- The paper introduces CoT knowledge distillation to transfer reasoning capabilities from large to small language models.
- It employs a two-step process: generating high-quality CoT annotations with teacher models and fine-tuning student models using teacher forcing.
- Significant improvements are reported, with arithmetic accuracy (e.g., GSM8K rising from 8.11% to 21.99%) and gains in symbolic and commonsense reasoning.
Teaching Small LLMs to Reason
Introduction
The paper discusses the transfer of reasoning capabilities typically observed in LLMs to smaller models through the process of knowledge distillation. The authors focus on Chain of Thought (CoT) prompting, which enhances the reasoning abilities of LLMs by decomposing complex tasks into sequences of intermediate steps. Despite its effectiveness in large models like PaLM 540B and GPT-3 175B, CoT falls short with models possessing less than 10 billion parameters. This paper investigates the potential to bridge this gap by utilizing outputs from larger models to fine-tune smaller models, such as various versions of T5.
Methodology
The authors propose a two-step pipeline for CoT knowledge distillation:
- CoT Data Generation: A larger teacher model generates CoT annotations for existing datasets. The prompts are augmented with the target output to improve the quality of reasoning sequences. This step involves filtering incorrect CoTs, ensuring that only accurate outputs are used for training the smaller student models.
- Fine-tuning Student Models: The smaller models, such as T5, are fine-tuned using teacher forcing on the CoT-annotated datasets. The paper demonstrates that this approach eliminates the need for prompting during inference, as the student model naturally produces CoT after training.
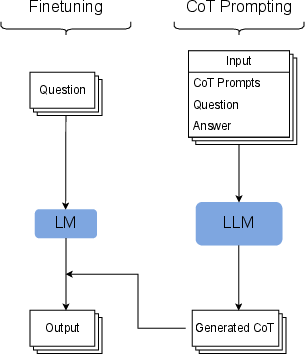
Figure 1: Overview of the proposed method.
This method leverages the reasoning capabilities of LLMs, allowing for improved performance in smaller models across arithmetic, commonsense, and symbolic reasoning tasks.
Experimental Setup
The experiments cover a diverse set of reasoning tasks. For arithmetic reasoning, datasets such as GSM8K, MAWPS, and ASDiv are utilized. Commonsense reasoning is evaluated using the StrategyQA dataset, while symbolic reasoning is tested with synthetic tasks like last letter concatenation and coinflip. Accuracy is measured by the correct computation of CoT outputs, with consideration for arithmetic errors, evaluated through an external calculator.
Results
Arithmetic Reasoning
Fine-tuning with CoT markedly improves performance across all arithmetic datasets. Specifically, GSM8K task accuracy increased from 8.11% to 21.99% using CoT generated by PaLM 540B. The integration of an external calculator further boosted accuracy, underscoring the potential of CoT even when small models struggle with arithmetic accuracy independently.
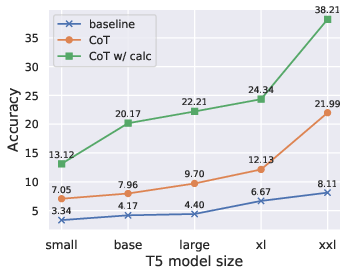
Figure 2: Effect of student model (T5) size on accuracy on GSM8K.
Commonsense Reasoning
On StrategyQA, the proposed method resulted in a modest accuracy increase from 68.12% to 71.98%. This more moderate improvement is attributed to the factual knowledge gap inherent in smaller LMs, which reflects their constrained capacity for memorization and recall.
Symbolic Reasoning
The method showed promising results in symbolic reasoning tasks. While there was limited improvement in the last letter concatenation task, the Coinflip dataset observed significant accuracy gains, particularly concerning sequences of three flips.
Model Size and Dataset Size Trade-offs
The study highlights the trade-offs between model size and dataset size. Smaller models, like T5 base, achieved comparable performance to much larger models when trained on CoT-annotated datasets. Moreover, only a fraction of the full dataset was necessary to achieve substantial improvements in performance, suggesting enhanced data efficiency.
Replication with Alternative Teacher Models
The robustness of the methodology was validated using different teacher models. When finetuned with outputs generated by GPT-3 175B, smaller models continued to exhibit improved performance, although nuances in the improvements varied across datasets. This flexibility underscores the adaptability of the approach regardless of the teacher model employed.
Conclusion
The research presents a compelling case for transferring reasoning capabilities from LLMs to smaller models via CoT knowledge distillation. By generating high-quality CoT data and fine-tuning smaller LMs, significant improvements in task accuracy were obtained across various reasoning benchmarks. The study opens up opportunities for further exploration into multi-task settings and the development of novel training data through LLMs.

