- The paper reveals that overestimated self-assessment due to the Dunning-Kruger effect causes under-reliance on AI, leading to reduced decision accuracy.
- The paper shows that a tutorial intervention effectively recalibrates self-assessment for overestimators, though it may trigger algorithm aversion in underestimators.
- The paper finds that logic units-based explanations did not significantly boost calibration or trust, highlighting the need for more robust XAI methods.
The Impact of the Dunning-Kruger Effect on Human Reliance in AI-Assisted Decision Making
Introduction
This paper investigates the influence of the Dunning-Kruger Effect (DKE)—a metacognitive bias where individuals with low competence overestimate their abilities—on human reliance in AI-assisted decision making. The authors conduct a controlled empirical study (N=249) using logical reasoning tasks to quantify how miscalibrated self-assessment affects appropriate reliance on AI systems. The study further evaluates the efficacy of a tutorial intervention and logic units-based explanations in mitigating the negative impact of DKE and facilitating optimal human-AI collaboration.
Experimental Design and Methodology
The study employs a two-stage decision-making protocol. Participants first answer logical reasoning questions unaided, then are presented with AI advice (with or without explanations) and can revise their decisions. The logical reasoning tasks are sourced from the Reclor dataset, chosen for their high difficulty and suitability for eliciting DKE.

Figure 1: An example of a logical reasoning task used to obtain an initial human decision in the two-stage decision making process.
The experiment uses a 2×2 factorial design: tutorial intervention (present/absent) and logic units-based explanations (present/absent). The tutorial intervention provides performance feedback and contrastive explanations, aiming to recalibrate self-assessment by revealing both correct answers and the rationale for rejecting incorrect choices.


Figure 2: Screenshots of the task interface, showing logic units-based explanations and the rationale for correct answers versus users' final choices.
Logic units-based explanations are generated using LogiFormer, a graph transformer network that highlights the most influential text spans in the context and options, based on self-attention scores. This approach is intended to increase the interpretability of AI advice in complex reasoning tasks.
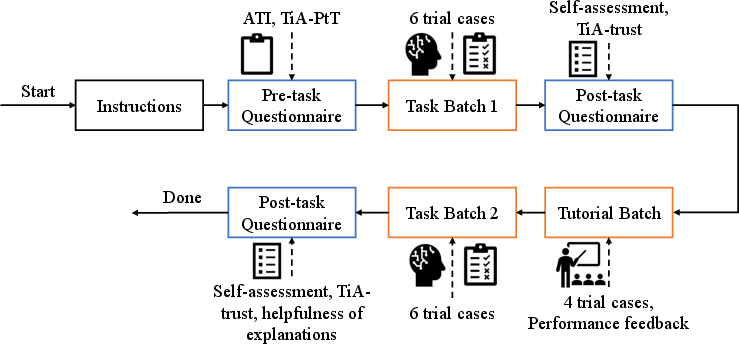
Figure 3: Illustration of the procedure participants followed within the study, detailing the flow of questionnaires, tasks, and interventions.
Key Findings
Dunning-Kruger Effect and Reliance
The analysis reveals that participants who overestimate their performance (indicative of DKE) exhibit significant under-reliance on AI systems, resulting in suboptimal team performance. Specifically, these individuals are less likely to switch to correct AI advice when their initial answer is incorrect, leading to lower accuracy and appropriate reliance metrics.
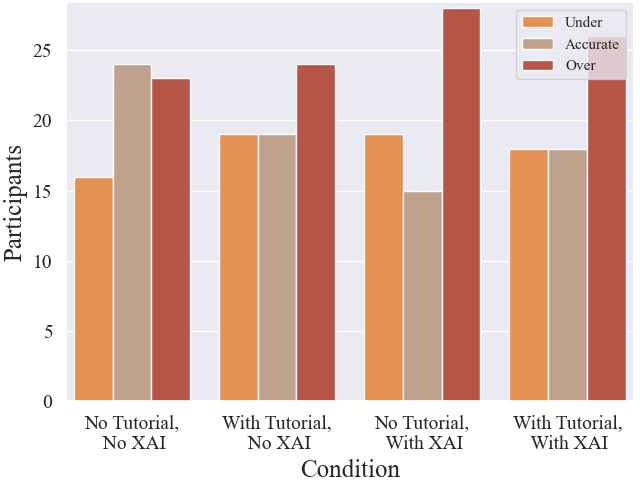
Figure 4: Distribution of participants with underestimated, accurate, and overestimated self-assessment across experimental conditions.
Participants with accurate or underestimated self-assessment demonstrate higher appropriate reliance and overall accuracy, suggesting that self-awareness of competence is critical for effective human-AI collaboration.
Tutorial Intervention
The tutorial intervention is highly effective in calibrating self-assessment for both overestimators and underestimators. For overestimators, calibration leads to increased appropriate reliance and improved performance. However, for underestimators, the intervention can paradoxically decrease appropriate reliance and performance, potentially due to increased algorithm aversion after exposure to AI fallibility.
Logic Units-Based Explanations
Logic units-based explanations do not significantly improve calibration of self-assessment or appropriate reliance. Most participants rate these explanations as only slightly helpful, indicating that current XAI methods may not sufficiently address the interpretability needs in logical reasoning tasks.
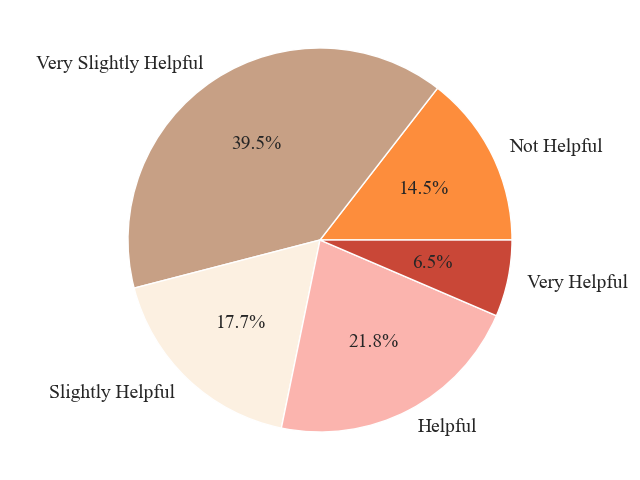
Figure 5: Distribution of participants with perceived helpfulness of logic units-based explanations.
Trust and Propensity to Trust
The tutorial intervention does not significantly affect subjective trust in AI systems. Instead, users' general propensity to trust is the primary predictor of their trust in automation, independent of their self-assessment calibration or exposure to explanations.
Theoretical and Practical Implications
The findings demonstrate that DKE is a substantial barrier to appropriate reliance on AI systems. Overestimation of competence leads to under-reliance, while interventions that recalibrate self-assessment can partially mitigate this effect. However, interventions must be carefully designed: calibration for underestimators may induce algorithm aversion, reducing reliance even when AI advice is superior.
The limited efficacy of logic units-based explanations suggests that further research is needed to develop XAI methods that fulfill the desiderata of promoting understanding, uncertainty recognition, and trust calibration. Contrastive explanations or natural language rationales may offer more promise in this regard.
The complex interplay between self-assessment, reliance, and trust underscores the need for personalized, context-aware interventions in human-AI teaming. Accurate self-assessment does not guarantee optimal reliance, and interventions must balance revealing both user and AI strengths and weaknesses.
Limitations and Future Directions
The study is constrained to logical reasoning tasks with lay participants, which may limit generalizability to other domains or expert populations. Task selection and perceived difficulty may introduce biases. The reliance on self-reported measures and the absence of explicit feedback on explanation comprehension are additional limitations.
Future research should explore more nuanced tutorial designs that simultaneously address over- and under-reliance, incorporate richer forms of explanation, and investigate the role of domain expertise. Longitudinal studies could assess the durability of calibration effects and the evolution of trust and reliance over time.
Conclusion
This work provides quantitative evidence that the Dunning-Kruger Effect impedes appropriate reliance on AI systems in collaborative decision making. Tutorial interventions can recalibrate self-assessment and partially improve reliance, but may have adverse effects for certain user groups. Logic units-based explanations, as currently implemented, do not significantly enhance reliance or calibration. The results highlight the need for more sophisticated, personalized interventions and XAI methods to facilitate optimal human-AI teaming. These insights have direct implications for the design of human-centered AI systems and the development of robust methodologies for mitigating cognitive biases in human-AI interaction.