- The paper introduces ROIFormer, which integrates semantic cues with local adaptive attention to enhance self-supervised monocular depth estimation.
- The method restricts attention to learnable local regions, reducing computational overhead and accelerating convergence for precise depth predictions.
- Evaluated on the KITTI dataset, ROIFormer achieves state-of-the-art metrics with reduced complexity and real-time performance compared to global attention methods.
Introduction
The paper introduces ROIFormer, a semantic-aware region of interest transformer designed to enhance self-supervised monocular depth estimation. The approach leverages semantic segmentation cues to guide local adaptive attention, enabling efficient and discriminative feature fusion between depth and semantic domains. Unlike global or unconstrained deformable attention mechanisms, ROIFormer restricts attention to learnable local regions, improving both computational efficiency and convergence speed. The method is evaluated on the KITTI dataset, demonstrating state-of-the-art performance in self-supervised monocular depth estimation.
Methodology
Self-Supervised Depth Estimation Framework
The proposed framework utilizes consecutive monocular frames to jointly learn depth and pose via photometric and smoothness losses. Semantic segmentation is incorporated as an auxiliary task, with both branches sharing a common encoder backbone. The depth and semantic features are fused using the ROIFormer module, which operates at multiple scales and semantic levels.
ROIFormer introduces a region-of-interest (ROI) guided deformable attention mechanism. For each query point in the depth feature map, a local ROI is inferred from the semantic feature map using lightweight linear functions. Attention is then performed only within this ROI, focusing on the most relevant semantic features and excluding irrelevant points. This local constraint reduces the search space, leading to more selective feature learning and faster convergence.
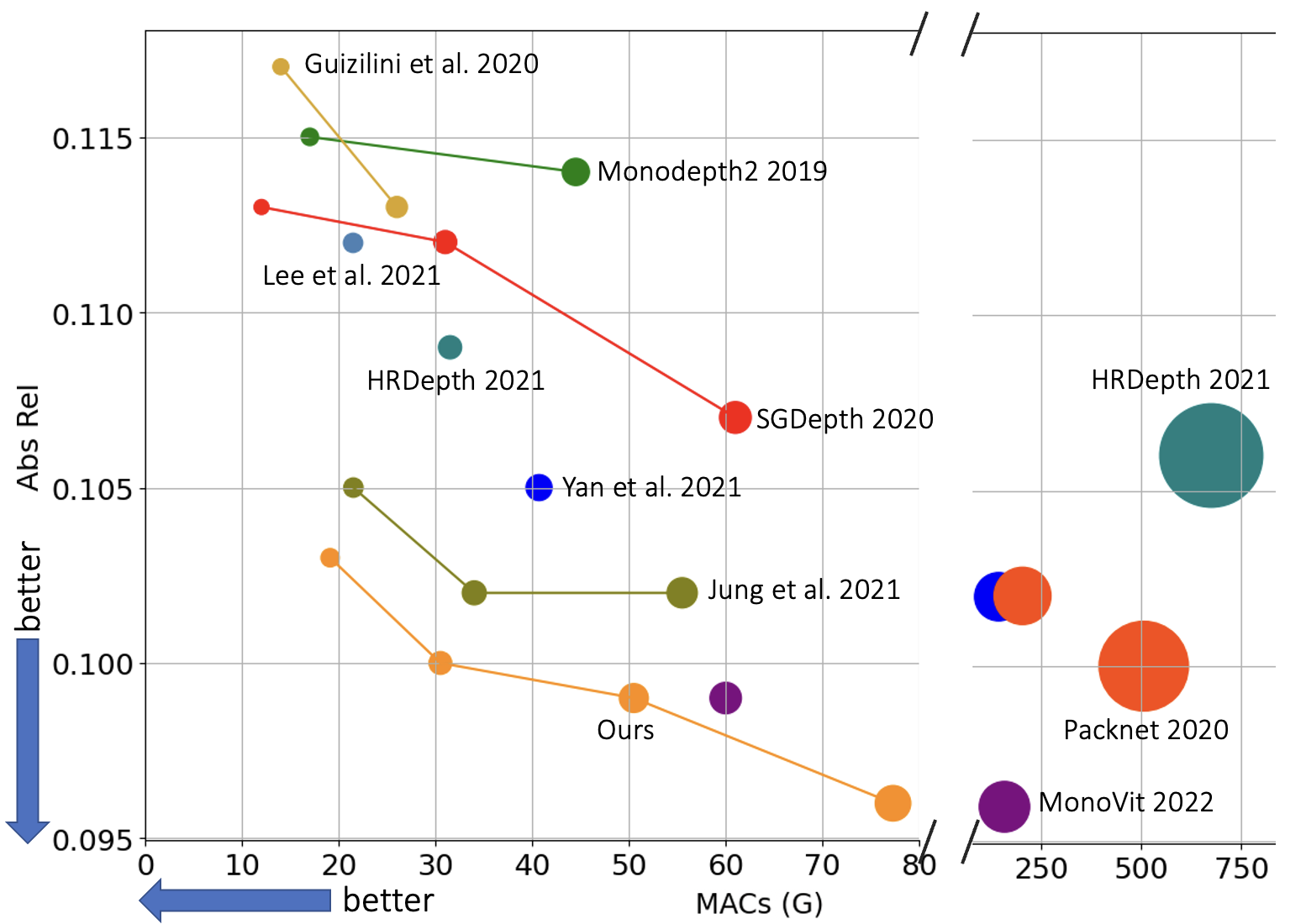
Figure 1: Speed-Accuracy trade-off curve, illustrating the efficiency of ROIFormer compared to other attention mechanisms.
The attention module is extended to a multi-head and hierarchical structure, enabling information distillation across different semantic levels. The fusion process is formalized as:
Fusion⟨fi,bi⟩=j∈Ω(bi)∑Ai,jWi,jfpi+Δpi
where bi denotes the ROI for query fi, and Ω(bi) is the set of sampled key-value pairs within the ROI.
Semantic Guided Re-projection Mask
To address boundary contamination and uncertainty in depth estimation near object borders, a semantic-guided re-projection mask is introduced. This mask penalizes photometric loss for pixels near instance boundaries, improving robustness in challenging regions such as reflective surfaces and occlusions.
Experimental Results
Ablation Studies
Extensive ablation studies demonstrate the impact of the number of attention layers, pyramid levels, and attention point sampling strategies. Two stacked attention layers yield the best trade-off between accuracy and complexity. Feature fusion at shallow pyramid levels (higher spatial resolution) is critical for fine-grained depth estimation.
Comparisons between global transformer attention, deformable attention, and ROIFormer reveal that ROIFormer achieves superior accuracy and efficiency, particularly at high input resolutions. Transformer attention exceeds memory limits for high-resolution inputs, while deformable attention suffers from performance degradation due to an excessively large search space.
Quantitative and Qualitative Evaluation
On the KITTI Eigen test set, ROIFormer outperforms previous state-of-the-art methods across all metrics, including AbsRel, SqRel, RMSE, and δ<1.25. The model achieves competitive performance with significantly reduced computational complexity (MACs and parameters), running at real-time speeds on both ResNet-18 and ResNet-50 backbones.
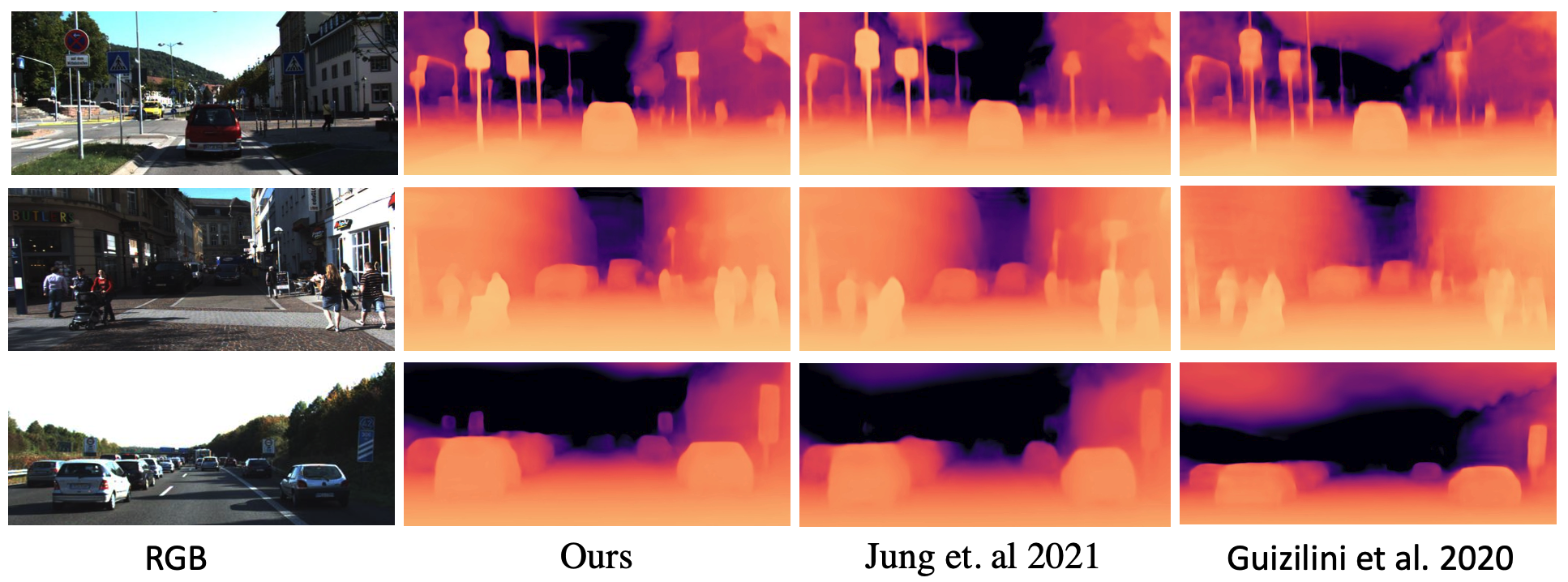
Figure 2: Qualitative self-supervised monocular depth estimation performance comparing ROIFormer with previous State-of-the-Art.
Qualitative results show that ROIFormer produces more accurate and consistent depth maps, particularly at object boundaries and in low-texture regions, where previous methods struggle.
Discussion
ROIFormer demonstrates that constraining attention to semantic-aware local regions is highly effective for self-supervised monocular depth estimation. The approach addresses key challenges such as boundary uncertainty, moving objects, and ambiguity in low-texture areas. The multi-head, multi-scale design enables robust feature enhancement without incurring the computational overhead of global attention mechanisms.
The semantic-guided re-projection mask further improves robustness in challenging regions, suggesting that integrating geometric and semantic cues is essential for high-quality depth estimation in real-world scenarios.
Implications and Future Directions
Practically, ROIFormer enables efficient and accurate depth estimation suitable for deployment in resource-constrained environments, such as robotics and autonomous vehicles. The method's modular design allows for integration with various backbone architectures and semantic segmentation models.
Theoretically, the work highlights the importance of local adaptive attention and cross-domain feature fusion in dense prediction tasks. Future research may explore extending ROIFormer to other modalities (e.g., optical flow, surface normals) or incorporating additional geometric priors. Further investigation into dynamic ROI generation and instance-level semantic guidance could yield even more discriminative representations.
Conclusion
ROIFormer presents a semantic-aware, region-constrained attention mechanism for self-supervised monocular depth estimation, achieving state-of-the-art results on the KITTI dataset. By leveraging local semantic cues and efficient attention, the method addresses longstanding challenges in depth estimation, offering a scalable and robust solution for real-world applications.