- The paper introduces an innovative AI-CL method combining convolutional adapters and frequency-time factorized attention to efficiently mitigate catastrophic forgetting in audio classifiers.
- The method reduces trainable parameters to under 5% of full fine-tuning while maintaining comparable performance on benchmarks like ESC-50 and SpeechCommandsV2.
- Frequency-Time factorized Attention alleviates the quadratic complexity of self-attention, enabling scalable processing of long-duration audio spectrograms.
This paper introduces a novel approach to continual learning for audio classifiers by proposing an efficient adaptation to Audio Spectrogram Transformers (AST). The approach aims to address parameter and computational inefficiencies through the introduction of Adapter Incremental Continual Learning (AI-CL) with Convolutional Adapters and novel Frequency-Time factorized Attention (FTA).
Introduction
Continual learning within the scope of audio classification poses unique challenges, primarily due to the risk of catastrophic forgetting. This phenomenon occurs when a neural network, being fine-tuned for a new task, loses its ability to perform earlier tasks. The paper proposes a Task Incremental Continual Learning (TI-CL) approach by employing AST, which has achieved superior results in audio classification benchmarks. However, AST's complexity leads to parameter inefficiency when fully fine-tuned for sequential tasks and computational inefficiency due to its self-attention mechanism.
To overcome these issues, a Parameter Efficient Transfer (PET) method is explored through Convolutional Adapters, enabling significant reduction in trainable parameters. The paper further introduces Frequency-Time factorized Attention to address the computational load associated with the transformer’s self-attention mechanism.

Figure 1: Adapter Incremental Continual Learning of Audio Spectrogram Transformers.
Continual Learning and Adaptation
The paper presents an exhaustive evaluation of various PET methods on AST through experiments on datasets like ESC-50 and SpeechCommandsV2. It particularly evaluates linear layers, LayerNorm tuning, BitFit, AdaptFormer, Prompt Tuning, LoRA, and ConvPass techniques. The study found that ConvPass yielded comparable performance to full fine-tuning on extensive datasets like SpeechCommandsV2 and even exceeded its performance on smaller datasets like ESC-50, all while utilizing less than 5% of the trainable parameters. These findings highlight the effectiveness of convolutional adapters in achieving parameter efficiency.
Frequency-Time Factorized Attention
The traditional self-attention mechanism in transformers exhibits quadratic computational complexity, which can be prohibitive when processing extensive spectrograms derived from lengthy audio. The paper's proposed Frequency-Time factorized Attention (FTA) mitigates this by factorizing attention, allowing tokens to attend separately to frequency and temporal tokens. This orthogonal factoring exploits the intrinsic structure of spectrograms, significantly reducing complexity.
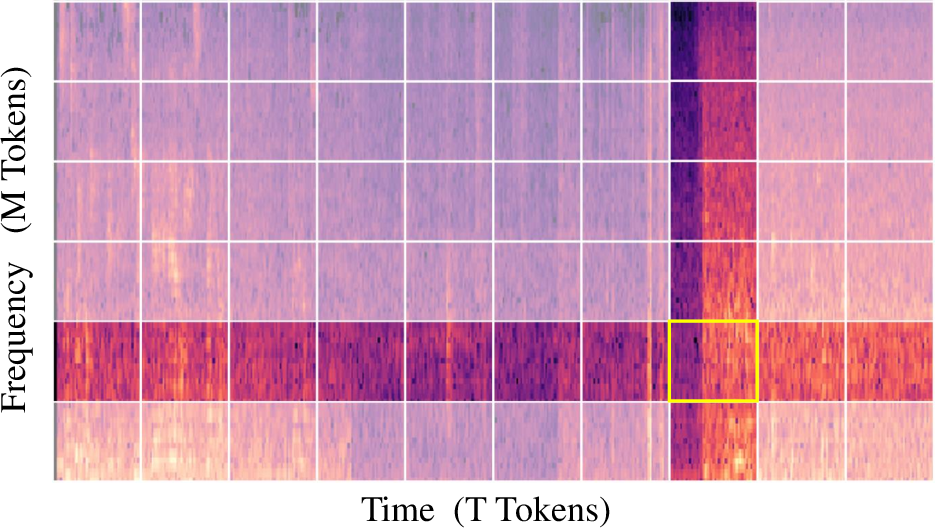
Figure 2: Frequency-Time factorized Attention for a (yellow) token along the frequency and time axis.
Methodology and Results
The AI-CL approach is adeptly structured to balance the added complexity of continual learning tasks with minimized trainable parameter allocations. Particularly, each new task introduces a Convolutional Adapter, while the model backbone remains shared and frozen, ensuring minimal growth in model size. This strategy effectively prevents catastrophic forgetting, as shown in the contextual examples and experiments run on commonly used benchmarks for audio classification such as ESC-50 and SpeechCommandsV2.
The paper subsequently details the implementation of FTA, revealing its efficacy in maintaining accuracy akin to Global Self-Attention (GSA) but at reduced computational costs. This is especially advantageous in scenarios involving long-duration audios, exemplifying substantial efficiency improvements.
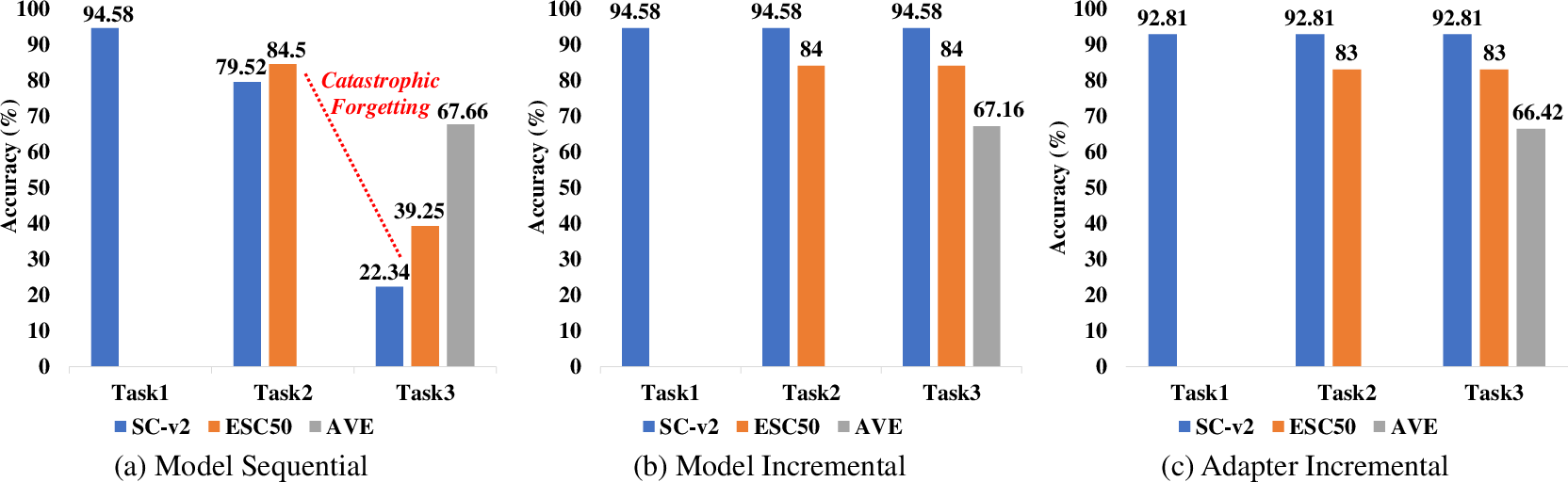
Figure 3: Performance of the AST model in TI-CL setup for three training modes.
Conclusion
The "Adapter Incremental Continual Learning of Efficient Audio Spectrogram Transformers" paper significantly contributes to the field by proposing practical methodologies to align parameter and compute efficiencies with the expanding horizons of continual learning. It systematically constructs a framework that elegantly integrates Convolutional Adapters with a novel attention mechanism to seamlessly handle the intricacies of sequential audio tasks. The benchmarks presented reaffirm the robust performance and adaptability of AST within the proposed AI-CL framework, suggesting promising trajectories for future developments in the implementation of scalable audio classification systems.