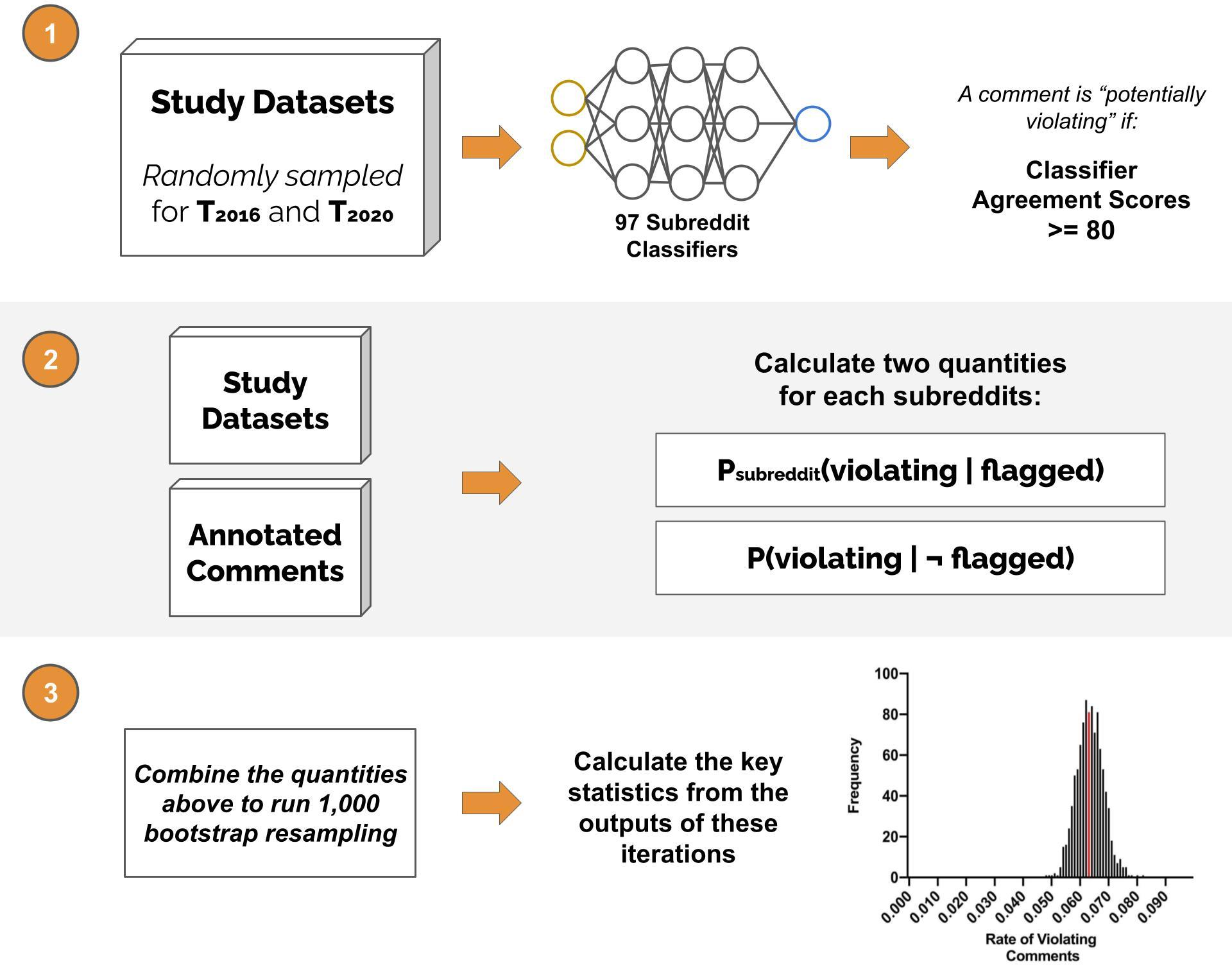
Figure 3: An overview of the sampling process in broad strokes. We start by randomly sampling unmoderated comments from T2016.
Results and Key Findings
The empirical findings reveal that approximately 6.25% of comments in 2016 and 4.28% in 2020 violated the macro norms of Reddit. Personal attacks emerged as the most prevalent form of norm violation, while politically inflammatory comments and misogyny/vulgarity were among the least moderated. The study highlights gaps in current moderation practices and suggests that automated tools need further refinement to assist human moderators effectively.
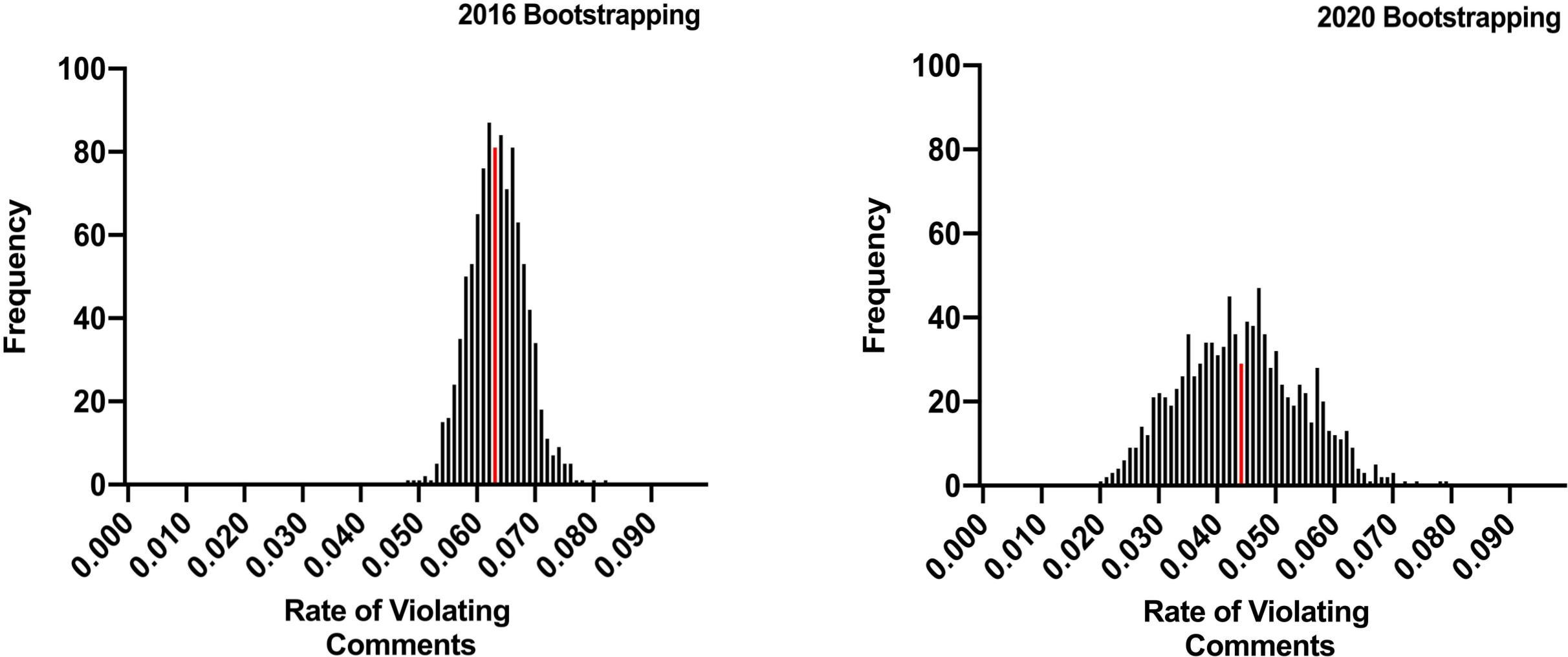
Figure 4: The results of our bootstrap sampling. The figures show the overall rates of violating comments that are left unmoderated for all 1,000 simulations of Reddit for T2016.
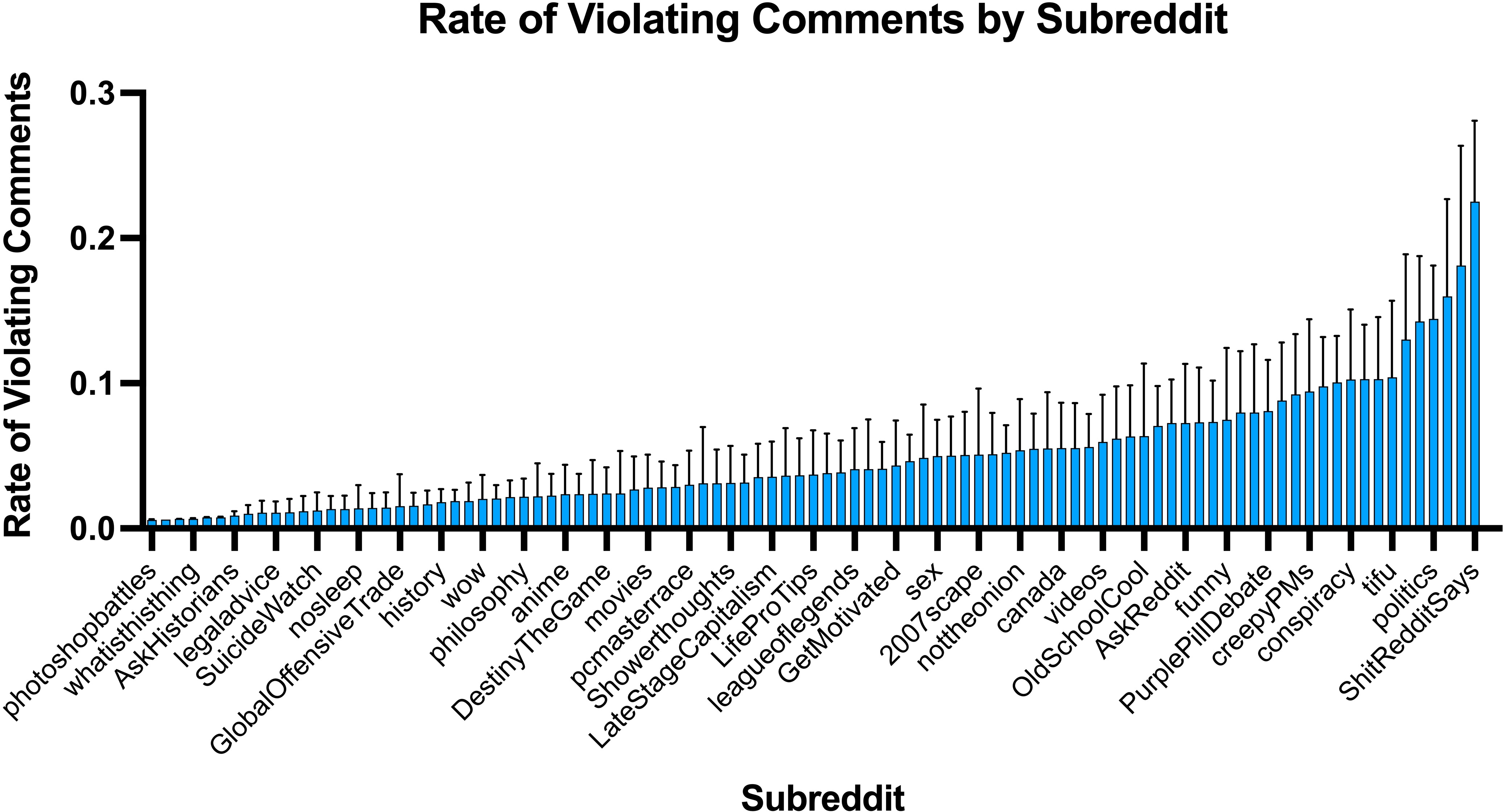
Figure 5: Rate of macro norm violations by subreddit.
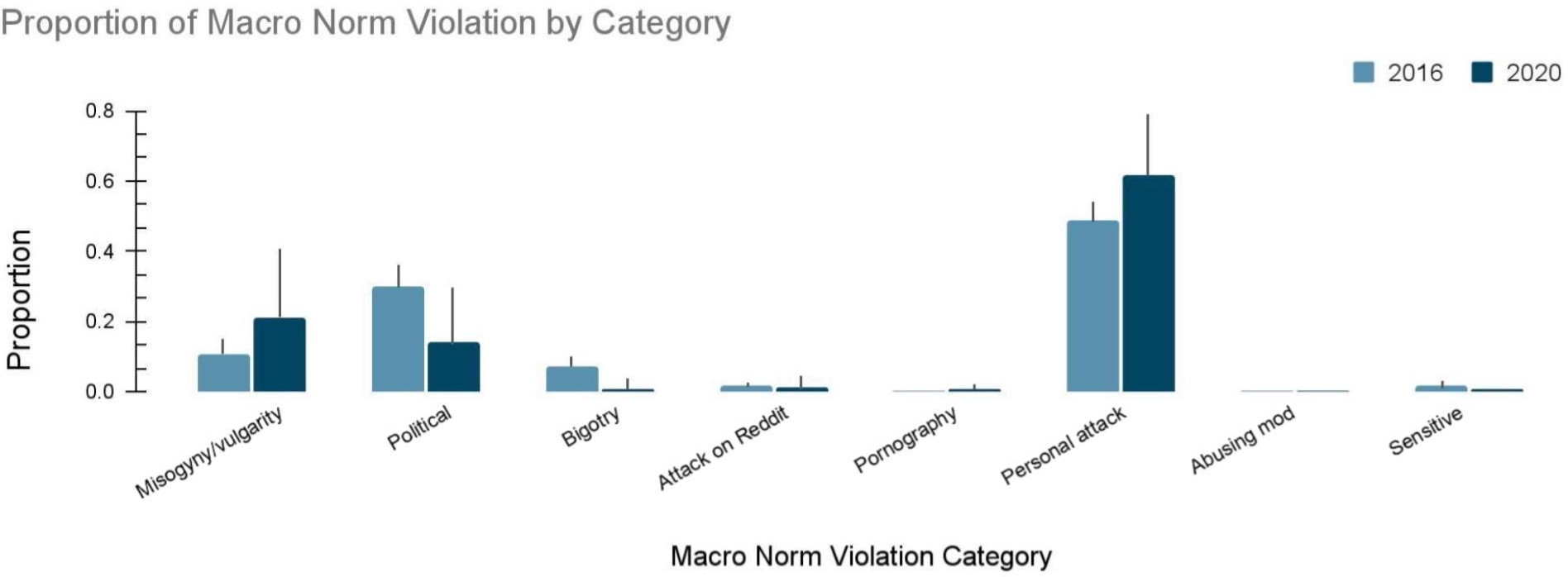
Figure 6: The proportion of macro norm violations by the eight categories among the unmoderated problematic comments according to our annotators.
Implications and Future Directions
The study provides a critical methodological framework for measuring anti-social behavior online, with significant implications for platform policy and design. The results underscore the need to enhance both automated detection algorithms and community-based moderation strategies. Future research could explore the integration of more advanced NLP techniques to capture contextual nuances and further test the pipeline on platforms with diverse moderation cultures.
Conclusion
"Measuring the Prevalence of Anti-Social Behavior in Online Communities" makes a substantial contribution to the literature on content moderation and anti-social behavior in online spaces. By providing a scalable, validated approach for identifying and quantifying norm-violating content, the study offers valuable insights for platform designers, policymakers, and researchers striving to create safer online environments.