- The paper introduces a LC-aware Repair Network and V2V Attention Module to recover and enhance features lost due to lossy V2V communication.
- The methodology utilizes an encoder-decoder framework with attention mechanisms to effectively mitigate communication-induced feature degradation.
- Experimental results on the OPV2V dataset with the CARLA simulator demonstrate significant improvements in 3D object detection performance over state-of-the-art methods.
Learning for Vehicle-to-Vehicle Cooperative Perception under Lossy Communication
Introduction
The paper "Learning for Vehicle-to-Vehicle Cooperative Perception under Lossy Communication" (2212.08273) addresses the impact of lossy communication on cooperative perception systems in the field of autonomous driving. These systems leverage Vehicle-to-Vehicle (V2V) communication to enhance perception capabilities by sharing deep learning-based features across vehicles. The authors contend that existing cooperative perception algorithms assume ideal communication scenarios, disregarding the prevalent issue of lossy communication that can significantly degrade perception performance.
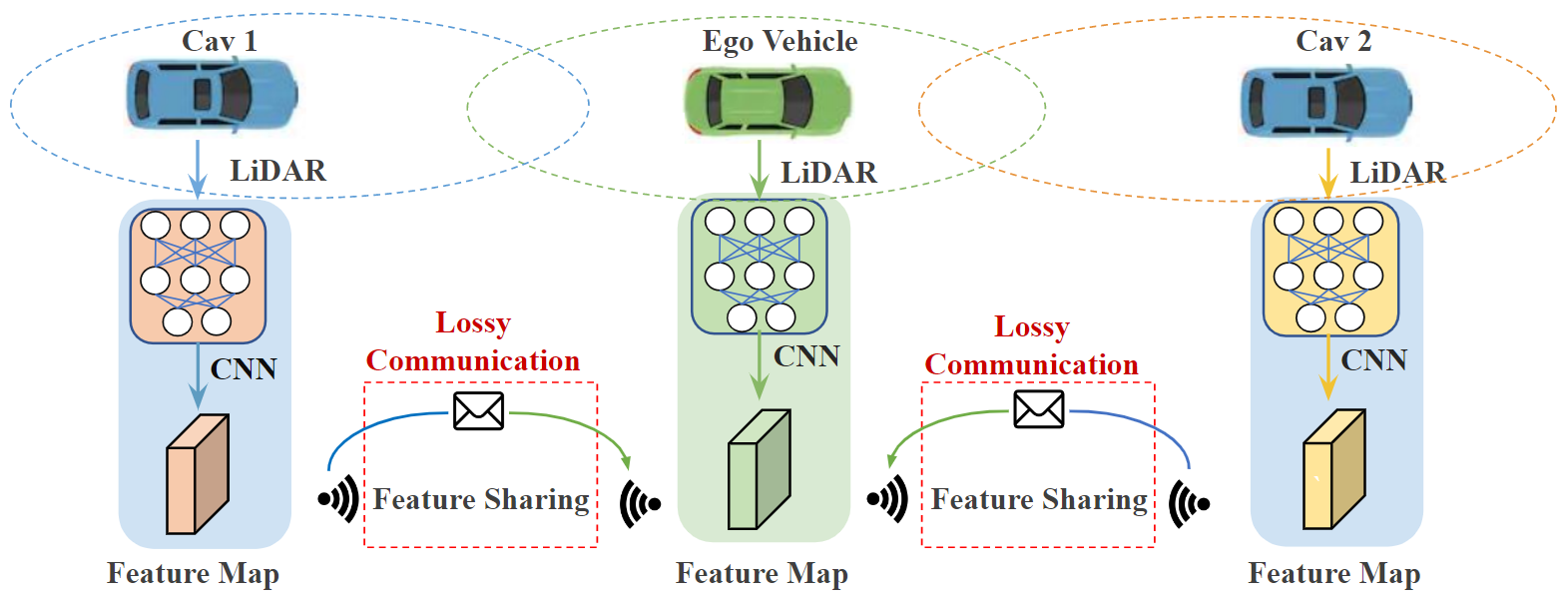
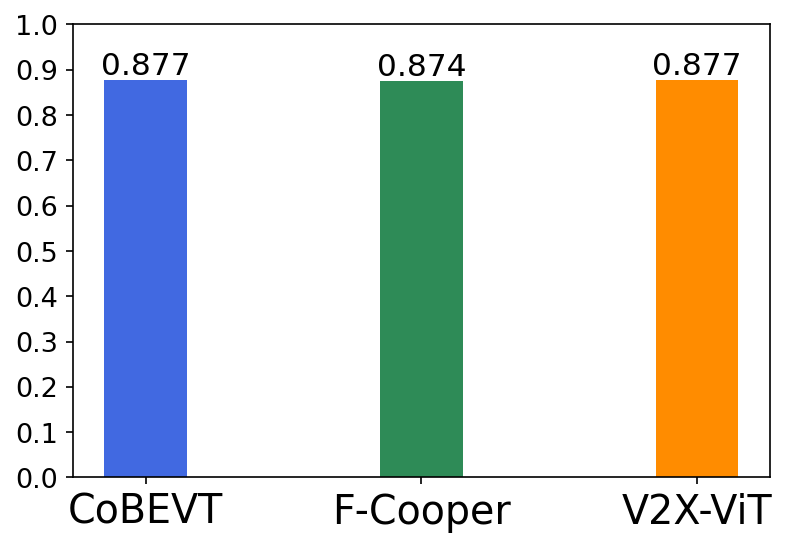
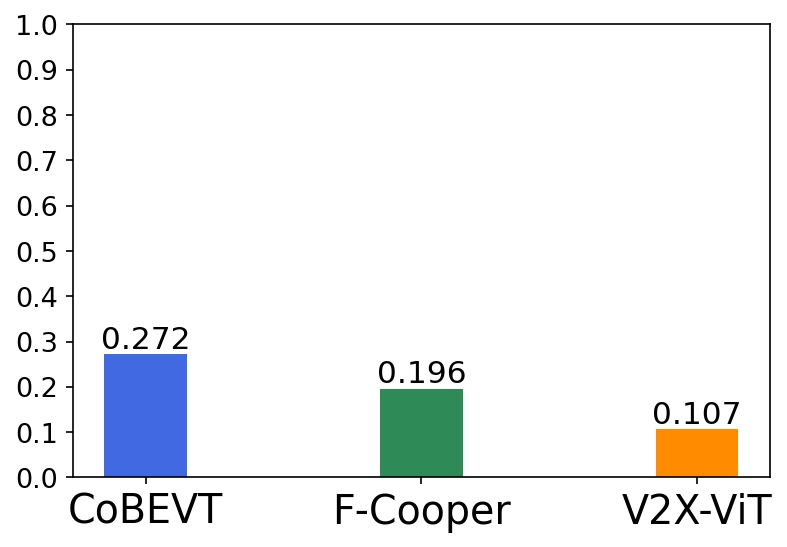
Figure 1: Illustration of the V2V cooperative perception pipeline and its detection performance drop suffering from lossy communication on the public digital-twin CARLA simulator.
Methodology
The proposed methodology introduces a novel intermediate feature fusion framework designed to counteract the detrimental effects of lossy communication. This is accomplished through the development of two key components: the LC-aware Repair Network (LCRN) and the V2V Attention Module (V2VAM). The LCRN operates on an encoder-decoder architecture and aims to recover incomplete features caused by lossy communication by utilizing tensor-wise filtering. Meanwhile, the V2VAM enhances interactions between the ego vehicle's features and those from its surrounding vehicles, employing attention mechanisms to accommodate the uncertainties introduced by lossy transmission.
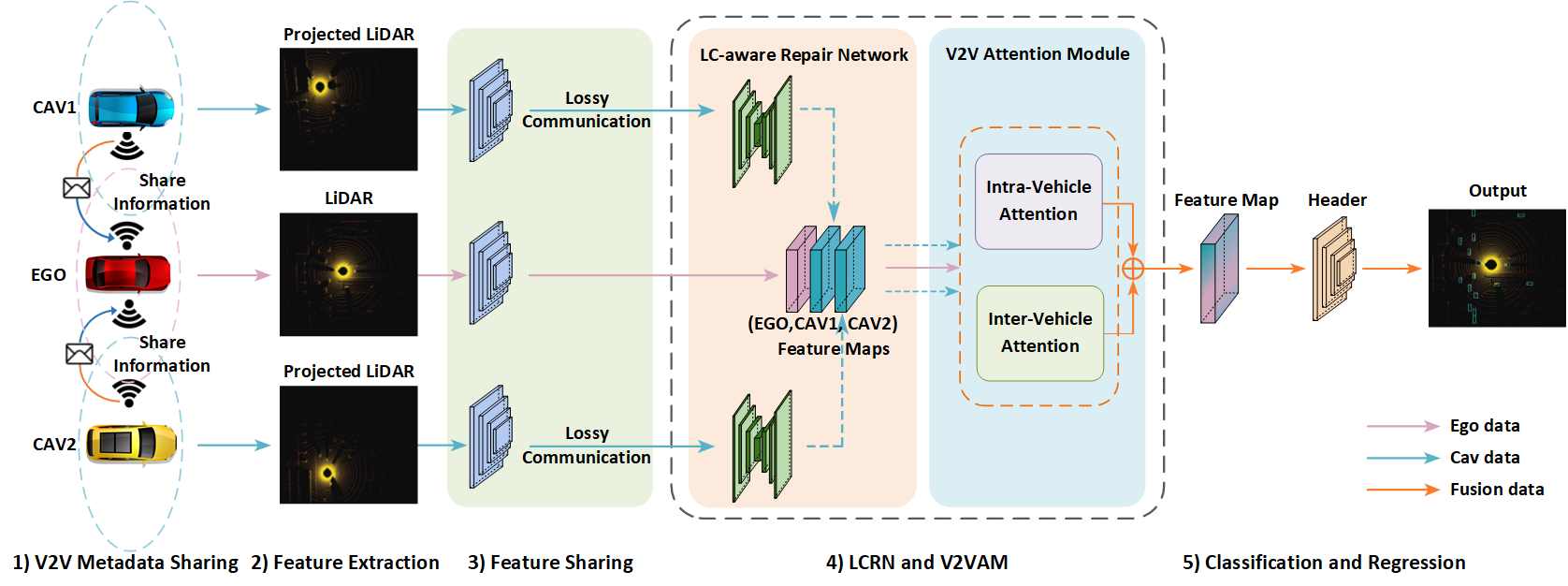
Figure 2: The architecture of LC-aware feature fusion framework. The proposed model includes five components: Metadata Sharing, Feature Extraction, Feature Sharing, LC-aware Repair Network, and V2V Attention Module.
Experimental Results
Experiments were conducted using the OPV2V dataset, which is based on the CARLA simulator. The proposed architecture demonstrated substantial improvements in 3D object detection tasks under lossy communication scenarios, outperforming prominent intermediate fusion methods. In particular, the approach achieved significant enhancements in Average Precision (AP) over state-of-the-art cooperative perception algorithms, showcasing its capability to effectively alleviate communication-induced feature degradation.
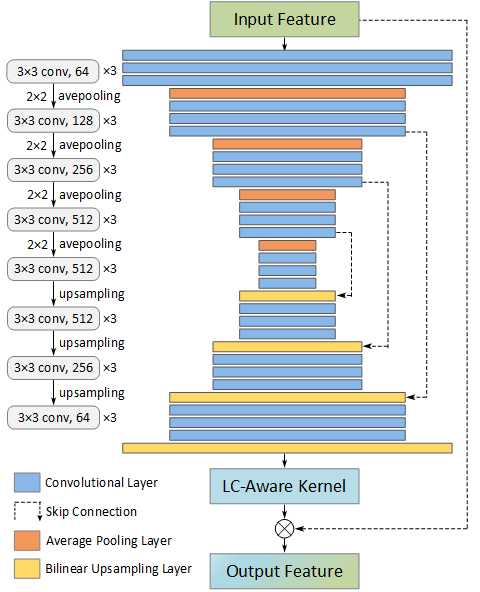
Figure 3: The LC-aware Repair architecture for feature recovery is based on the encoder-decoder structure, which outputs per-tensor feature kernels.
Implications and Future Directions
This research provides both theoretical and practical advancements in the domain of intelligent vehicle perception systems. The methodologies proposed not only improve robustness in communication-challenged environments but also lay the groundwork for further exploration into adaptive perception systems that can dynamically respond to fluctuating communication conditions. Future developments could focus on integrating these features into real-world CAV systems, refining the recovery mechanisms, and exploring additional attention-based fusion strategies to optimize communication resilience further.
Conclusion
The paper presents essential findings that advance the understanding and capabilities of V2V cooperative perception systems under non-ideal communication settings. By incorporating mechanisms such as the LC-aware Repair Network and V2V Attention Module, this research significantly enhances the reliability and effectiveness of autonomous driving systems operating in complex real-world scenarios.