- The paper introduces an AI-driven reinforcement learning framework that efficiently escapes local optima, achieving up to 69.3% area reduction compared to classical methods.
- It integrates Q-learning and A3C algorithms with advanced techniques like GCN-based node embeddings to select optimized AIG cuts.
- Experimental results on benchmark and industrial circuits demonstrate practical improvements in cell area, node/edge counts, and power consumption.
AISYN: AI-driven Reinforcement Learning-Based Logic Synthesis Framework
Introduction
The paper "AISYN: AI-driven Reinforcement Learning-Based Logic Synthesis Framework" (2302.06415) addresses significant challenges in the domain of logic synthesis for digital chip design, particularly focusing on NP-Complete problems like delay and area minimization. Traditional approaches often rely on heuristic, greedy algorithms that are prone to getting trapped in local minima, thus limiting their effectiveness in optimizing the quality of results (QoR) such as area, delay, and power. This paper posits that reinforcement learning (RL) methods offer a promising alternative by exiting local minima, thereby enhancing the QoR. Experimental results demonstrate substantial improvements, notably a reduction in total cell area by up to 69.3% using an RL-based rewriting algorithm compared to classical methods.
Methodology
AIG Rewriting Framework
The paper introduces a modified cut-based AIG-rewriting function, which replaces sub-graphs in an AIG with optimized variants to reduce node count while preserving circuit functionality. In this approach, the limitations of classical rewriting functions—selecting cuts based solely on local gain—are overcome by allowing any feasible cut to be chosen, thereby facilitating exploration via reinforcement learning frameworks.
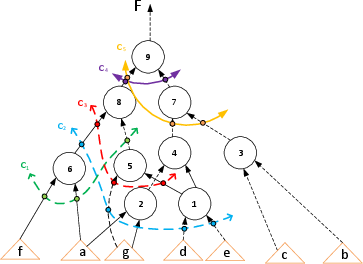
Figure 1: A test AIG example listing 4-feasible cuts for specific nodes, showcasing the diversity in action selection.
Q-learning Algorithm
The paper leverages Q-learning, an off-policy RL algorithm, which optimizes long-term rewards through iterative exploration and exploitation processes. A noteworthy innovation is the use of an approximate model where nodes represent states, mitigating the large state space challenge. This model allows the Q-agent to traverse the AIG in topological order, selecting cuts at each node based on learned values stored in a Q-matrix. The agent receives rewards based on local improvements and the optimization level achieved after synthesis.
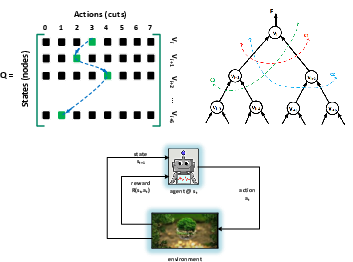
Figure 2: Q-learning-based rewriting algorithm demonstrating the state-action pair management via a Q-matrix for an example circuit.
A3C-based Reinforcement Learning
The paper further enhances its methodology by employing the Asynchronous Advantage Actor-Critic (A3C) algorithm. This approach utilizes multi-agent learning and convolutional neural networks to predict actions, effectively integrating representation learning techniques with deep neural networks. Node embeddings are generated using algorithms like GCN and node2vec, facilitating efficient training and inference.
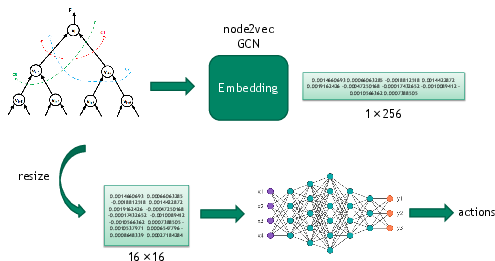
Figure 3: The A3C-drw framework illustrates embedding generation and action prediction in synthesizing input circuits.
Experimental Results
Comprehensive experiments validate the efficacy of AISYN, showcasing significant improvements in multiple metrics across diverse benchmark circuits. For instance, a decrease in total cell area by averages of 21.6% using Q-drw and 20.9% using A3C-drw compared to traditional methods marks particularly strong results. Additionally, the framework achieves notable reductions in node and edge counts, affirming its broader applicability and capacity to enhance logic synthesis beyond classical techniques.
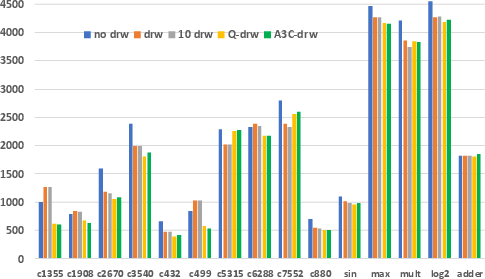
Figure 4: Total edge count post synthesis across different methodologies depicting reduction achieved via AISYN.
Moreover, the paper demonstrates the practical implications of its framework on industrial circuits, achieving around 1% reduction in total power consumption when optimized with AISYN, affirming the paper's contribution to real-world digital design applications.
Conclusion
AISYN represents a significant advancement in logic synthesis, demonstrating how AI techniques, particularly reinforcement learning, can be harnessed to overcome the limitations of traditional methods. By innovatively integrating Q-learning and A3C algorithms into the logic synthesis workflow, significant QoR improvements are achievable, underscoring the potential of AI-driven strategies in NP-Complete domains. The paper's findings not only inform future research directions in automated chip design but also provide a robust framework for practical enhancements in electronic design automation tools.