- The paper introduces CoTMix, a novel framework that leverages temporal mixup with contrastive learning to mitigate domain shifts in time-series data.
- The methodology blends source-dominant and target-dominant samples while preserving key temporal features, outperforming state-of-the-art UDA methods on five datasets.
- Experimental results reveal significant macro-F1 score improvements, indicating CoTMix’s potential for applications in healthcare, IoT, and wearable technologies.
Contrastive Domain Adaptation for Time-Series via Temporal Mixup
Introduction
The research paper "Contrastive Domain Adaptation for Time-Series via Temporal Mixup" (2212.01555) introduces a novel framework, CoTMix, designed to address the challenge of unsupervised domain adaptation (UDA) in time-series data. The paper underscores the lack of exploration in applying UDA methodologies to time-series applications, as opposed to their visual counterparts. CoTMix employs contrastive learning combined with a temporal mixup strategy to tackle domain shift between a labeled source domain and an unlabeled target domain, eliminating the reliance on traditional statistical distances or adversarial techniques.
Methodology
The core innovation of the CoTMix framework lies in its cross-domain temporal mixup strategy. This approach facilitates the generation of source-dominant and target-dominant domains by blending samples from both domains while preserving the temporal characteristics of the less-dominant domain.
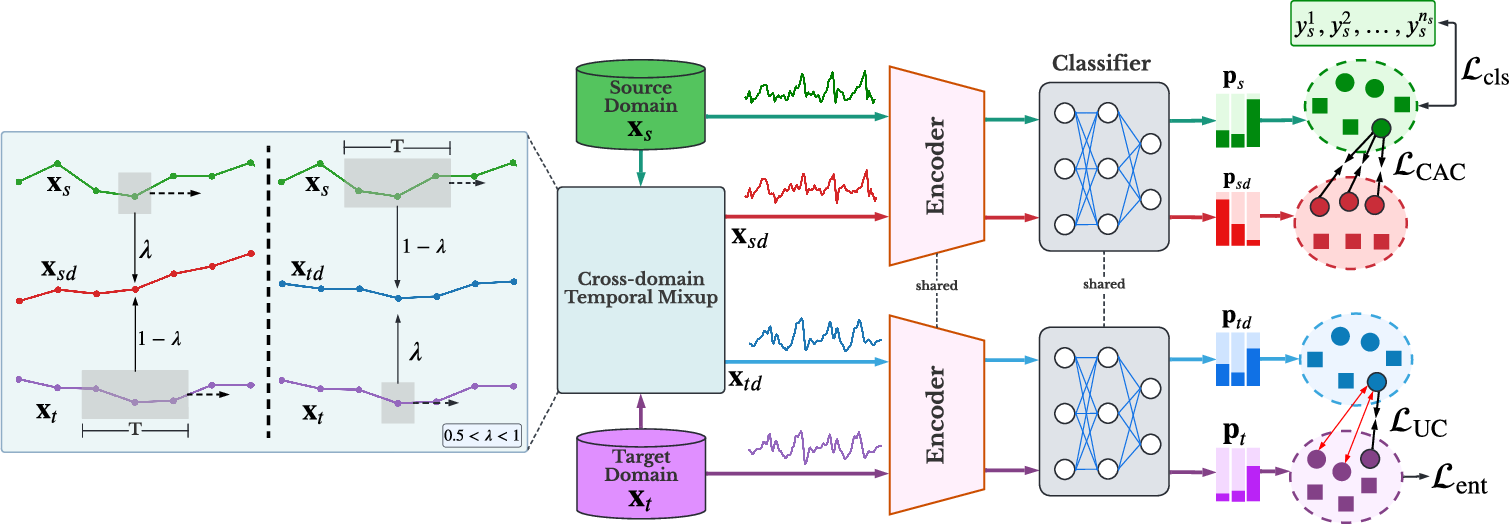
Figure 1: The overall structure of our CoTMix framework. The cross-domain temporal mixup strategy generates the source-dominant x.
A crucial component of CoTMix is the in-domain contrastive learning that maximizes the similarity between each domain and its corresponding augmented view. This method progressively encourages both domains to converge towards a shared intermediate space, effectively mitigating the distribution shift between them.
Experimental Results
The study evaluates CoTMix across five real-world time-series datasets: SSC, UCIHAR, HHAR, WISDM, and Boiler. The experiments demonstrate that CoTMix substantially outperforms state-of-the-art UDA methods tailored for time-series, with remarkable improvements in macro-F1 scores across various scenarios.
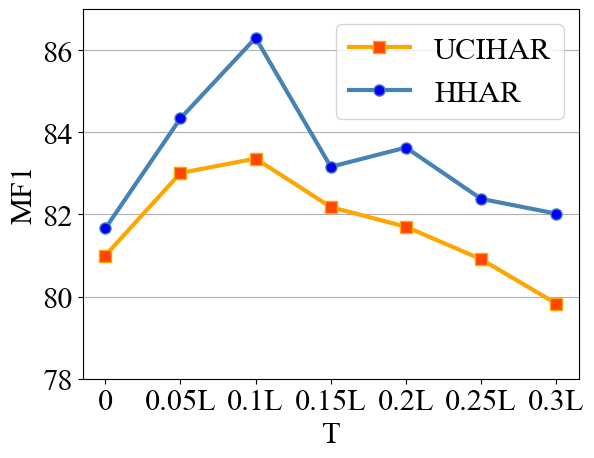
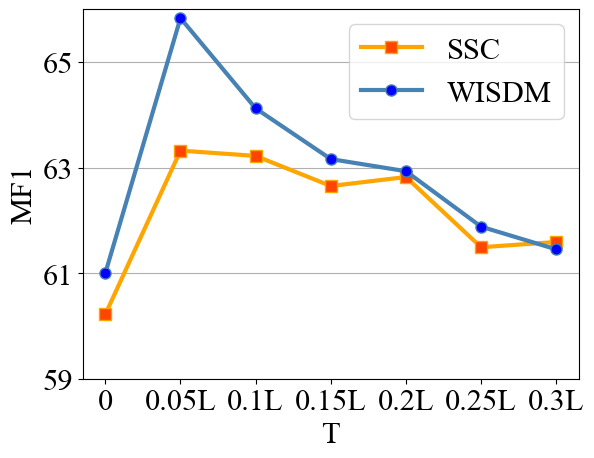
Figure 2: UCIHAR and HHHAR datasets performance comparison between CoTMix and other methods.
These results affirm the efficacy of temporal mixup and contrastive adaptation in handling time-series UDA challenges, achieving significant gains particularly in scenarios characterized by large domain shifts.
Impact and Implications
The findings of this research advocate for the broader application of contrastive learning paradigms in time-series data, a domain historically more reliant on adversarial and statistical alignment techniques. CoTMix's simplicity and superior performance suggest a new direction for developing lightweight, effective UDA frameworks that cater to the unique temporal dynamics of time-series data.
The implications extend beyond academic inquiry, with potential applications in various fields including healthcare, wearable technology, and industrial IoT, where time-series data is prevalent. As this framework is further explored, it may inspire adaptations and enhancements that could bridge more complex domain disparities.
Conclusion
The paper contributes a novel perspective on domain adaptation for time-series data through the CoTMix framework. By employing temporal mixup and contrastive learning, the framework overcomes significant domain shifts, offering a promising alternative to existing UDA methodologies. Future research could logically focus on extending this approach to other forms of sequential data, enhancing scalability, and exploring integration with additional unsupervised learning strategies. This work paves the way for more robust and efficient domain adaptation solutions in time-series analysis.