- The paper presents a novel explainable framework that integrates example-based and prototype-based methods for internet meme classification.
- It combines state-of-the-art textual (BERT, BERTweet) and visual (CLIP) models to capture nuanced semantic features for improved classification accuracy.
- Experimental results on MAMI and Hateful Memes datasets demonstrate that integrating multimodal cues enhances both performance and explainability.
Multimodal and Explainable Internet Meme Classification
Introduction
The problem of internet meme classification, particularly in detecting harmful content such as hate speech and misogyny, has gained attention due to the weaponization of online platforms in political and social contexts. Traditional black-box methods for meme classification often overlook the semantic and contextual nuances inherent to memes. This paper introduces a modular and explainable architecture that leverages example- and prototype-based reasoning to better understand internet memes.
Methodology
The approach utilizes both textual and visual state-of-the-art (SOTA) models in a multimodal setup to ensure a comprehensive representation of memes. The architecture includes:
- Example-based Meme Classification: This method uses similarity-based retrieval, powered by a pre-trained model, to explain classification results by presenting similar memes from the dataset.
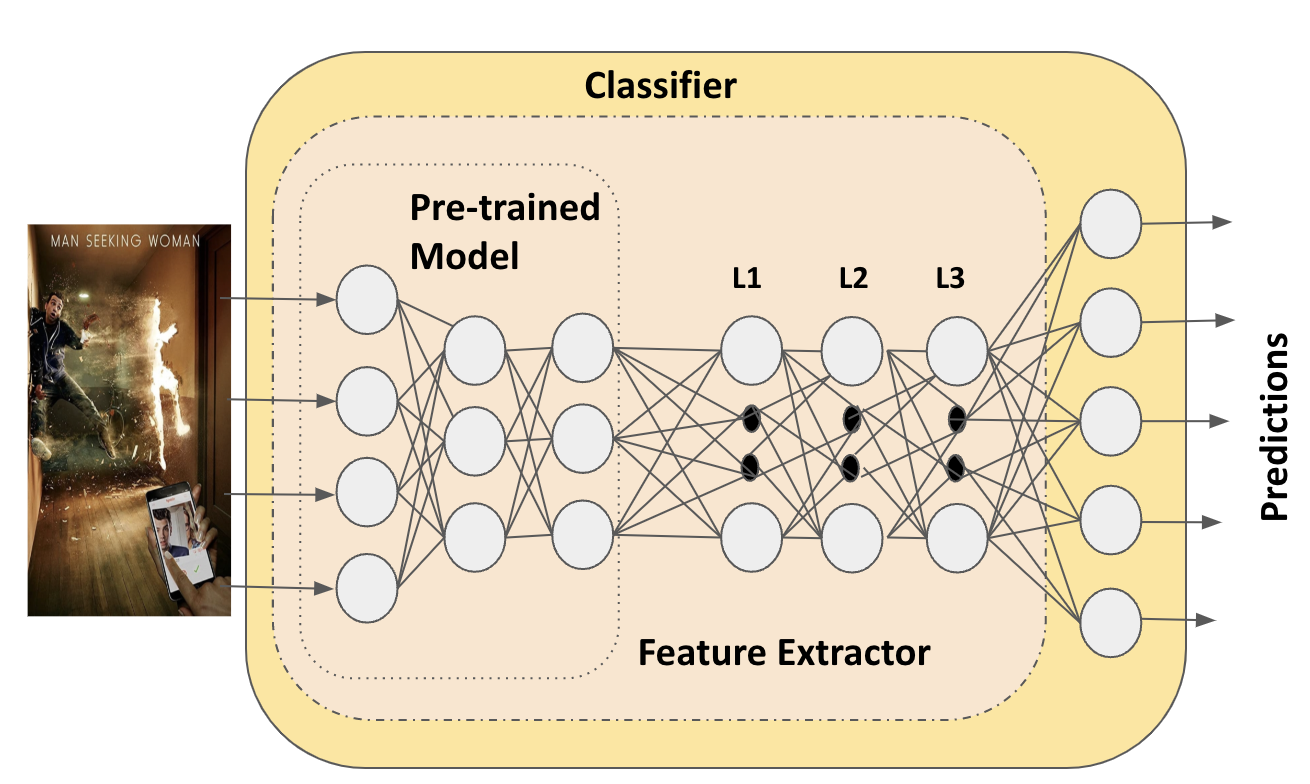
Figure 1: Classification and feature extraction model within the Example-based explanation model.
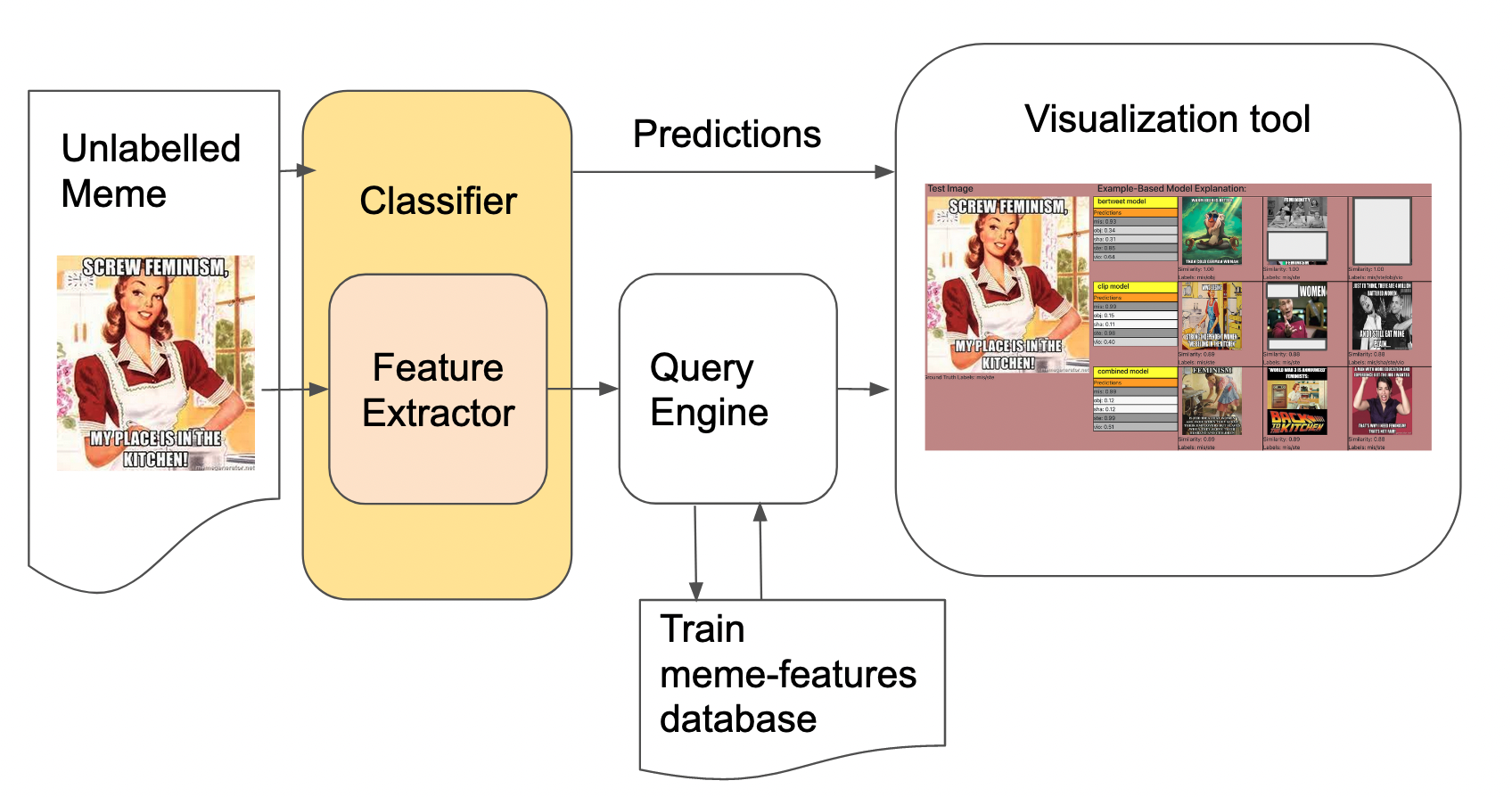
Figure 2: Example-based explanation based on similarity-based meme search. The Train meme-features database contains pre-computed features using the Feature Extractor module.
- Prototype-based Meme Classification (xDNN): This inherently interpretable method generates class-wise prototypes and uses rule-based decision-making to classify new memes.
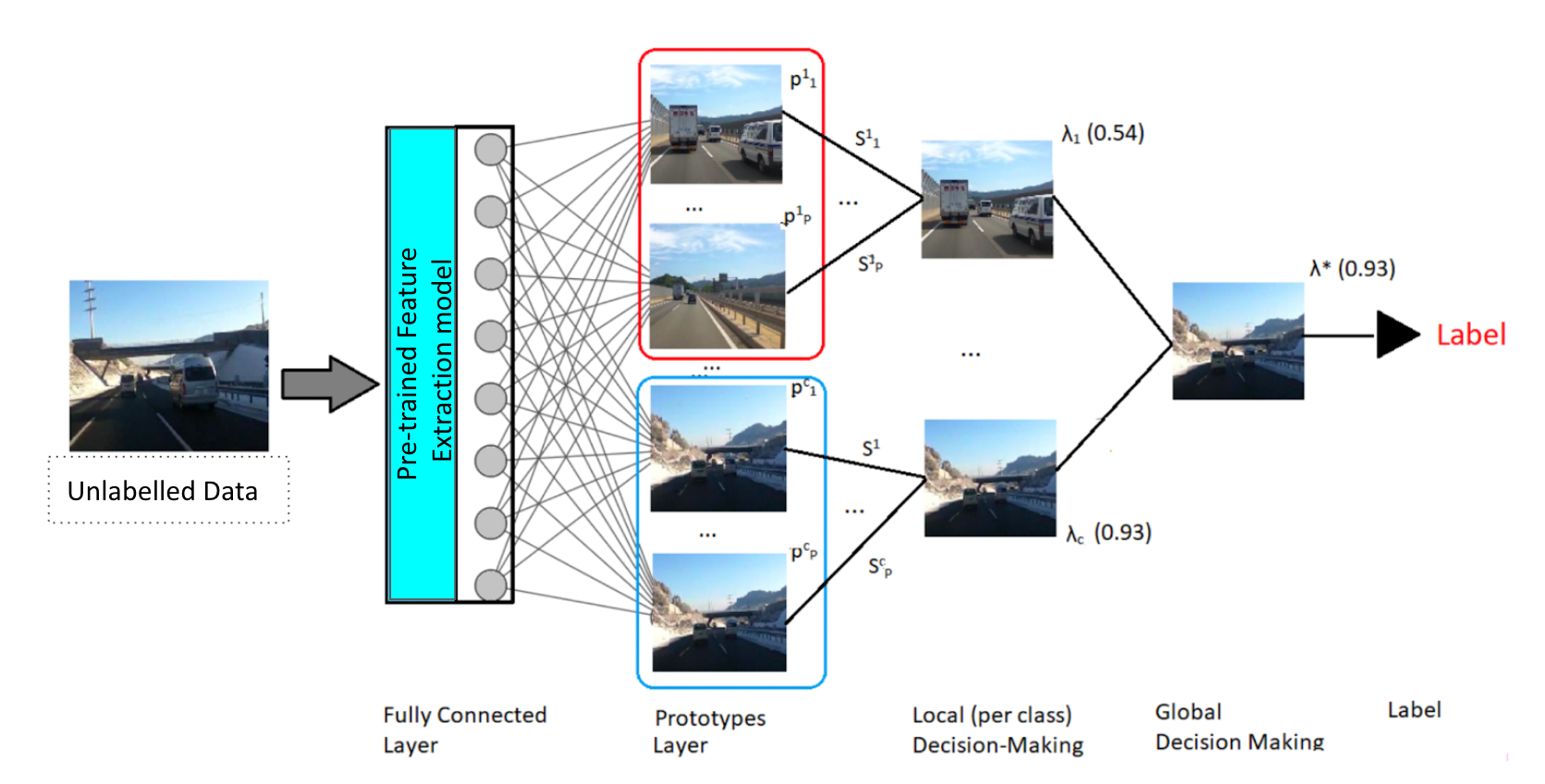
Figure 3: Our architecture for prototype-based explainable classification called Explainable Deep Neural Networks (xDNN). Figure reused from (Angelov et al., 2019).
- Feature Extraction Models: This involves the use of BERT and BERTweet for textual information, and CLIP for visual information extraction. The integration of these modalities allows for capturing the complex interplay between text and image in memes.
Experimental Evaluation
The classification performance was evaluated on two datasets: the MAMI (Misogyny Identification) and the Hateful Memes datasets. The methodology was assessed in terms of both accuracy and explainability.
Discussion
The paper highlights several challenges in meme classification:
- Contextual Dependency: Memes often rely on cultural or real-world contexts that are not captured by current models, leading to potential misclassification.
- Integration with Background Knowledge: For more robust classifications, future models need to incorporate background knowledge and address the nuanced use of language and imagery.
- Subjectivity in Labeling: The subjective nature of tasks like misogyny detection requires critical examination of the ground truth labels, as biases in annotation can affect model training.
Prior work has mainly focused on basic meme tracking and hate speech detection using SOTA visual and textual models. This paper distinguishes itself by providing a comprehensive, explainable framework that balances performance with transparency. Despite advances, this remains an underexplored area in AI, with significant potential for future research focused on integrating deep contextual understanding with machine learning models.
Conclusion
This research advances the field of meme classification by presenting methods that highlight the importance of combining different data representations and explainability techniques. Future work should address the limitations identified, such as context integration and subjective labeling, to improve classification robustness and transparency. The code and methods presented aim to inspire further development in the explainable classification of internet memes.
