- The paper introduces an M-to-N backdoor paradigm that simultaneously attacks multiple classes using several unique triggers, achieving high attack success rates.
- The methodology employs a poisoned image generation framework with trigger embedding, recovery, and discriminator networks to ensure high stealth and robustness.
- Experimental results across datasets like MNIST, CIFAR-10, and GTSRB demonstrate near-perfect success with minimal poisoning and strong resistance to pre-processing defenses.
M-to-N Backdoor Paradigm: A Multi-Trigger and Multi-Target Attack to Deep Learning Models
Introduction
Backdoor attacks on deep neural networks (DNNs) exploit vulnerabilities by embedding hidden triggers, causing models to misbehave when these triggers are activated. Traditional backdoor attacks typically focus on a single target, limiting their effectiveness in scenarios where the attacker lacks precise knowledge about target labels. This paper introduces the M-to-N backdoor attack paradigm, a novel approach allowing attackers to simultaneously target multiple classes in deep learning models, with each target activated by multiple triggers. This paradigm addresses the limitations of traditional attacks and offers higher stealth and effectiveness.
Attack Paradigm and Implementation
Multi-Target and Multi-Trigger Approach
The M-to-N backdoor attack paradigm is designed to inject backdoors into DNN models by attacking multiple suspected targets simultaneously. For each target, M unique triggers are selected from clean images corresponding to the target label. Each trigger has a distribution similar to clean images, enhancing stealth by making the poisoned inputs and backdoor models indistinguishable from their benign counterparts. This approach contrasts prior single-target attacks by simultaneously targeting N classes, increasing the likelihood of achieving the attacker's goals in complex classification tasks.
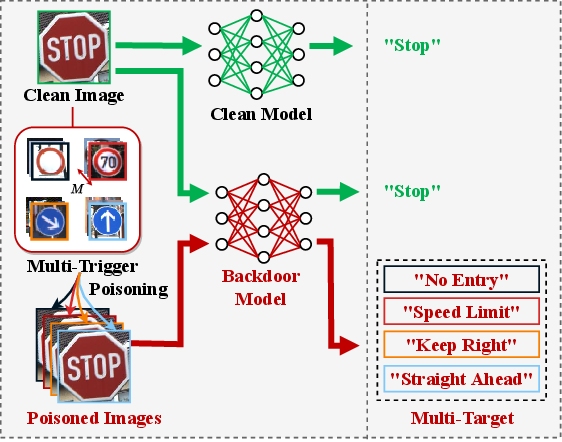
Figure 1: An example of our M-to-N backdoor attack about traffic sign classification. An input sign Stop'' can be misclassified as the target labelNo Entry'', Speed Limit'',Keep Right'', or ``Straight Ahead'' when poisoning the sign with a trigger that corresponds to the target label. Note that the backdoor of each target can be activated by any one of its M triggers.
Poised Image Generation Framework
The attack uses a novel poisoned image generation framework comprising three networks: trigger embedding, recovery, and discriminator networks. The embedding network embeds triggers into clean images, ensuring the resulting poisoned images are visually similar to clean images. The recovery network checks for successful trigger extraction, while the discriminator network assists in maintaining high-quality, indistinguishable outputs. This framework prevents introducing external features into training datasets, increasing the backdoor attack's robustness and evasiveness against defenses.
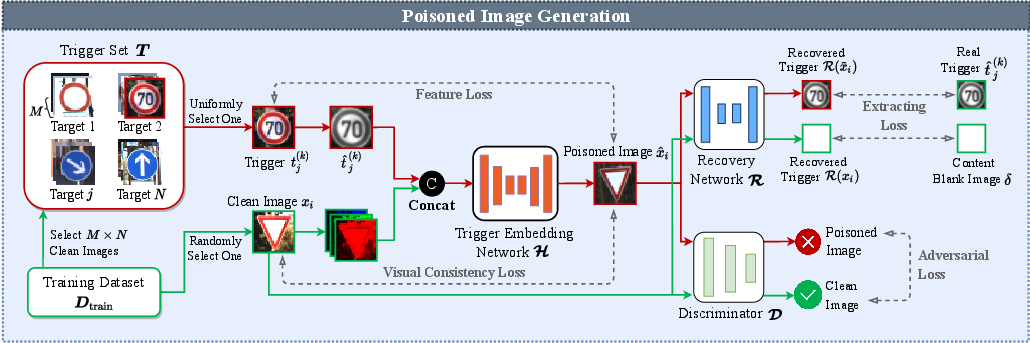
Figure 2: The schematic diagram of our poisoned image generation framework.
Backdoor Injection Process
The backdoor injection process involves constructing a poisoned training dataset by replacing select clean samples with poisoned samples, utilizing triggers uniformly. This method is beneficial in third-party training scenarios, leveraging outsourced servers to embed backdoors effectively. The dNN model trained on this dataset can output attacker-specified results when triggered, retaining original accuracy with clean inputs.
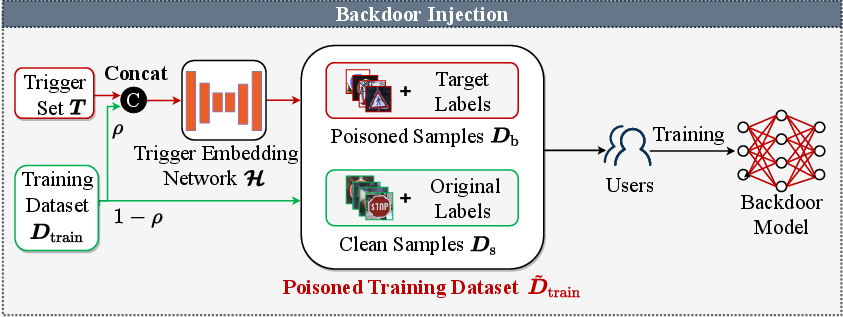
Figure 3: The process of our backdoor injection.
Experimental Results
Experiments demonstrate the efficacy of the M-to-N attack paradigm across different datasets including MNIST, CIFAR-10, and GTSRB. With extensive trials over varying numbers of targets and triggers, it achieves near-perfect attack success rates (ASR) with minimal training set poisoning (around 2-10%). Comparisons with existing methods highlight superior performance and generalizability across diverse models and tasks.
Stealthiness
Stealthiness is measured both qualitatively and quantitatively. Visual inspection confirms that poisoned images maintain high similarity with clean counterparts, evidenced by negligible noticeable differences. Metrics such as PSNR, SSIM, and LPIPS affirm high stealth levels, showing that poisoned images are indistinguishable in appearance and structure. This stealth is maintained even when multiple targets are attacked simultaneously.

























Figure 4: Visual effects of the poisoned images in our M-to-N backdoor attack (1-to-4 attack in the left and 4-to-1 attack in the right). (a) Original images; (b) the poisoned images for four targets; (c) residuals of (a) and (b); (d) four triggers for generating (b); (e) the poisoned images for a single target with four different triggers; (f) residuals of (a) and (e); (g) four triggers for generating (e).
Robustness Against Pre-processing
The M-to-N attack paradigm exhibits robust resistance to common image pre-processing operations such as rotation, blurring, and resizing, while retaining high ASR. This robustness further validates the effectiveness of using clean image-derived triggers, preventing feature alterations during pre-processing that could defeat traditional single-trigger attacks.










Figure 5: Generated poisoned images. The top row shows the poisoned images, while the bottom row indicates the residuals between the poisoned and clean images.
Defenses and Resistance Analysis
Evasion of Advanced Defenses
The M-to-N paradigm effectively circumvents state-of-the-art defenses such as Fine-Pruning, Neural Cleanse, STRIP, and SentiNet, maintaining high levels of accuracy and attack success without detection. By utilizing dynamic clean-feature triggers distributed across entire images, the paradigm avoids reverse engineering and feature-based detection strategies employed by these defenses.






Figure 6: Visual effects of different pre-processing operations. (a) None; (b) Flipping; (c) Rotation; (d) Shrinking{additional_guidance}Padding; (e) Cropping{additional_guidance}Resizing; (f) Gaussian noise blurring.
Comparisons with Previous Methods
Compared with traditional WyNet and Input-Aware methods, M-to-N offers enhanced stealth and flexibility, effectively attacking multiple targets while evading detection. The paradigm surpasses One-to-N backdoor attacks in ASR, unaffected by multiple target attacks, showcasing improved robustness and adaptability in complex scenarios.
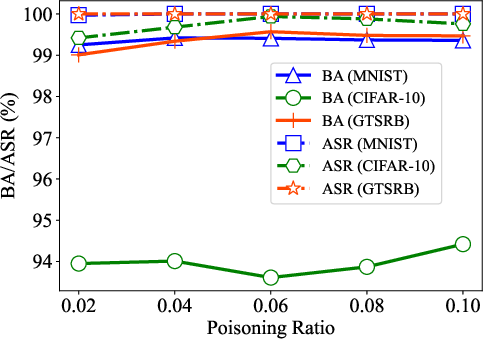
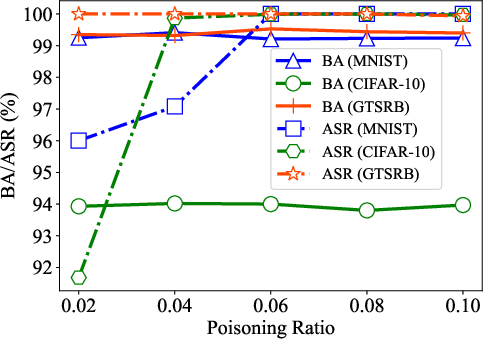
Figure 7: Effects of the poisoning ratio (rho) to our M-to-N backdoor attack on the three datasets. (a) 1-to-1 attack (M=1, N=1); (b) 10-to-1 attack (M=10, N=1).
Conclusion
The M-to-N backdoor attack paradigm significantly advances the scope and stealth of backdoor attacks on DNNs, facilitating multi-target attacks without degrading model accuracy. This approach opens new dimensions in backdoor strategy formulation, positioning itself as a formidable technique in adversarial settings. Future work will explore deeper integration of dynamic, generative triggers within image structures, enhancing adaptability and resistance to novel countermeasures in AI systems.