- The paper introduces a novel contrastive pretraining framework that directly aligns 3D point clouds with open-vocabulary language and images without human curation.
- It employs dual-level semantic and instance alignment, yielding state-of-the-art zero-shot performance across diverse indoor and outdoor datasets.
- The framework demonstrates robust generalization, setting new benchmarks in 3D recognition and paving the way for flexible, open-world perception systems.
CLIP2: Contrastive Language-Image-Point Pretraining from Real-World Point Cloud Data
Introduction
CLIP2 proposes a new paradigm for open-world 3D vision by extending large-scale vision-LLM (VLM) pretraining to the 3D point cloud domain. The paper systematically addresses the longstanding limitations of previous approaches, which either require expensive 3D annotations or rely on indirect 2D projections, sacrificing critical geometric information and generalization capability. CLIP2 introduces a scalable data collection strategy for language-image-point proxies, enabling direct correlation alignment across modalities and robust zero-shot learning.
Framework Overview and Triplet Proxy Generation
CLIP2 comprises two interleaved components: triplet proxy collection and cross-modal contrastive pretraining. The framework leverages unlabelled real-world data, exploiting naturally occurring correspondences among 3D point clouds, 2D images, and open-vocabulary language. The authors establish proxies by applying open-set detectors to extract image proposals, automatically linking them with language descriptors and localizing the corresponding 3D point clusters via precise geometric transformations for both indoor (RGB-D) and outdoor (LiDAR-camera) scenarios.
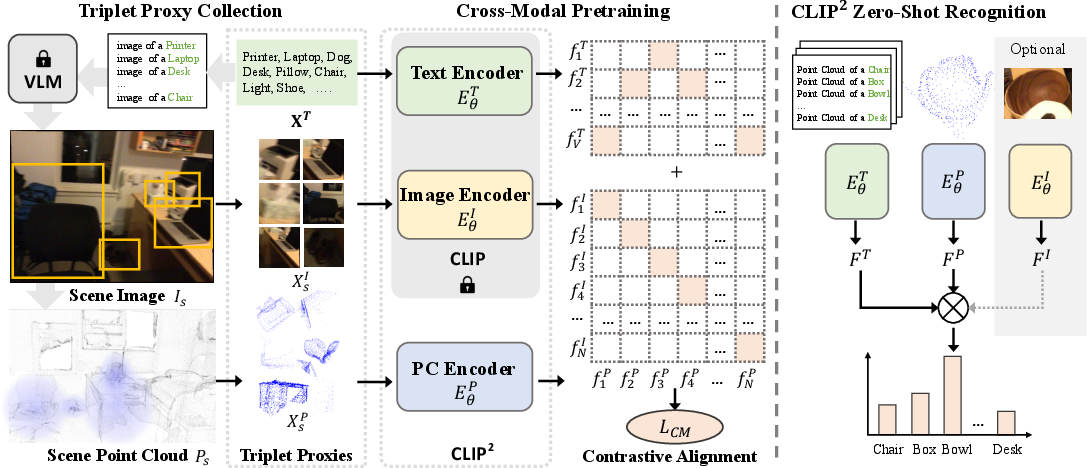
Figure 1: Schematic of the CLIP2 architecture: triplet proxy collection and joint cross-modal contrastive learning.
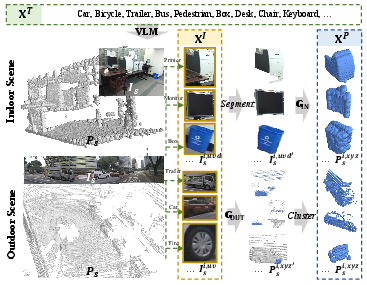
Figure 2: Visualization of the triplet proxy generation pipeline for aligning text, image proposals, and 3D point clouds.
By amassing over 1.6 million language-image-point triplets from large-scale datasets—without human curation—the method provides rich semantic and geometric coverage, circumventing annotation bottlenecks endemic to prior work.
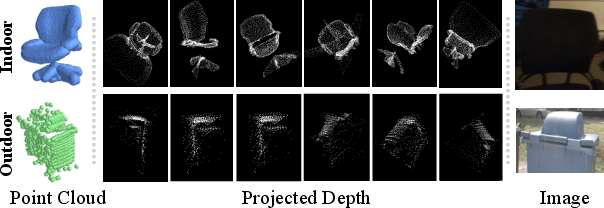
Figure 3: Examples of multi-modal representation for two 3D objects in diverse environments: raw point cloud, projected depth maps, and image patches.
Cross-Modal Contrastive Pretraining
For representation learning, CLIP2 implements a dual-level alignment objective:
- Semantic-level: Point cloud instances are aligned to canonical embeddings of open-vocabulary language queries, facilitating compositional and zero-shot generalization.
- Instance-level: The same point clouds are additionally matched to visual embeddings from corresponding image proposals, further regularizing feature consistency and improving robustness to spatial variation and incomplete or occluded observations.
Instead of compressing 3D data into limited 2D views or depth maps, CLIP2 directly encodes point cloud geometry, maintaining fine-grained structural information crucial for realistic scenarios.
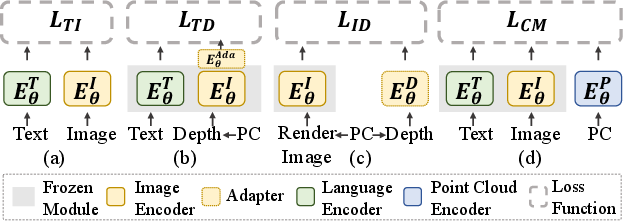
Figure 4: Comparative schematic of pretraining paradigms for 3D recognition: legacy methods (via depth or image alignment) vs. CLIP2’s original point cloud alignment across all three modalities.
Experimental Results
CLIP2 achieves state-of-the-art zero-shot transfer performance across a spectrum of indoor and outdoor datasets, with marked improvements over contemporary baselines:
- SUNRGB-D (Indoor): Top-1 accuracy of 61.3%, a >5% margin over previous bests, and up to 69.6% with modality ensembling.
- ScanNet (Indoor): Top-1 accuracy of 38.5%, outperforming all alternatives, especially in large open-vocabulary settings with significant gains in Top-5 accuracy as the label set expands (e.g., +15.6% over prior for 384 classes).
- nuScenes and ONCE (Outdoor): Average Top-1 accuracy of 37.8% on nuScenes, exceeding depth-based approaches by >20%.
- ScanObjectNN (Few-Shot): Outperforms earlier 3D pretraining paradigms (CrossPoint, PointCLIP, Clip2Point) by a significant margin in both zero-shot and few-shot settings.
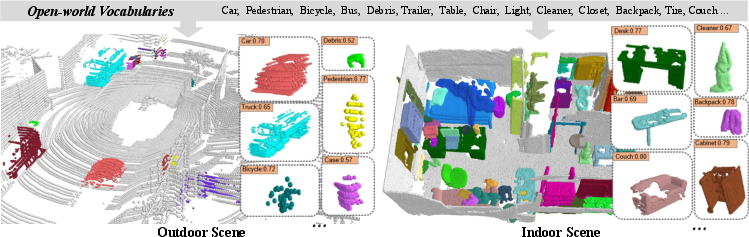
Figure 5: Illustrative open-world recognition examples: point cloud features robustly correlated with textual concepts in both indoor and outdoor environments.
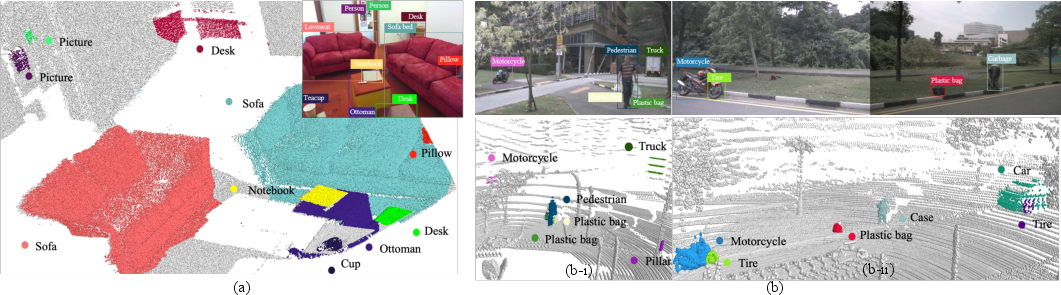
Figure 6: Zero-shot localization and recognition: CLIP2 identifies and classifies open-vocabulary objects in complex 3D scenes with no supervision.
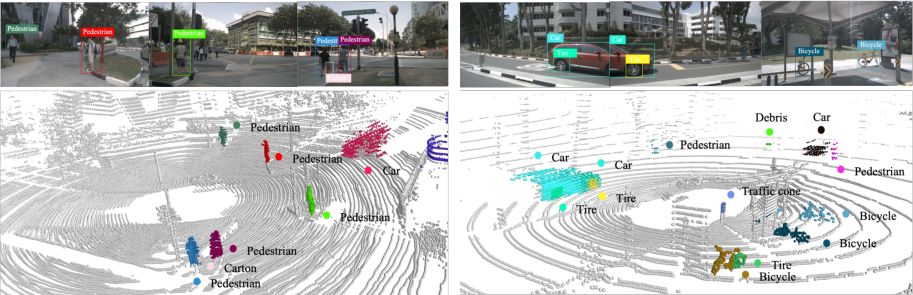
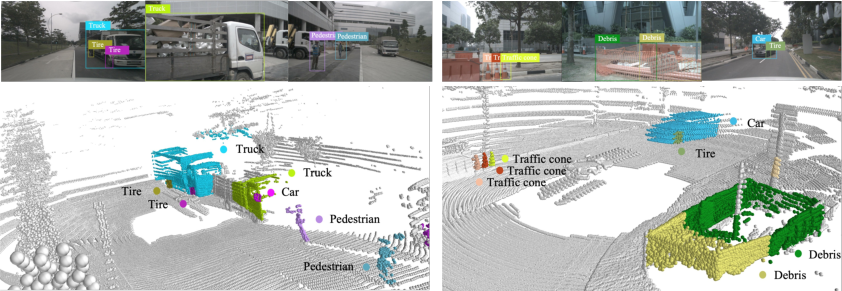
Figure 7: Generalization to out-of-vocabulary categories in nuScenes: localization and recognition of objects beyond ground-truth annotations, such as ‘Tire’ and ‘Debris’.
- Ablation Analysis: Direct alignment in the point cloud space yields consistently superior results over projected depth approaches; joint image-language-point supervision contributes additional gains.
- Ensembling: Incorporating predictions from image and depth modalities with the primary 3D representation further boosts performance, especially when all signals are available.
Qualitative Insights
Extensive visualizations demonstrate CLIP2's robust zero-shot open-world recognition, including saliency analyses revealing fine-grained alignment between text prompts and 3D spatial structure, and detection of novel, long-tail, and previously unlabelled object categories.
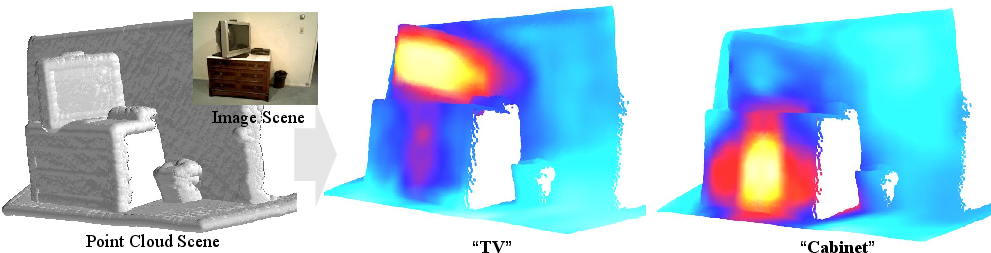
Figure 8: Saliency maps evidencing alignment between text semantics and 3D geometry in point cloud scenes.
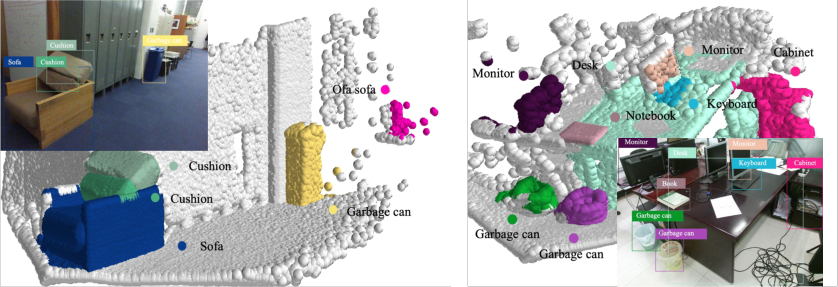

Figure 9: Additional zero-shot recognition visualizations on SunRGB-D, illustrating the framework’s robustness in uncurated, cluttered, real-world environments.
Discussion and Implications
The results substantiate that CLIP2 addresses a critical gap in 3D representation learning: obtaining transferable, annotation-free embeddings tied to open-vocabulary semantics without geometric information loss. This enables:
- Open-world object discovery in safety-critical systems (e.g., autonomous driving, robotics) where taxonomies are inherently incomplete and semantic labels costly or unavailable.
- Zero-shot and few-shot learning in new environments with arbitrary categories, powering rapid adaptation.
- Modality-agnostic fusion: The presented ensembling analysis suggests future frameworks could further integrate signals from all available sensory inputs for improved reliability.
By highlighting the centrality of genuine 3D geometric representation aligned with semantic priors, CLIP2 establishes a foundation for more capable and adaptive 3D perception systems.
Limitations and Future Outlook
The current framework exhibits limited spatial resolution for tight bounding box regression, as localization is based on point clusters rather than explicit box fitting. However, the approach naturally complements and can seed supervised or hybrid 3D detectors for downstream tasks. Scaling proxy generation via further multimodal mining, as well as extending the backbone architectures, offers clear avenues for enhancing performance and applicability.
The work implies a trajectory where future open-world 3D systems will unify cross-sensor, cross-modal data, leveraging Internet-scale language corpora and geometry-aware models to achieve semantic completeness and robust generalization in complex, dynamic environments.
Conclusion
CLIP2 delivers a comprehensive solution for open-world zero-shot 3D recognition, outperforming prior art by directly encoding point cloud data and aligning it with both visual and linguistic representations. With scalable, annotation-free proxy generation and flexible cross-modal objectives, it significantly advances the state of transferable 3D learning and sets the groundwork for universal, open-vocabulary 3D perception.

