Explicit Tradeoffs between Adversarial and Natural Distributional Robustness
Abstract: Several existing works study either adversarial or natural distributional robustness of deep neural networks separately. In practice, however, models need to enjoy both types of robustness to ensure reliability. In this work, we bridge this gap and show that in fact, explicit tradeoffs exist between adversarial and natural distributional robustness. We first consider a simple linear regression setting on Gaussian data with disjoint sets of core and spurious features. In this setting, through theoretical and empirical analysis, we show that (i) adversarial training with $\ell_1$ and $\ell_2$ norms increases the model reliance on spurious features; (ii) For $\ell_\infty$ adversarial training, spurious reliance only occurs when the scale of the spurious features is larger than that of the core features; (iii) adversarial training can have an unintended consequence in reducing distributional robustness, specifically when spurious correlations are changed in the new test domain. Next, we present extensive empirical evidence, using a test suite of twenty adversarially trained models evaluated on five benchmark datasets (ObjectNet, RIVAL10, Salient ImageNet-1M, ImageNet-9, Waterbirds), that adversarially trained classifiers rely on backgrounds more than their standardly trained counterparts, validating our theoretical results. We also show that spurious correlations in training data (when preserved in the test domain) can improve adversarial robustness, revealing that previous claims that adversarial vulnerability is rooted in spurious correlations are incomplete.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at two kinds of “toughness” (robustness) for AI image classifiers:
- Adversarial robustness: staying accurate even when an attacker makes tiny, sneaky changes to the input.
- Natural distributional robustness: staying accurate when the real world looks different from the training data (for example, different backgrounds, viewpoints, or lighting).
The main message: there is a clear tradeoff between these two. Training a model to resist attacks can make it rely more on “spurious” clues (like backgrounds), which can hurt its performance in the real world when those clues change.
What questions did the researchers ask?
They asked:
- Does adversarial training (training to resist attacks) make models depend more on spurious features (like background or texture) instead of core features (the actual object)?
- Does this increased spurious reliance reduce robustness to real-world changes (like different backgrounds)?
- Does the type of attack the model is trained against matter?
- Can spurious features ever help adversarial robustness?
How did they study it?
They used two approaches: a simple math model to understand “why,” and large experiments to test “how often” it happens.
Key ideas in simple language
- Core vs spurious features:
- Core features: what truly defines the object (e.g., the shape of a dog).
- Spurious features: shortcuts that often correlate with the object but aren’t actually what makes it that object (e.g., a typical background where dogs are photographed).
- Adversarial training:
- The model practices on cleverly perturbed (barely changed) images designed to fool it. The goal is to learn to resist such attacks.
- “Norms” (, , ):
- Think of an attacker having a limited “budget” of changes. Different norms are different rules for how the attacker can spend that budget.
- and : Spending the budget over many features hurts more (spreading it thin).
- : The attacker can bump every feature a little bit up to the same maximum amount.
The simple math model (high-level)
- The authors studied a basic linear predictor (a weighted sum of features) on fake, cleanly designed data that separates core and spurious features.
- They rewrote the adversarial training objective in a way that shows exactly how the model’s weights and the attack budget interact.
- Insight: if the model uses more features (including spurious ones), an attacker with limited budget must spread their changes across more directions, making each change weaker. This can motivate the model to use spurious features during adversarial training.
- Exception with : since the attacker can bump all features up to the same small maximum, using spurious features helps only when those spurious signals are “larger” (stronger scale) than the core ones.
The large experiments
They tested 20 adversarially trained ImageNet models (ResNet-18 and ResNet-50 backbones; trained with or attacks at different strengths) across several datasets that diagnose spurious reliance:
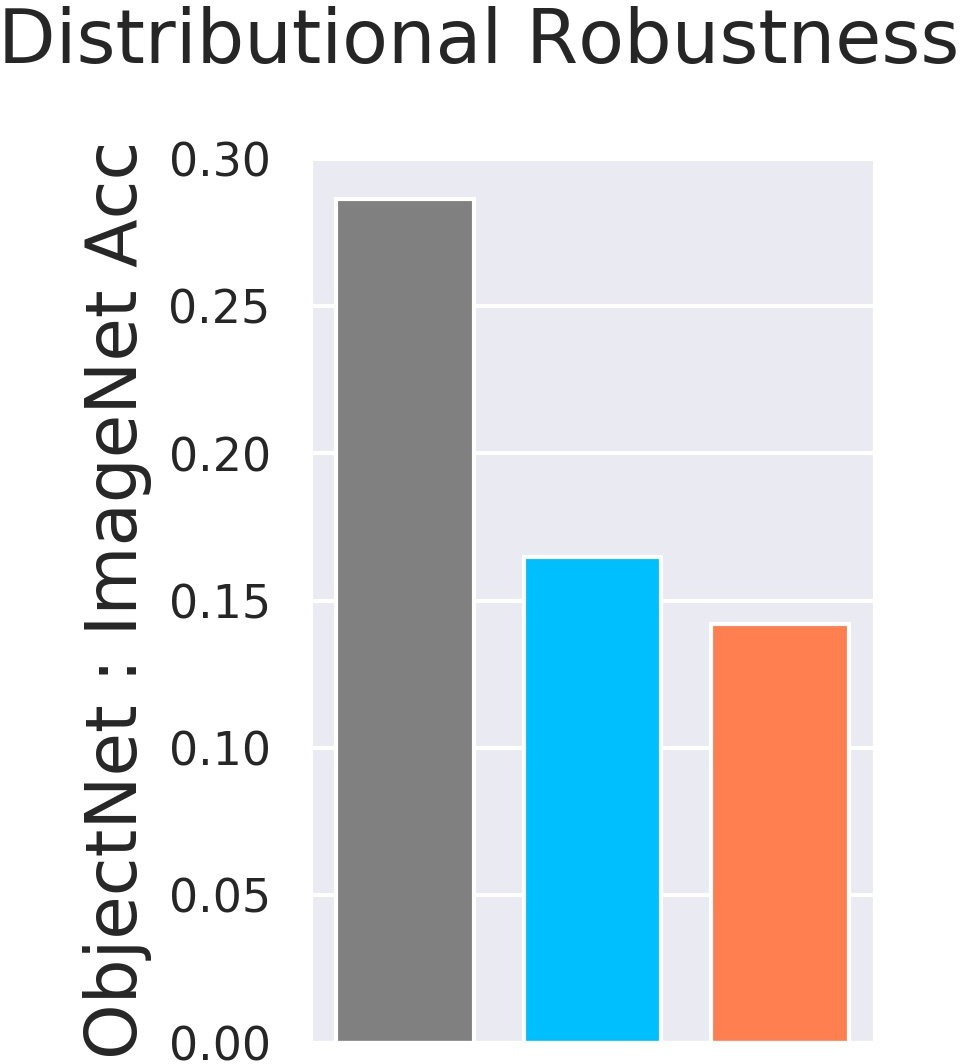
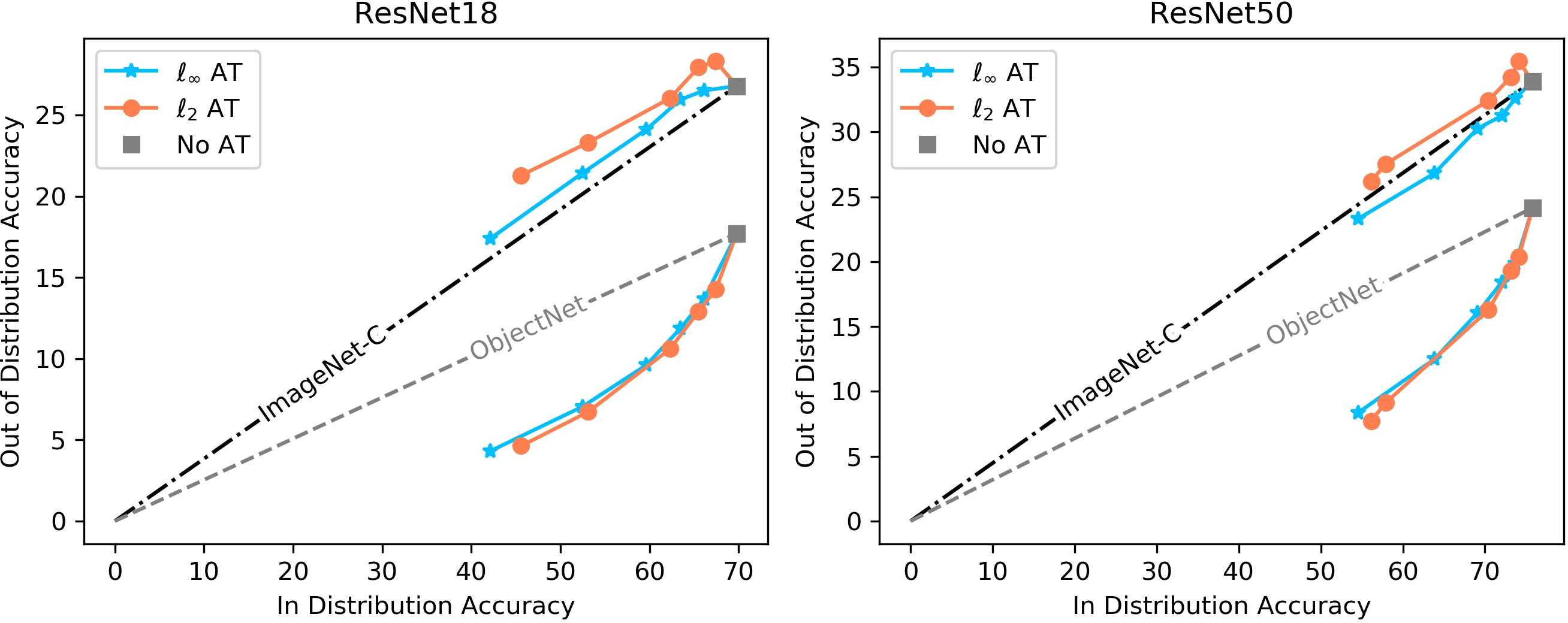
- ObjectNet: same objects, different real-world settings (backgrounds, viewpoints).
- ImageNet-C: common corruptions (blur, noise). These don’t specifically break background-object correlations.
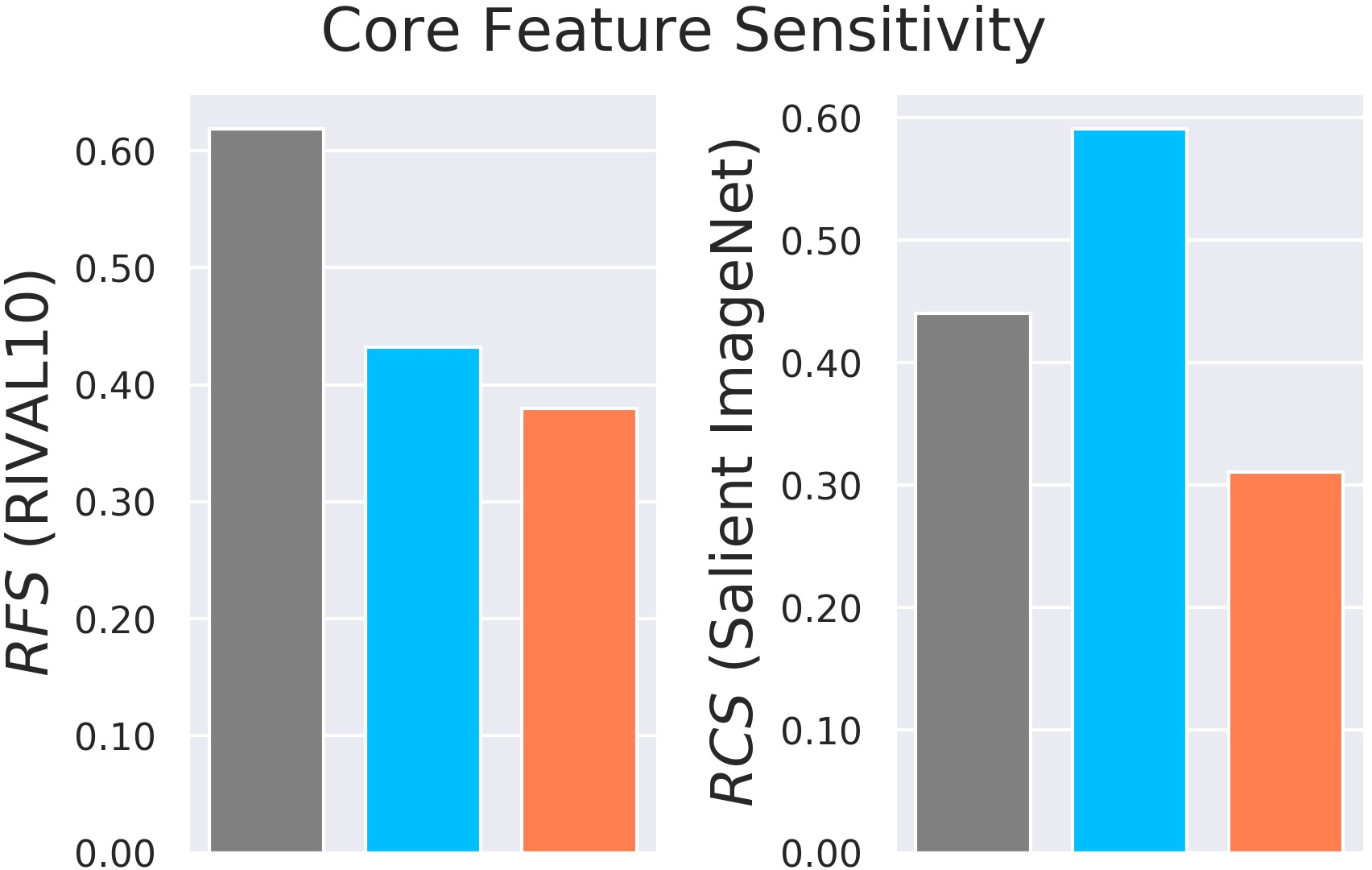
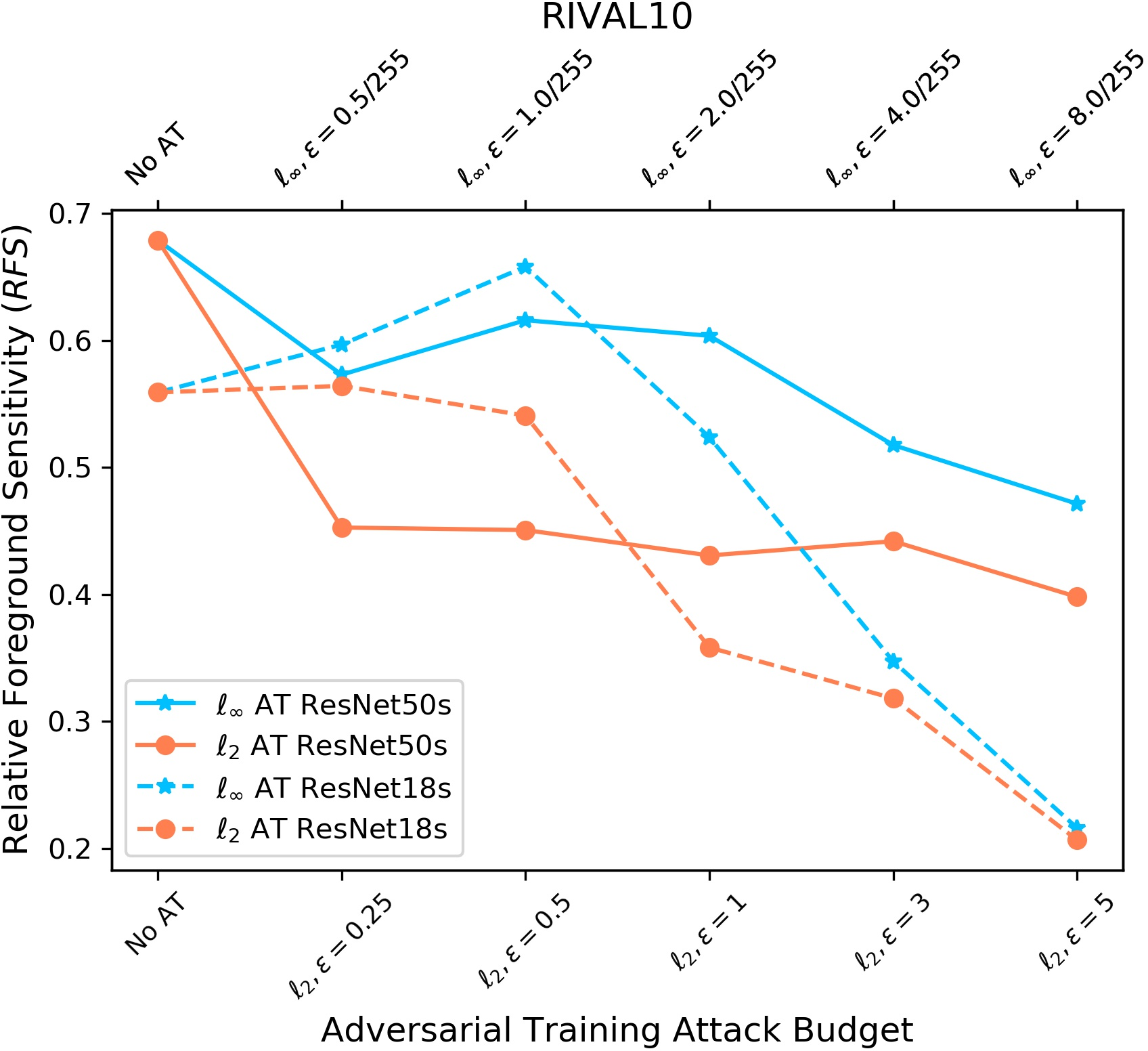
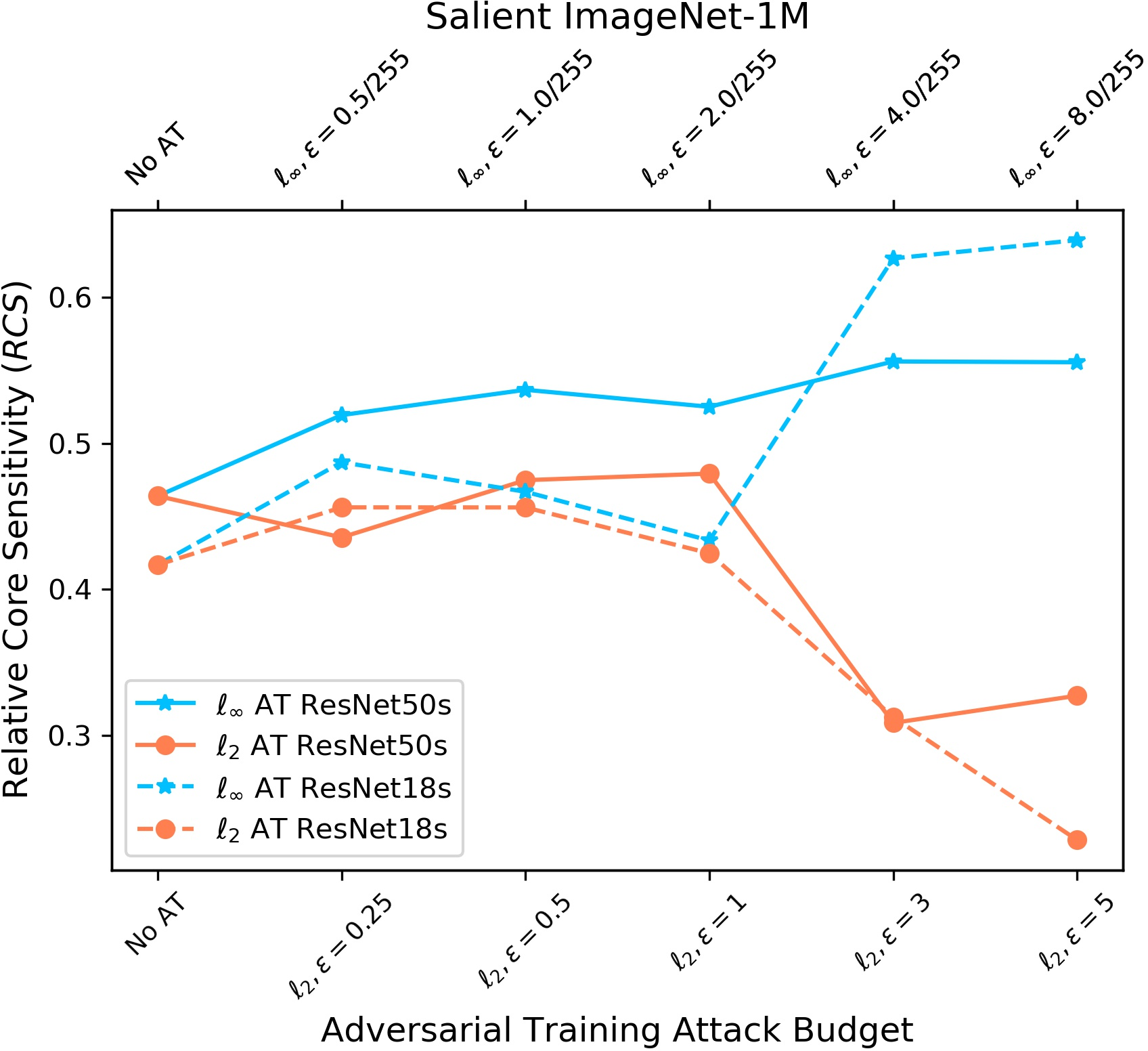
- Salient ImageNet-1M and RIVAL10: measure how sensitive models are to core vs background regions by adding noise to those areas.
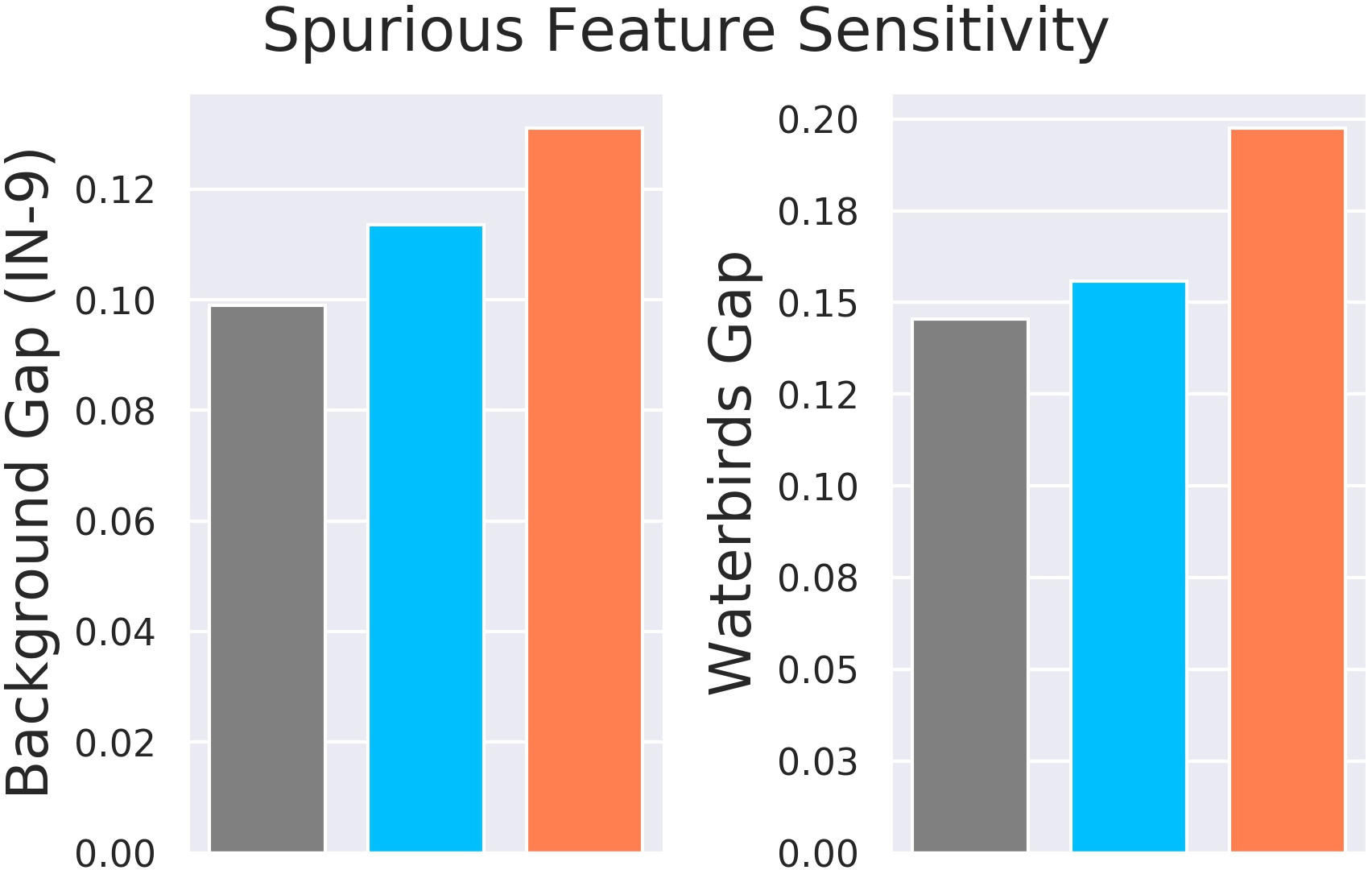
- ImageNet-9: swaps backgrounds to see how much the model relies on them.
- Waterbirds: deliberately mixes birds with mismatched backgrounds to see if the model follows the bird or the background.
They measured:
- Relative core sensitivity (RCS) and relative foreground sensitivity (RFS): how much the model depends on the core object versus the background.
- Background gap: how much accuracy drops when backgrounds are swapped across classes.
- Majority vs minority group accuracy: how much performance falls when the usual background-object pairing is broken.
What did they find, and why is it important?
Main findings:
- Adversarial training with or pushes models to rely more on spurious features. Why? Because using extra features (including spurious ones) forces an attacker to spread their limited budget, making each change less effective.
- With adversarial training, this spurious reliance happens mainly when spurious features are “larger” (stronger) than core features. If not, the model doesn’t necessarily use spurious features more.
- Adversarially trained models often become less robust to real-world shifts that break spurious correlations (like different backgrounds). For example:
- On ObjectNet (different backgrounds/viewpoints), adversarially trained models drop more than standard models, even after accounting for their lower base accuracy.
- On ImageNet-C (noise/blur), where background correlations stay intact, adversarially trained models don’t suffer extra.
- On ImageNet-9 and Waterbirds, adversarially trained models show a bigger drop when backgrounds are changed or mismatched. This effect is stronger for training than .
- On Salient ImageNet-1M and RIVAL10, adversarial training reduces sensitivity to core features versus spurious ones (RCS and RFS go down).
- Surprise: spurious features can sometimes improve adversarial robustness. In a controlled CIFAR-10 experiment, adding a consistent color “shift” as a spurious cue (and keeping it in the test set) actually made models more attack-resistant. This shows the relationship between spuriousness and adversarial vulnerability is more complicated than “spurious = bad.”
Why this matters:
- Many real-world failures happen because models rely on shortcuts like background or texture. If adversarial training increases shortcut use, it can make models less reliable in new environments, even while they get better at resisting tiny, crafted attacks.
What is the impact of this research?
- It highlights a hidden tradeoff: making models safer against adversarial attacks can make them less stable in the real world when spurious cues change.
- It urges a broader view of robustness. We shouldn’t optimize for only one type (like adversarial) without checking the other (natural distribution shifts).
- Practical takeaways:
- Evaluate models on both adversarial and natural distribution shifts (e.g., ObjectNet, ImageNet-9, Waterbirds), not just clean accuracy.
- Be cautious: adversarial training tends to increase spurious reliance more than , especially when spurious cues are strong.
- Data collection should reduce spurious correlations or vary them widely (diversity in backgrounds, viewpoints) so the model learns to trust core features.
- When spurious cues are unavoidable, be aware they might help adversarial robustness in the short term but hurt real-world reliability when the environment changes.
- Future work: create training methods that jointly promote both adversarial and natural distributional robustness, and develop diagnostics that track spurious reliance during training.
In short: defending against one kind of brittleness (adversarial attacks) can accidentally make another kind worse (real-world shifts). This paper shows when, why, and how that happens—and what to watch for.
Collections
Sign up for free to add this paper to one or more collections.