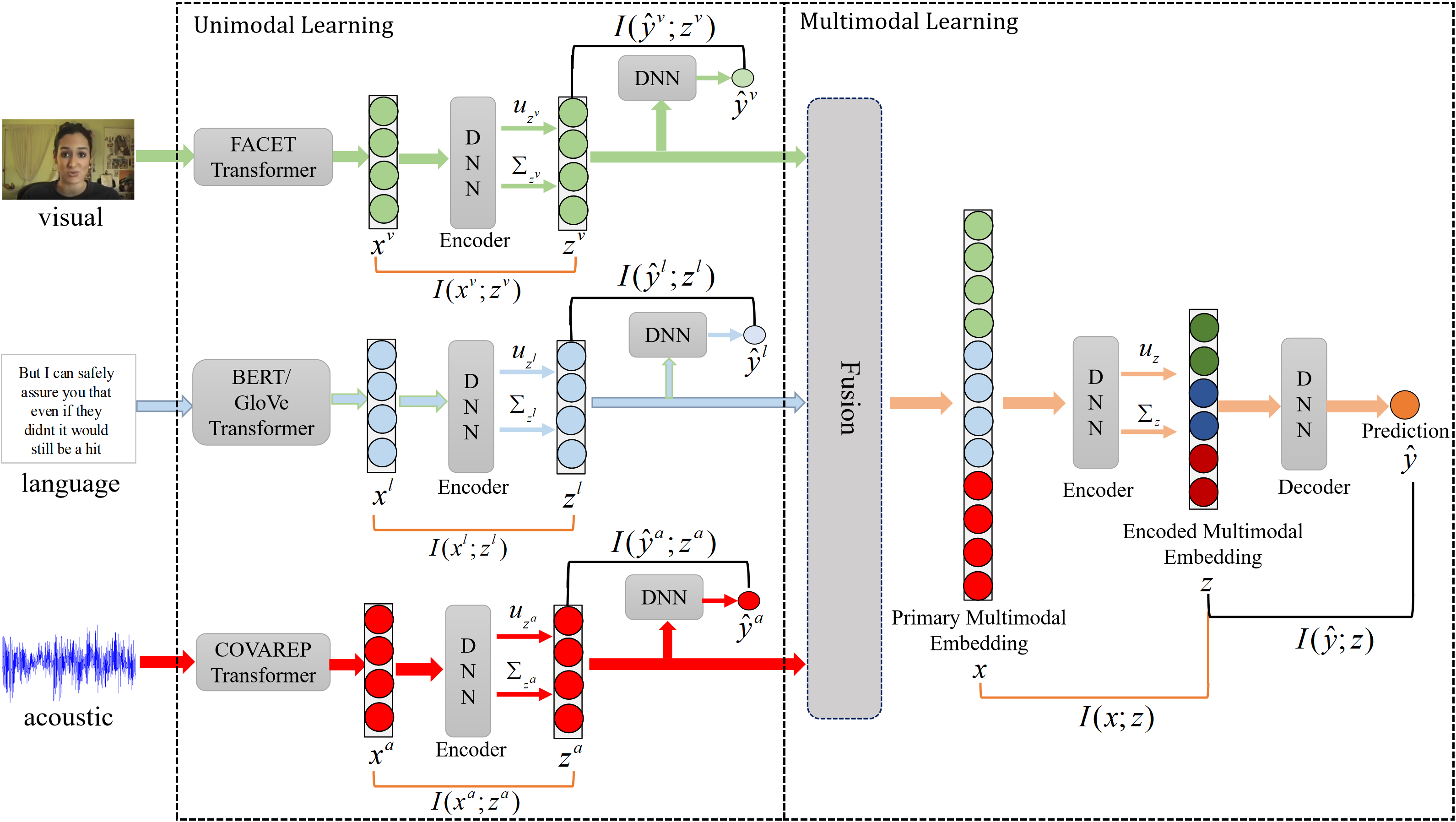
- The paper presents MIB, which applies the information bottleneck principle to generate minimal sufficient unimodal and multimodal embeddings that reduce redundant and irrelevant information.
- It introduces E-MIB, L-MIB, and C-MIB variants that optimize fusion strategies by maximizing mutual information between embeddings and task labels.
- Experimental results on CMU-MOSI and CMU-MOSEI show that the comprehensive C-MIB approach outperforms state-of-the-art models in sentiment analysis and emotion recognition.
The paper "Multimodal Information Bottleneck: Learning Minimal Sufficient Unimodal and Multimodal Representations" introduces the Multimodal Information Bottleneck (MIB) framework, optimizing unimodal and multimodal embeddings for sentiment analysis and emotion recognition. MIB enhances representation utility by minimizing redundancy and noise, using mutual information maximization for task relevance. This essay summarizes the framework's architecture, experimental efficacy, and its implications for AI.
Introduction
The MIB framework addresses multimodal learning challenges in machine learning, such as redundant information in combined embeddings, unimodally noise-filled information, and the oversight of crucial cross-modal dynamics. To this end, MIB extends traditional information bottleneck (IB) methods by focusing on both unimodal and multimodal embeddings, optimizing them using mutual information principles.
Framework Overview
Key Components
- Information Bottleneck (IB) Principle: MIB leverages the IB principle to promote minimal sufficient embedding, maintaining maximum relevance to target predictions while minimizing non-contributive information. This is achieved by maximizing mutual information between embeddings and labels and minimizing it between embeddings and input data.
- MIB Variants:
- Early-Fusion MIB (E-MIB): This version first combines unimodal features into a primary multimodal representation and then applies the IB principle to create an optimized combined representation.
- Late-Fusion MIB (L-MIB): Operates by first optimizing unimodal embeddings individually using the IB principle before fusion into a multimodal representation.
- Complete MIB (C-MIB): A comprehensive approach combining E-MIB and L-MIB, applying IB constraints on both unimodal and multimodal levels for maximum efficiency.
Implementation Details
Architecture
- Unimodal and Multimodal Fusion Networks: These networks handle respective modality encoding and later fusion. They are flexible and can incorporate various fusion mechanisms, ensuring compatibility with different multimodal datasets.
Optimization
Experimental Evaluation
Experimental results across datasets like CMU-MOSI and CMU-MOSEI demonstrate MIB's prowess. The framework consistently surpasses state-of-the-art models in metrics like accuracy, F1 score, and MAE across both sentiment analysis and emotion recognition tasks.
Fusion Strategy Evaluation
Evaluations reveal that C-MIB, with its comprehensive inclusion of IB on all fusion stages, generally outperforms isolated strategies like E-MIB or L-MIB when fusion sophistication increases. Tensor fusion demonstrated superior results across configurations due to high expressive potential, showing MIB's flexibility in leveraging advanced representation techniques.
Implications and Future Work
MIB's integration of mutual information principles into multimodal learning marks a significant stride in AI's pursuit of efficient, noise-resistant cross-modal representations. Future research may focus on enhancing the scalability of MIB, particularly in real-time applications, and exploring its adaptability to more complex and novel datasets.
Conclusion
The Multimodal Information Bottleneck framework is pivotal in evolving multimodal learning paradigms, focusing on utility-maximized, minimal noise embeddings. Its flexibility and performance viability offer fertile ground for further explorations in sentiment analysis, emotion recognition, and beyond.