- The paper applies Data Envelopment Analysis to quantify the resource-performance trade-off in NLP models using efficiency scores derived from inputs such as training time and parameters.
- It demonstrates that while transformer models offer high performance, they require extensive resources, whereas simpler models provide efficiency under constrained conditions.
- The study compares CCR and BCC models to highlight scale inefficiencies in large models, encouraging adaptive resource allocation for optimized model selection.
Introduction
"Assessing Resource-Performance Trade-off of Natural LLMs using Data Envelopment Analysis" addresses the challenge of comparing NLP models based on both performance and resource utilization by applying Data Envelopment Analysis (DEA). DEA is a nonparametric method traditionally used in operations research to measure efficiency. In this context, NLP models are evaluated as Decision Making Units (DMUs), with resources like training time and parameter count serving as inputs and performance metrics as outputs. This methodology allows for the identification of models that lie on an efficient frontier, balancing high performance with minimal resource expenditure.
Methodology
Data Envelopment Analysis (DEA)
DEA transforms the evaluation problem into one where each NLP model is treated as a DMU. Inputs for the DEA include model hyperparameters like the number of trainable parameters and training time, while outputs are performance metrics such as accuracy or evaluation scores. The key feature of DEA is its ability to create an efficient frontier, composed of models that offer the best resource-performance balance.
DEA uses linear programming to compute efficiency scores for each DMU. The analysis provides a scalar efficiency score for each model, identifying those that are on the Pareto front of efficiency.
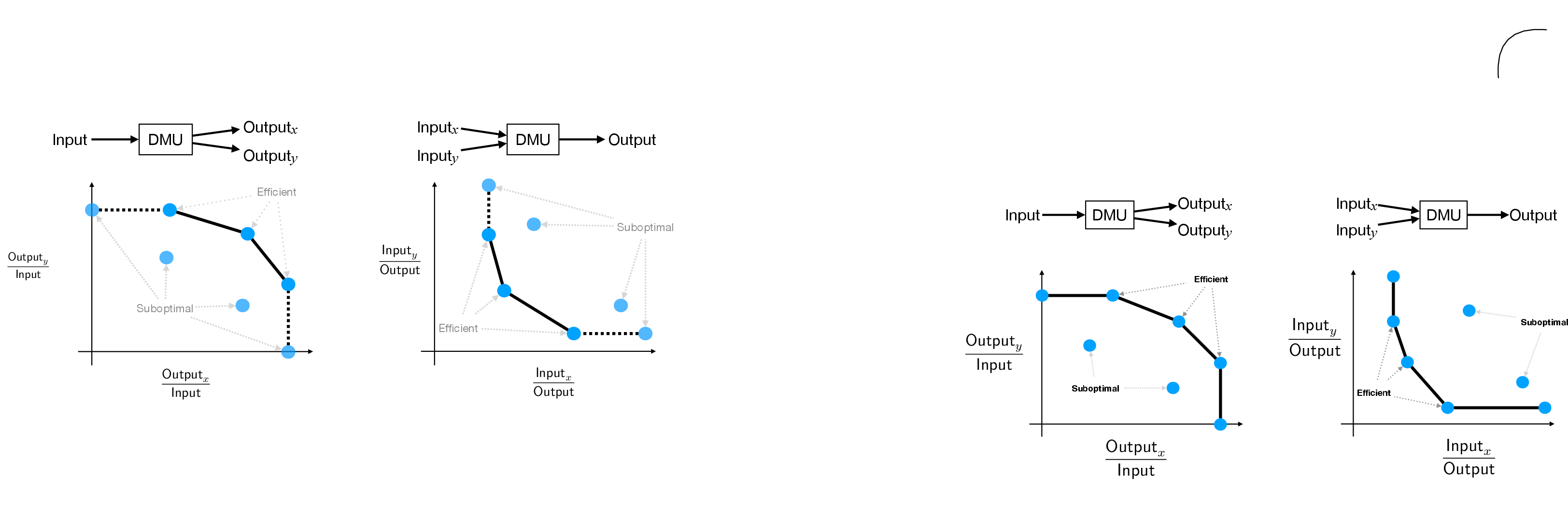
Figure 1: Two simple examples of DEA illustrating DMUs distributed relative to input and output axes, with efficient DMUs indicated by the Pareto front.
Setup and Implementation
The authors evaluate fourteen different models using DEA, incorporating both simple models and sophisticated transformer-based architectures. The analysis considers high-dimensional metric spaces defined by multiple inputs and outputs. For example, inputs could be training corpus size and computational resources, while outputs are task-specific performance scores.
Efficiency Models
The CCR (Charnes, Cooper, and Rhodes) model assumes constant returns to scale, which may not be appropriate for all machine learning models. This was addressed by adapting the BCC (Banker, Charnes, and Cooper) model, allowing for variable returns to scale. Both models are used to calculate efficiency scores, which then inform the selection of efficient models.
Results
The empirical evaluation reveals several key insights:
- Efficiency Scores: DEA identified specific models, such as those with GloVe embeddings and certain variants of RoBERTa, as lying on the efficient frontier. These models provide a favorable balance between performance and resource consumption.
- Comparison and Trade-offs: The analysis shows that transformer models generally have high performance but are resource-intensive. Conversely, simpler models like TF-IDF provide more efficiency in low-resource settings without reaching the high performance of transformers.
- Scale Efficiency: When comparing CCR and BCC models, scale efficiency indicates the degree of efficiency lost due to scale inefficiencies. Results suggest that large models like BERT-large tend to exhibit decreasing returns to scale.
Implications and Future Work
The application of DEA to NLP model evaluation introduces a valuable perspective on resource-performance trade-offs. It emphasizes that not all incremental improvements in model performance are justified by the increased resource requirements. This work encourages a broader adoption of efficiency measures in model selection.
Future research could refine the DEA framework by exploring alternative sets of inputs and outputs, and by employing output-oriented models. The potential integration of DEA into the model training pipeline could facilitate adaptive resource allocation strategies, optimizing training efficiency dynamically based on real-time analysis.
Conclusion
The paper demonstrates the feasibility and value of using DEA to assess the resource-performance trade-offs of NLP models. By applying DEA, the authors effectively identify LLMs that offer a well-balanced compromise between performance and resource expenditure. This approach not only aids model comparison and selection but also provides a meaningful path forward for optimizing NLP models in resource-constrained environments.