- The paper presents SV-FEND, a multimodal detection model leveraging cross-modal interactions to enhance fake news detection.
- It introduces FakeSV, a comprehensive dataset of 11,603 short videos enriched with user comments and publisher profiles for in-depth analysis.
- Experiments show that integrating text, audio, visual, and social data significantly improves accuracy, supporting real-time misinformation intervention.
FakeSV: A Multimodal Benchmark with Rich Social Context for Fake News Detection on Short Video Platforms
Introduction
The prevalence of short video platforms like TikTok has revolutionized the way news is shared, making them critical channels for dissemination but also fertile grounds for the proliferation of fake news. Analyzing the spread of misinformation via video media poses distinct challenges because videos integrate multiple modalities — visuals, text, and audio — alongside social interactions. To address these challenges, the paper presents FakeSV, the largest Chinese short video dataset aimed at detecting fake news. This dataset incorporates not only video content but also user comments and publisher profiles, enabling a comprehensive exploration of social context.
In recognizing the potent threat posed by video-form misinformation, the paper proposes a multimodal detection model, SV-FEND, which leverages cross-modal correlations to enhance feature selection and detection capabilities. This study provides a thorough experimental evaluation of this model, outlining the superiority of SV-FEND in detecting fake news across multimodal data types.
Dataset Construction
The construction of the FakeSV dataset was informed by two major considerations: the need for high-quality data representative of different modalities involved in fake news detection, and the necessity of capturing the breadth of social interactions around these videos. The dataset includes approximately 11,603 videos, split equally among fake, real, and debunked categories, sourced from popular Chinese platforms Douyin and Kuaishou.
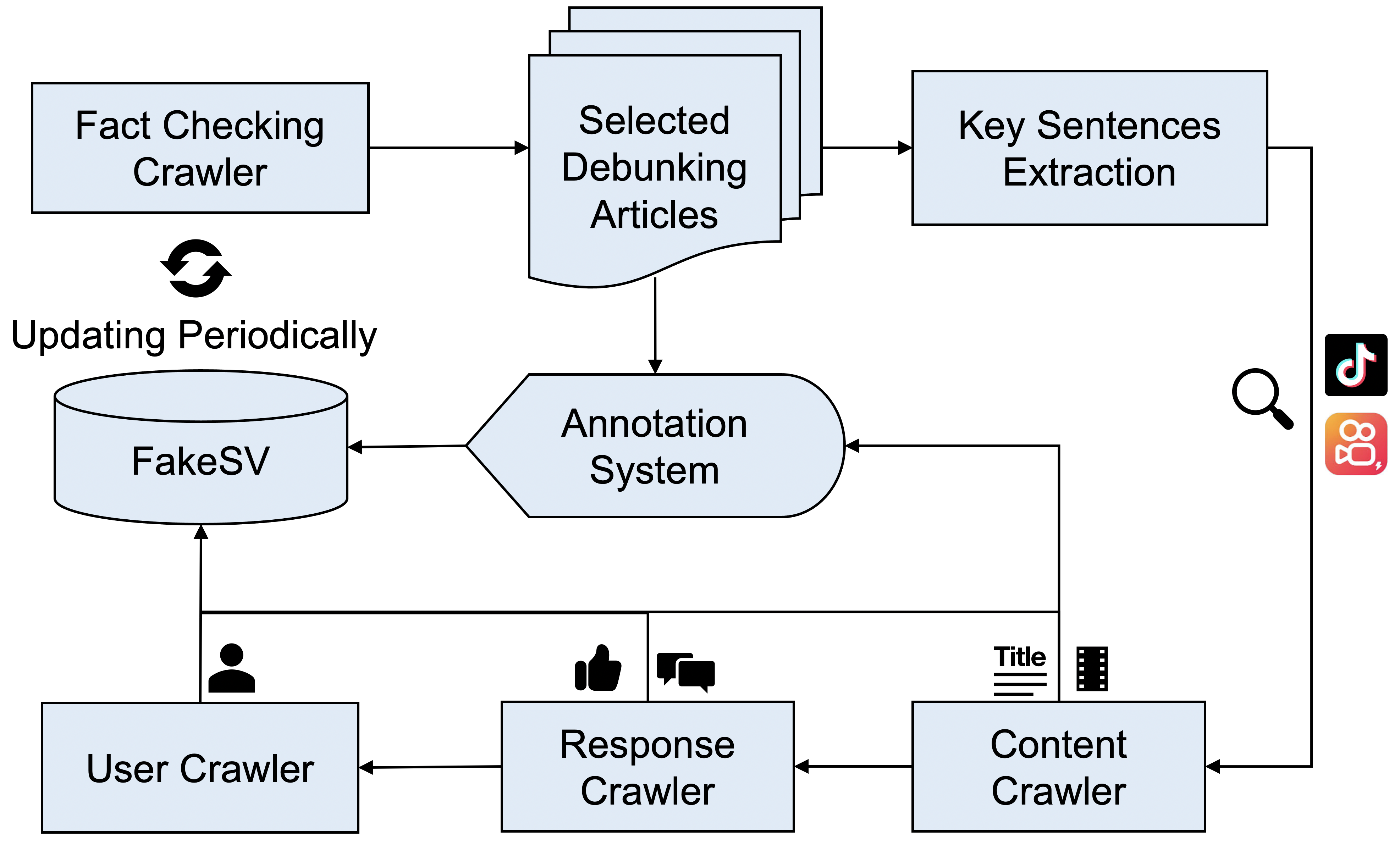
Figure 1: Flowchart of data construction process.
The dataset construction process involved crawling factual debunking articles to identify fake video targets and annotating these targets with precision. Annotations classify videos into categories based on their congruence with verified news sources, enabling the distinction between misleading and factual content.
Data Analysis
The FakeSV dataset facilitates a thorough analysis of fake news characteristics across various dimensions.
News Content
The text in video titles and transcripts often differs markedly between real and fake news, with fake titles being generally shorter and emotionally charged, emphasizing sensational or emotional triggers.
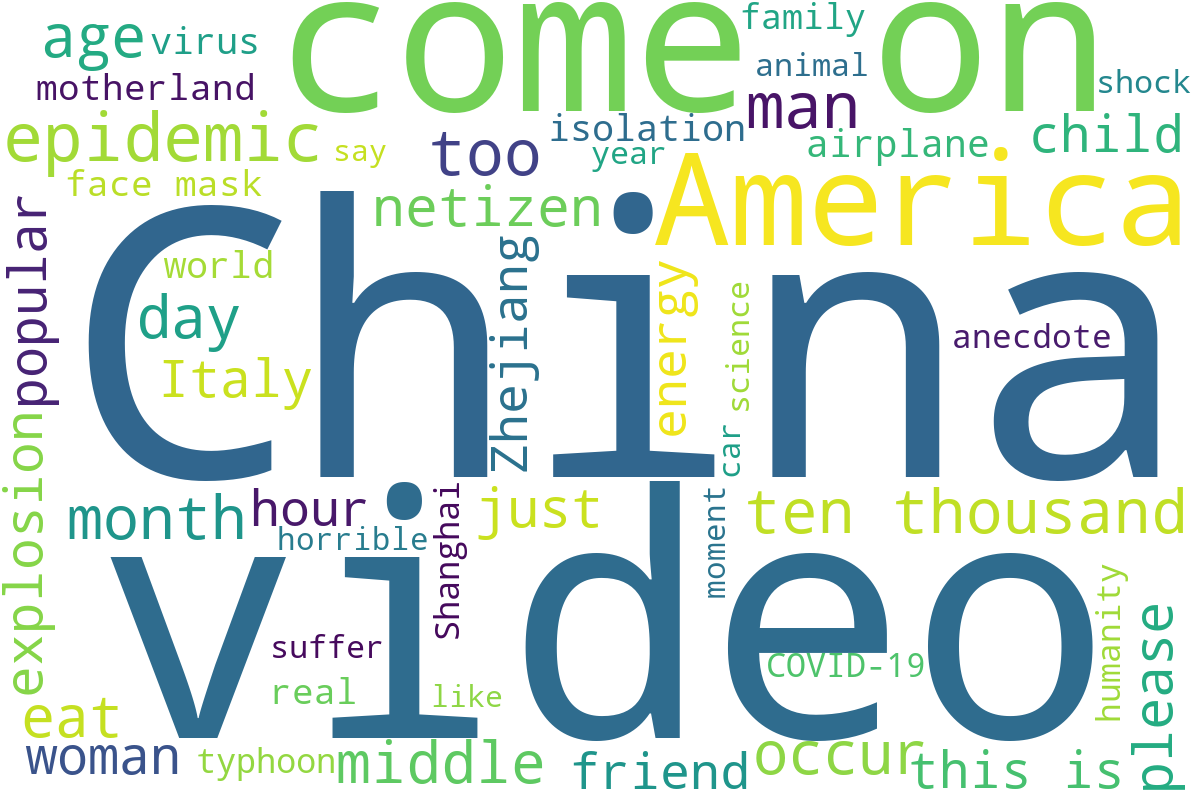
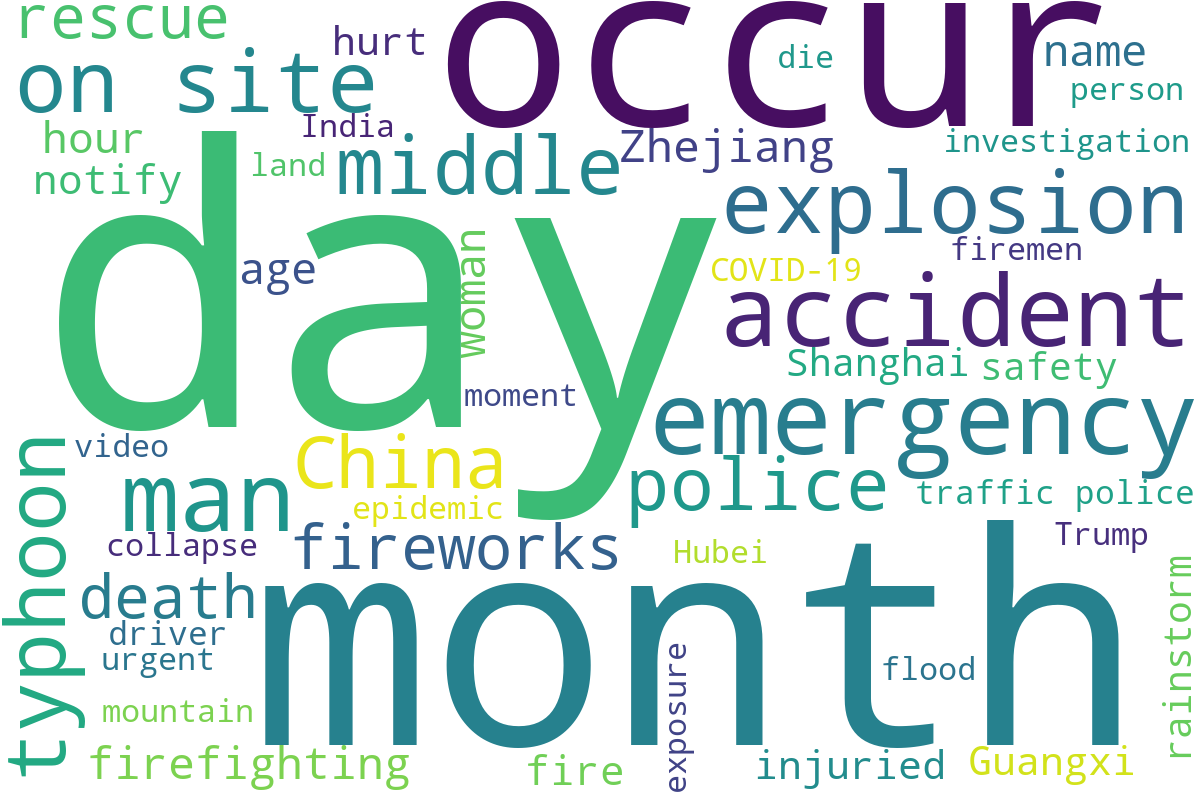
Figure 2: Word cloud of video titles.
Visual analysis reveals that fake news videos often have discernibly lower quality frames, an indicator potentially tied to unauthorized editing and reproduction.
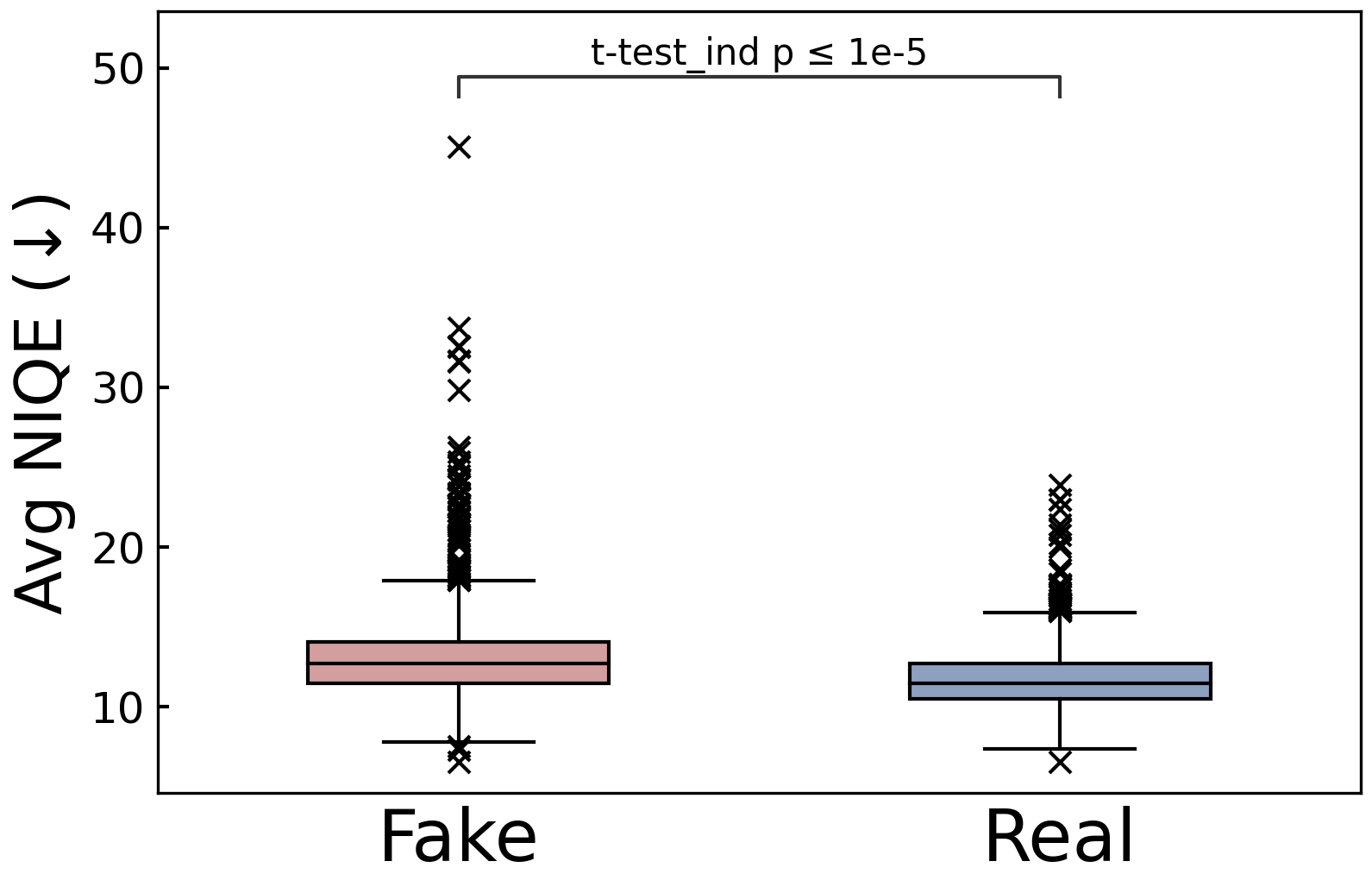
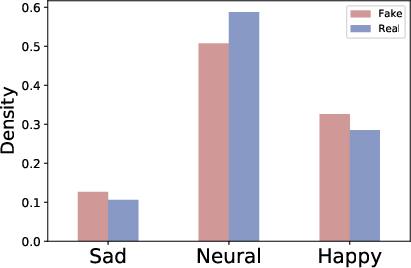
Figure 3: Frame quality. Lower values mean higher quality.
Audio analysis further supports the hypothesis that stronger emotional manipulation characterizes fake news videos. The emotional intensity deduced from audio tracks underscores the manipulative strategies employed in false narratives.
Social Context
A comparison of publisher profiles illustrates that fake news predominantly arises from non-verified accounts. The activity patterns — consuming versus creating content — provide additional clues to source reliability.
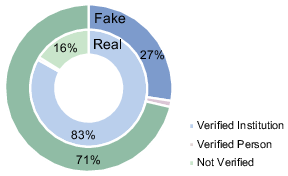
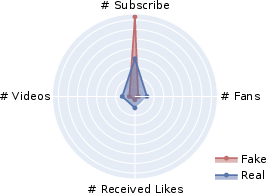
Figure 4: Publisher's profile.
User response analysis demonstrates that fake news videos, despite lower credibility, receive substantial engagement. This engagement, illustrated through metrics like likes and comments, underlines the insidious allure and viral nature of misinformation.
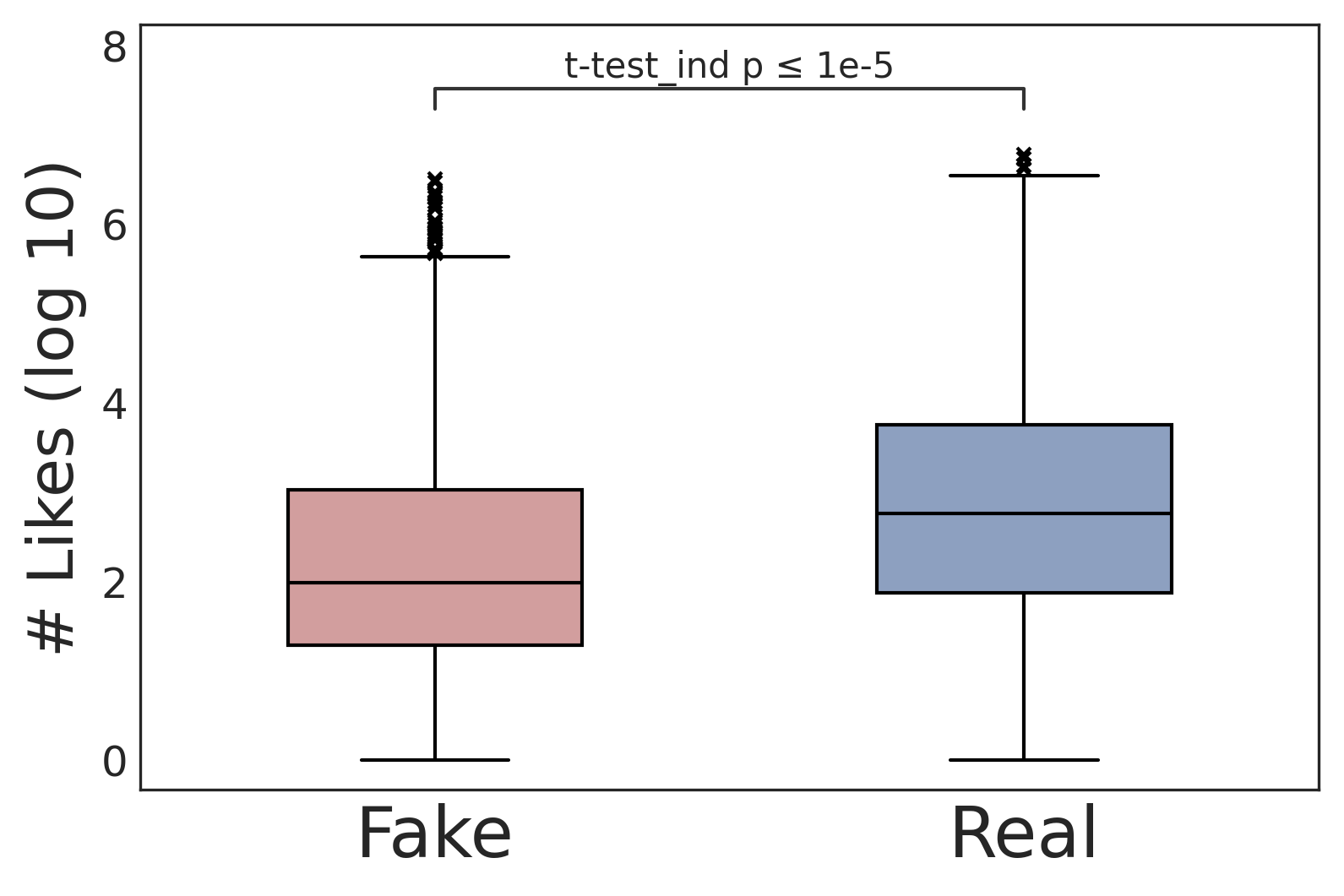
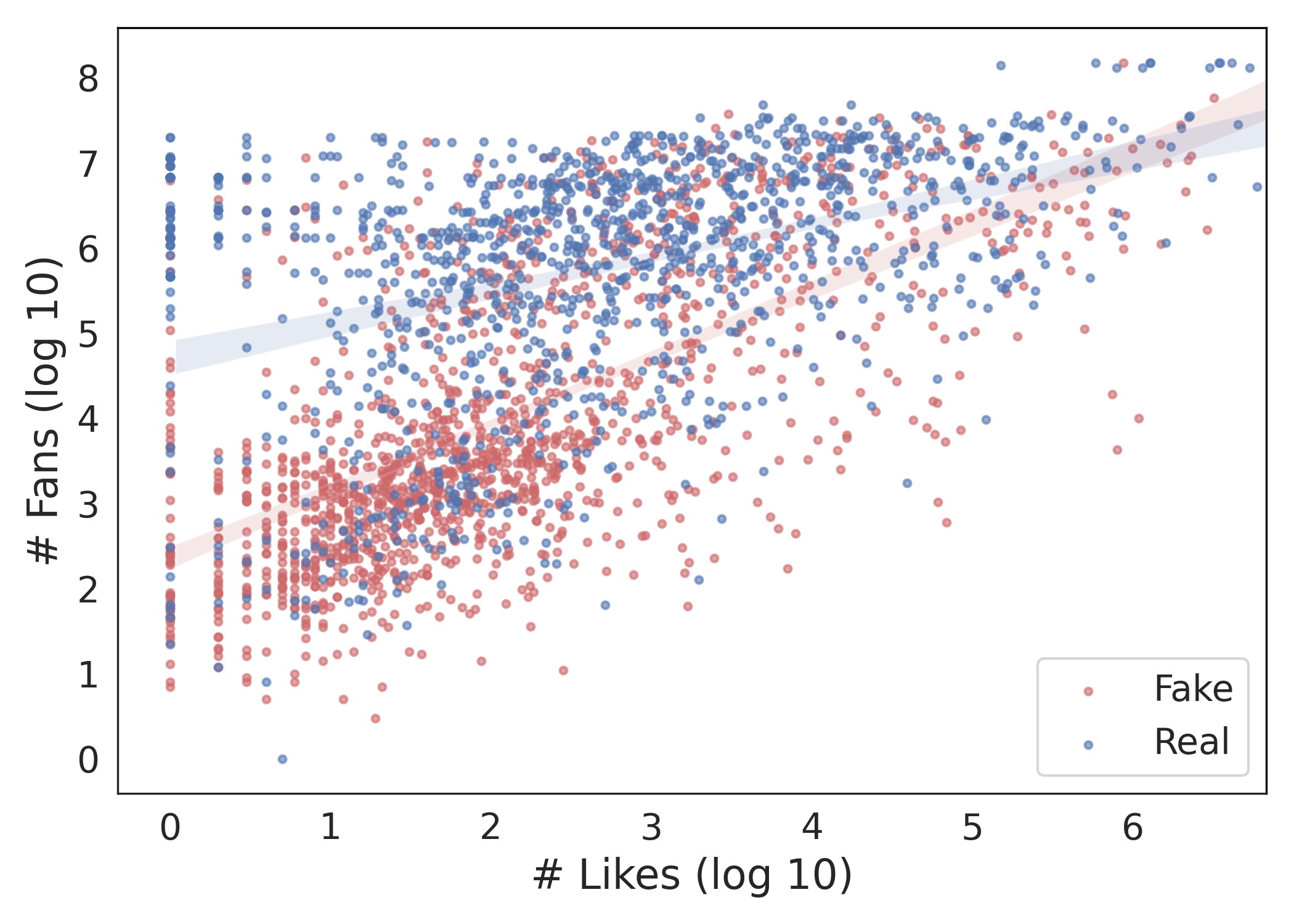
Figure 5: User responses.
Method
The SV-FEND model is designed to address challenges in multimodal fake news detection by dynamically integrating social context with content data, employing sophisticated transformer architectures for cross-modal interactions. Utilizing co-attention mechanisms, SV-FEND enhances feature representation across text, audio, and visual modalities, thereby refining detection precision.
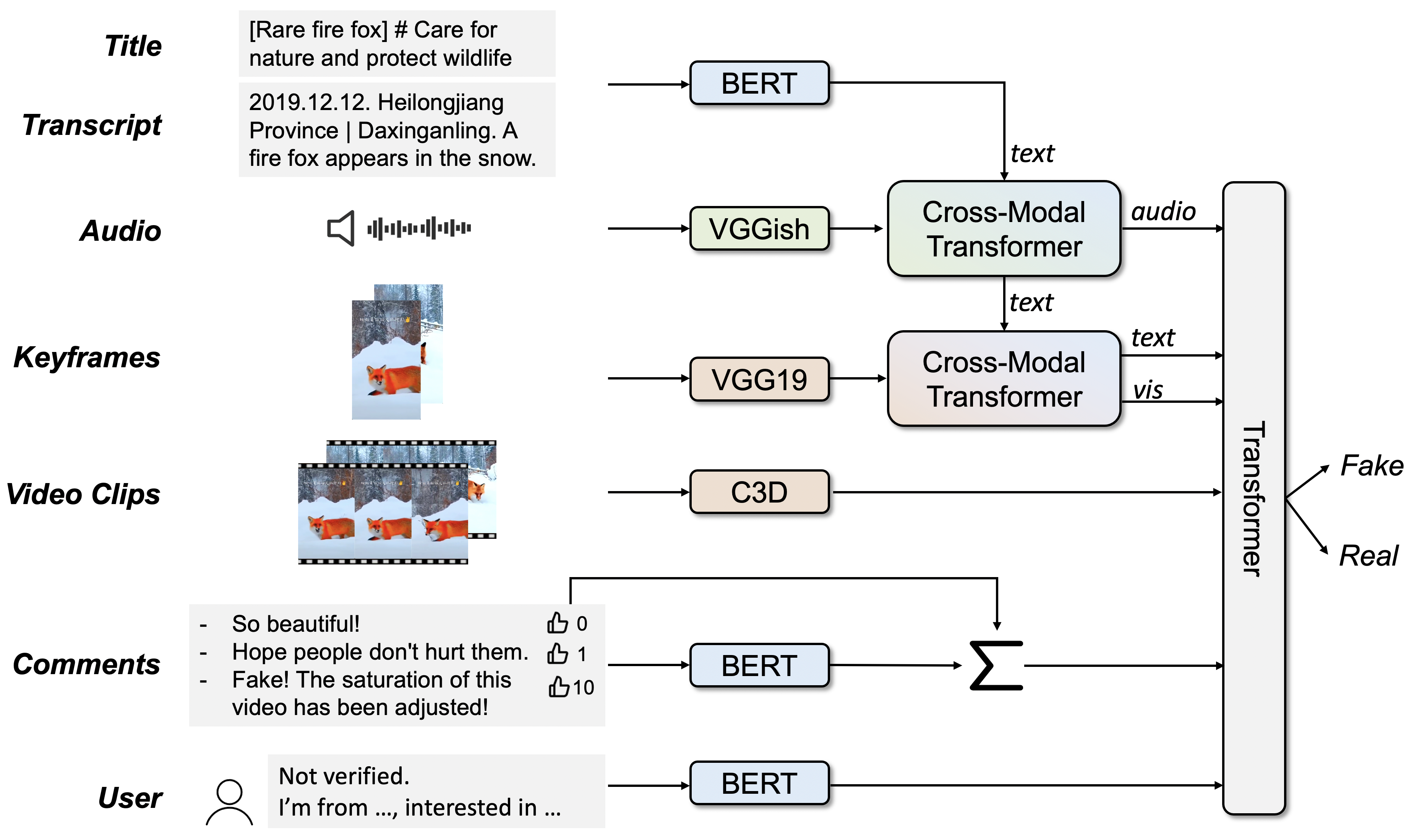
Figure 6: Architecture of the proposed framework SV-FEND.
Experiments
Extensive experiments validate SV-FEND’s efficacy compared to other methods, demonstrating superior accuracy in discerning between fake and real news. Notably, the multimodal approach significantly enhances detection capabilities, underscoring the importance of a holistic analytical model.
Ablation studies reveal that each modality contributes uniquely to detection success, with textual data being particularly potent. Temporal experiments further highlight the model’s robustness in predicting the emergence of misinformation, a critical capability for real-time intervention strategies.


Figure 7: Two representative fake news videos in FakeSV that were detected and missed by SV-FEND respectively.
Conclusion and Future Directions
This paper introduces FakeSV, a pivotal resource for advancing fake news detection research on short video platforms, alongside SV-FEND, an innovative detection model leveraging multimodal data integration. Future work should focus on expanding the model beyond detection, exploring automated fact-checking integration and cross-platform misinformation analysis. The dataset's rich multimodal context provides a fertile foundation for these explorations, thereby contributing to more robust and adaptive misinformation counter-strategies in digital media landscapes.