- The paper introduces SVDiff, which fine-tunes text-to-image diffusion models by optimizing singular values for efficient parameter reduction.
- It employs Singular Value Decomposition and a Cut-Mix-Unmix strategy to maintain subject identity during multi-subject generation.
- Experimental results show SVDiff achieves roughly 2,200 times more parameter efficiency than conventional methods while sustaining high performance.
SVDiff: Compact Parameter Space for Diffusion Fine-Tuning (2303.11305)
The paper "SVDiff: Compact Parameter Space for Diffusion Fine-Tuning" explores an innovative approach to enhance the efficiency and effectiveness of text-to-image diffusion models by fine-tuning within a compact parameter space. The study introduces a method that could significantly impact real-world applications in text-to-image generation, especially in scenarios demanding model personalization.
Introduction to the Problem
Text-to-image diffusion models have achieved substantial success, yet they face challenges in handling multiple personalized subjects and avoiding overfitting due to their extensive parameter space. The paper addresses these issues by proposing a novel fine-tuning approach that leverages Singular Value Decomposition (SVD) to optimize singular values of the weight matrices, drastically reducing the parameter count while retaining performance.
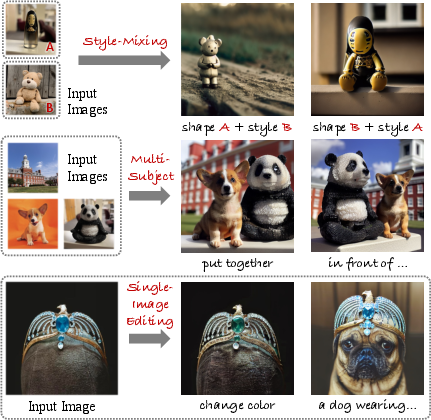
Figure 1: Applications of SVDiff showing its capabilities in style-mixing, multi-subject generation, and single-image editing.
Methodology: Singular Value Decomposition
The SVDiff method capitalizes on performing SVD on the model's weight matrices to achieve a more compact parameter space. This is done by reshaping convolutional weights into 2D matrices and updating only their singular values, termed "spectral shifts." This approach is inspired by techniques in GANs that showed promising results by constraining the trainable parameter space.
In addition, the paper introduces a Cut-Mix-Unmix data-augmentation strategy for multi-subject generation tasks. This technique creatively combines image-prompt pairs to facilitate learning diverse personalized concepts without interference, thus preventing style mixing when generating complex scenes.
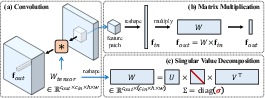
Figure 2: Performing SVD on weight matrices, illustrating the decomposition into matrices from which only singular values are fine-tuned.
Experimentation and Results
The SVDiff method demonstrates compelling results across several tasks, including single-subject and multi-subject generation and single-image editing. The spectral shifts result in models that are approximately 2,200 times more parameter-efficient than methods like DreamBooth while maintaining, if not improving, performance levels.

Figure 3: Results for multi-subject generation showing the effectiveness of the Cut-Mix-Unmix augmentation in maintaining subject distinctions.
A key aspect of the experiments is the comparison with full model fine-tuning, where SVDiff typically maintains subject identity with fewer parameters. Such efficiency is crucial in practical deployments where computational resources and storage are constrained.
Implications and Future Directions
The paper's contributions lie in providing a robust framework for fine-tuning diffusion models efficiently, offering potential for broader application in customized image synthesis and editing. By markedly reducing model size without compromising performance, SVDiff can make text-to-image models more accessible and practical in various domains.
Future work could explore integrating SVDiff with other adaptation techniques such as low-rank adaptation (LoRA) or developing rapid personalization methods that do not require extensive per-image fine-tuning. Investigating the integration of SVDiff with emerging attention-based methods could further enhance its applicability.
Conclusion
SVDiff showcases a relevant advancement in fine-tuning text-to-image diffusion models, significantly reducing the parameter space while preserving model efficacy. Its compactness and capability to manage multi-subject scenarios make it a practical contribution to the generative modeling domain. Such innovations pave the way for more efficient image synthesis models that can adapt to personalized imaging tasks without prohibitive computational overhead.