- The paper presents a novel VSD task focusing on spatial relationships in images, offering a controlled image-to-text generation method.
- It employs encoder-decoder models based on VL-BART and VL-T5, integrating VSRC through pipeline and end-to-end strategies to enhance performance.
- Results show that end-to-end training using gold-standard spatial relations significantly improves BLEU-4 and SPICE metrics.
Visual Spatial Description: Controlled Spatial-Oriented Image-to-Text Generation
The paper "Visual Spatial Description: Controlled Spatial-Oriented Image-to-Text Generation" focuses on a new task in image-to-text generation named Visual Spatial Description (VSD). This task aims to describe spatial semantics between objects in an image, advancing beyond general image captioning towards more controlled, spatially-oriented text generation. The paper introduces benchmark models utilizing encoder-decoder architectures based on VL-BART and VL-T5, explores the integration of Visual Spatial Relationship Classification (VSRC) for enhancing VSD, and details the creation of a bespoke dataset for task benchmarking.
Introduction to the Task
Traditional image-to-text tasks encompass diverse forms such as generic open-ended image captioning, verb-specific semantic roles guided captioning, and visual question answering. VSD diverges from these by emphasizing spatial semantics, a crucial aspect in human cognition for spatial-based applications like navigation and unmanned manipulation. VSD requires generating descriptions that detail the spatial relationships between specified objects within an image, addressing a gap in the current controllable image description approaches.

Figure 1: A comparison of three example image-to-text generation tasks and the proposed VSD in this work.
Dataset Annotation and Collection
A key contribution of the paper is the creation of a dataset specifically curated for the VSD task. Leveraging existing datasets like SpatialSense and VisualGenome, the authors annotate a final corpus that contains both VSRC and VSD annotations. The dataset construction involves careful guidelines to ensure correct spatial semantics and object localization within a description, maintaining high annotation quality through rigorous checks.

Figure 2: The data annotation flow.
Model Architectures
The proposed models for VSD employ a multi-modal encoder-decoder based on Transformer architectures, specifically VL-BART and VL-T5. These models integrate spatial relationships through VSRC using pipeline and joint end-to-end strategies, enriching spatial semantics in generated text.
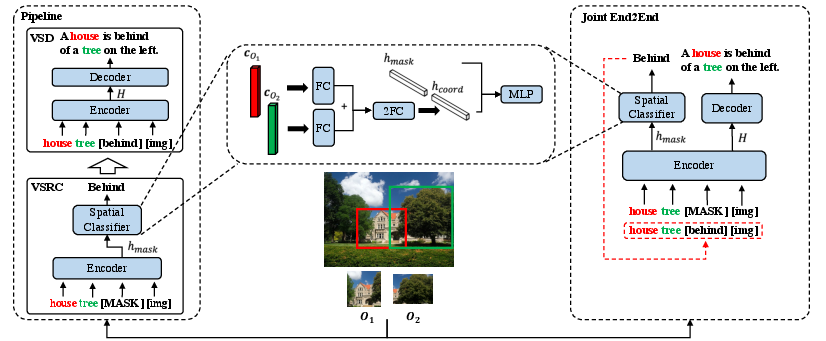
Figure 3: Overview of our pipeline and end-to-end models with VSRC, where FC denotes fully-connected network.
Enhancement through VSRC
Enhancing VSD with VSRC involves two architectures:
- Pipeline Strategy: Spatial relation is first classified and then used as an additional input for the VSD encoder.
- End-to-End Joint Strategy: This employs multi-task learning to integrate VSRC in a single model schema, allowing natural task interaction and reducing error propagation.
The results demonstrate that the end-to-end model is more effective than the pipeline model in utilizing spatial relations. Additionally, having gold-standard spatial relations significantly boosts performance, though impractical in real-world applications due to dependency on automatically predicted relations.
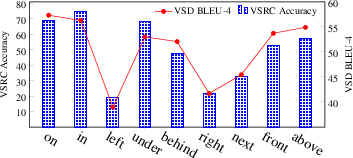
Figure 4: Fine-grained results of the VL-T5+VSRC-end2end model in terms of spatial relations.
Experiments and Results
Extensive experiments are conducted to evaluate both the pipeline and end-to-end models. As primary metrics, BLEU-4 and SPICE are chosen for syntactic and semantic quality measurement, respectively. The VL-T5 model exhibited better spatial understanding performance when equipped with VSRC information. The superiority of the end-to-end approach is illustrated, particularly on test samples where VSRC predictions are accurate.
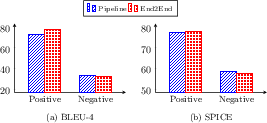
Figure 5: VSD results of VL-T5+VSRC-end2end by positive and negative relations predicted from VSRC.
Implications and Future Work
The introduction of VSD has implications in enhancing automatic navigation, perception assistance, and dialogue systems, where spatial understanding is fundamental. Future directions include expanding the dataset with more spatial relations, improving diversity in description styles, and exploring models that address compound spatial relations.
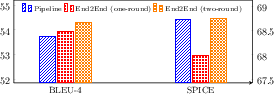
Figure 6: A comparison of the VL-T5+VSRC-end2end model by using one-round and two-round decodings.
Conclusion
VSD represents an advancement in spatial-oriented image-to-text generation, with integrated VSRC models proving capable of enriching spatial descriptions. This paper lays the groundwork for future research in image semantics and controlled text generation, fostering applications demanding spatial cognition.

Figure 7: Case studies, where the object in an image marked by the red box is the first object of VSD input, and the bold orange descriptions are regarded as relatively acceptable.