- The paper introduces surrogate models to efficiently predict multitask performance and identify negative transfers.
- It employs linear regression on sampled task subsets, achieving high prediction accuracy with an average F1-score of 0.80.
- The method significantly reduces computational overhead and scales linearly, offering practical benefits for weak supervision datasets.
Identification of Negative Transfers in Multitask Learning Using Surrogate Models
This paper introduces a novel approach to tackle the problem of identifying negative transfers in Multitask Learning (MTL). By utilizing surrogate models, the authors propose an efficient procedure to predict and optimize multitask performances, addressing the computational challenges in subset selection of source tasks. The methodology provides significant improvements over existing task affinity measures and optimization methods, particularly for weak supervision datasets. This essay details the paper's methods, theoretical analyses, experimental validations, and the implications for MTL.
Methodology: Surrogate Modeling
The central proposition is the design of surrogate models to approximate MTL performances. This approach involves two key steps:
- Subset Sampling and MTL Evaluation: The methodology begins with the sampling of n random subsets of source tasks from a pool of k total tasks. For each subset Si, an MTL model is trained using the data from Si combined with the target task. The MTL model's loss, f(Si), is then evaluated on a target task dataset.
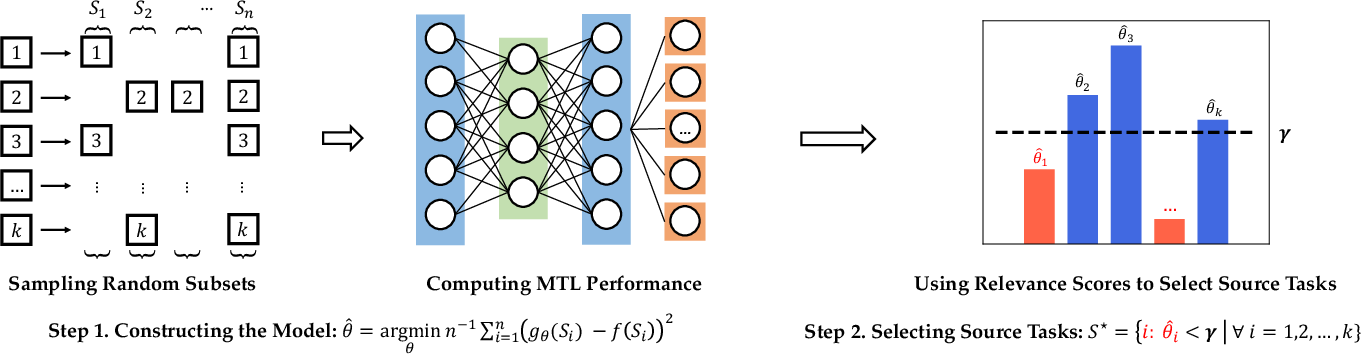
Figure 1: Our approach involves sampling subsets and training MTL models to evaluate and predict performance.
- Linear Regression and Relevance Score Estimation: The second step employs a linear regression model to estimate relevance scores θ. This model effectively predicts the MTL performance on unseen task subsets. Relevance scores guide subset selection for optimal multitask learning via thresholding.
Theoretical Analysis
The authors present rigorous theoretical analysis, ensuring that surrogate models can be fitted accurately with linear complexity relative to the number of source tasks. The key insights include:
- Linear Surrogate Model: The linear model, gθ(S)=∑j∈Sθj, simplifies computational requirements and allows scalable task affinity measurement.
- Sample Complexity: The analysis indicates that linearly many samples (in terms of k) suffice to fit the surrogate model with reliable accuracy. This theoretical foundation is supported by results utilizing Rademacher complexity arguments.
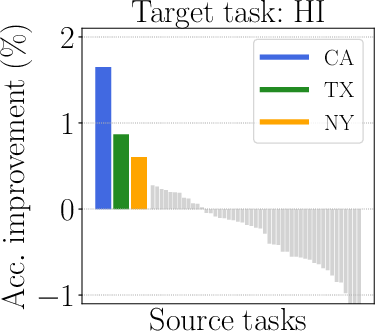
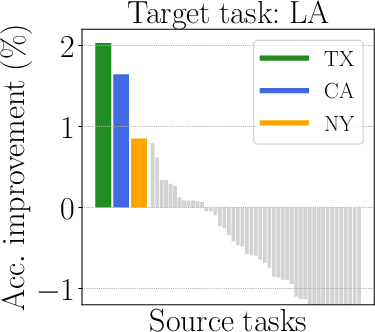
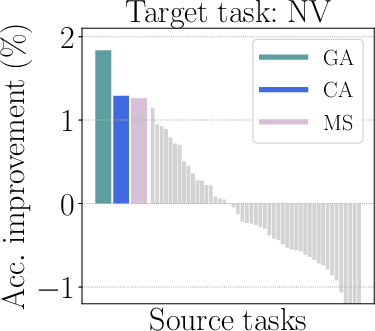
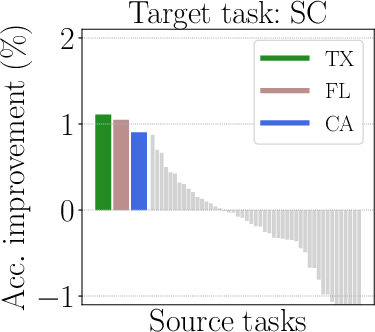
Figure 2: Illustration of mixed outcomes in multitask learning.
Experimental Validation
Extensive experiments validate the approach across diverse settings, including weak supervision datasets, NLP tasks, and multi-group learning scenarios.
Implications and Future Directions
The methodology sets a new standard for efficient and accurate prediction of task-relatedness in MTL, with broad applicability in scenarios where robust, scalable model training is critical. Some implications and potential directions for future work include:
- Wider Applicability: Exploration of surrogate modeling techniques in federated learning and reinforcement learning settings.
- Refinement and Tuning: Further investigation into adaptive sampling techniques could yield even faster training cycles.
- Understanding and Expanding: Extensions to more complex model architectures and tasks would help generalize the findings further.
Conclusion
This paper presents a scalable and efficient solution to identifying negative transfers in multitask learning, demonstrating notable improvements across various benchmarks. Through surrogate models, the proposed method reduces computational overhead while enhancing prediction accuracy. The theoretical and empirical findings solidify the approach as a valuable contribution to MTL research, offering new avenues for optimizing task performance in real-world applications.
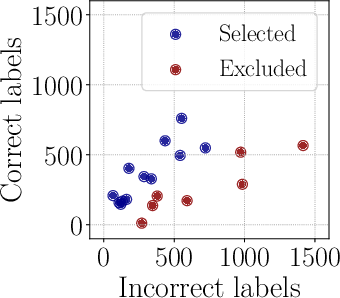
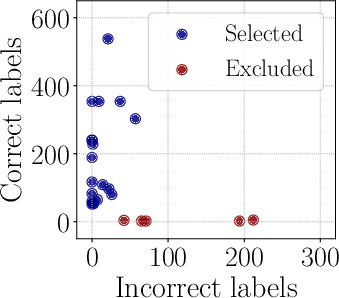
Figure 4: The surrogate models adeptly handle complexities and predict relevant subsets for task optimization.
