- The paper introduces DDP, formulating dense prediction as a conditional denoising diffusion process for tasks like semantic segmentation, depth estimation, and BEV map segmentation.
- It decouples the image encoder from the iterative map decoder to enable efficient dynamic inference and uncertainty quantification with a lightweight architecture.
- Empirical results on datasets like ADE20K, Cityscapes, nuScenes, and KITTI demonstrate state-of-the-art performance and a favorable accuracy-efficiency trade-off.
DDP: Diffusion Model for Dense Visual Prediction
Introduction and Motivation
The paper "DDP: Diffusion Model for Dense Visual Prediction" (2303.17559) introduces a conditional diffusion-based framework, DDP, for dense visual prediction tasks such as semantic segmentation, depth estimation, and BEV map segmentation. The motivation is to leverage the generative capacity and uncertainty quantification of diffusion models while addressing the inefficiencies and architectural rigidity of prior generative approaches in dense prediction. DDP is designed to be architecture-agnostic, efficient, and easily extensible to a wide range of dense prediction tasks.
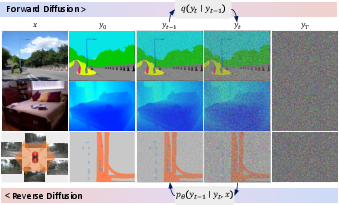
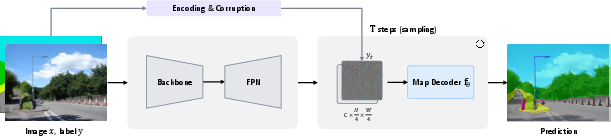
Figure 1: Conditional diffusion pipeline for dense visual predictions. The model iteratively denoises a Gaussian noise map into the target prediction, conditioned on the input image.
Methodology
Conditional Diffusion for Dense Prediction
DDP formulates dense prediction as a conditional denoising diffusion process. The forward process adds Gaussian noise to the ground truth map, while the reverse process, parameterized by a neural network, iteratively denoises the noisy map to recover the prediction, conditioned on the image features. This "noise-to-map" paradigm generalizes across both discrete (segmentation) and continuous (depth) prediction tasks.
Architecture Design
A key architectural innovation is the decoupling of the image encoder and the map decoder:
Training and Inference
- Training: The model is trained to predict the clean map from a noisy version, using task-specific losses (e.g., cross-entropy for segmentation, regression loss for depth). For discrete labels, class embedding is used to map labels into a continuous space, with careful scaling to control SNR.
- Inference: At test time, the model starts from random Gaussian noise and iteratively refines the prediction using the DDIM update rule. The number of diffusion steps can be dynamically adjusted to trade off accuracy and computational cost.
Dynamic Inference and Uncertainty Estimation
DDP supports dynamic inference, allowing the user to select the number of diffusion steps at test time. This enables a flexible trade-off between computational efficiency and prediction quality. Additionally, the stochastic nature of the diffusion process provides a natural mechanism for uncertainty estimation by analyzing the variability across steps.
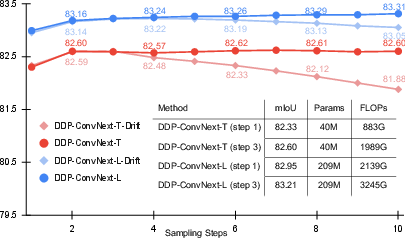
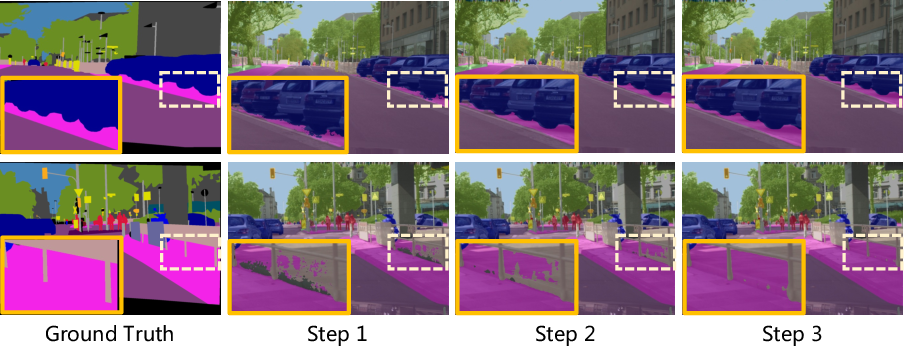

Figure 3: DDP enables dynamic inference (accuracy vs. computation) and provides pixel-wise uncertainty estimates.
Sampling Drift and Self-Aligned Denoising
The paper identifies and addresses the "sampling drift" problem: a distributional mismatch between training (denoising ground truth) and inference (denoising model predictions). To mitigate this, a self-aligned denoising strategy is introduced in the final training iterations, where the model learns to denoise its own predictions, improving stability and performance in later diffusion steps.

Figure 4: Sampling drift arises from the mismatch between training and inference denoising targets.
Empirical Results
Semantic Segmentation
DDP achieves competitive or superior results on ADE20K and Cityscapes, outperforming several discriminative and generative baselines. For example, with Swin-L backbone, DDP attains 53.2 mIoU on ADE20K and 83.21 mIoU on Cityscapes, with the added benefit of dynamic inference and uncertainty quantification.
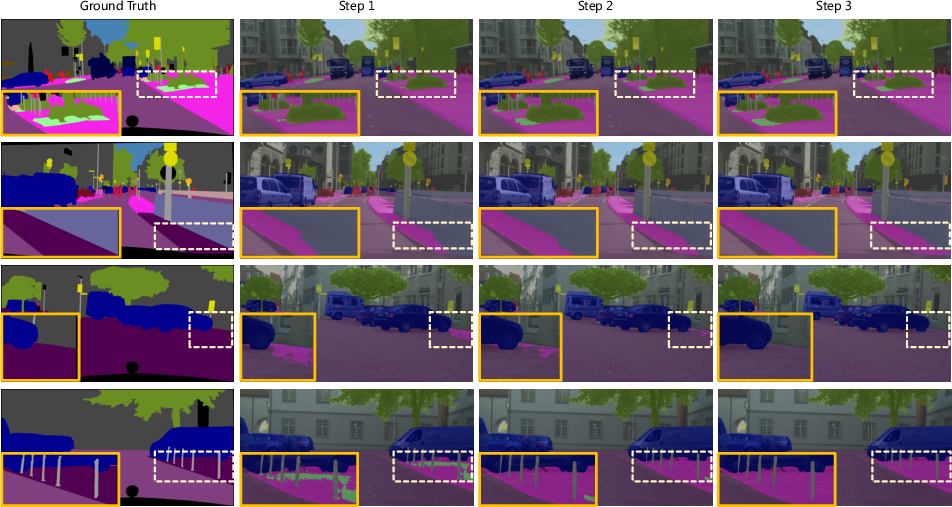
Figure 5: Visualization of multiple inference on Cityscapes val set, showing progressive refinement.
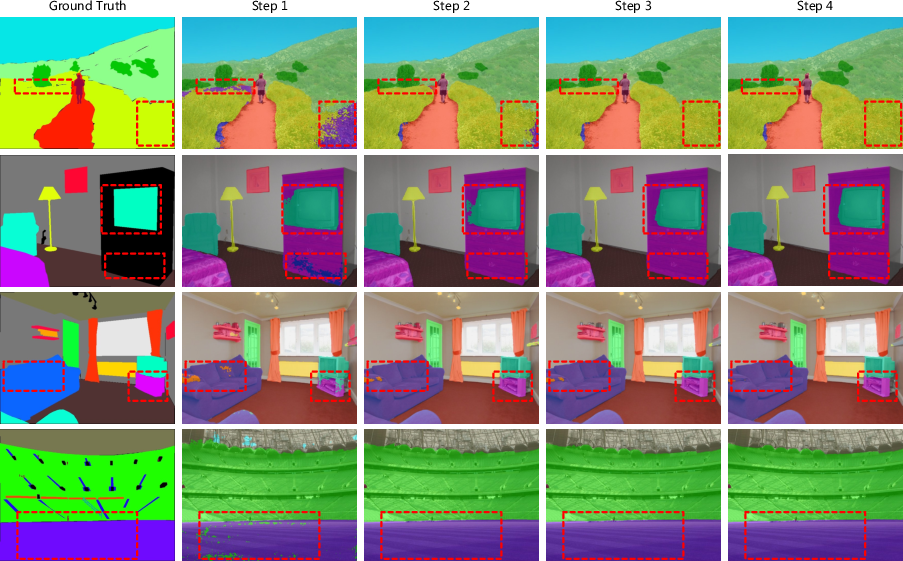
Figure 6: Visualization of multiple inference on ADE20K val set.
BEV Map Segmentation
On nuScenes, DDP sets a new state-of-the-art for BEV map segmentation, achieving 70.6 mIoU in the multi-modal setting, outperforming prior methods such as BEVFusion and X-Align.
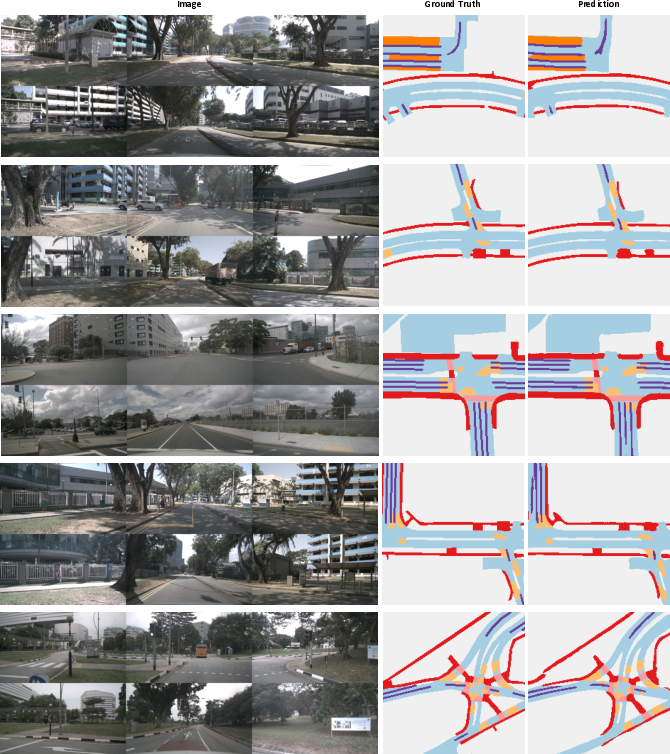
Figure 7: Visualization of predicted BEV map segmentation results on nuScenes val set.
Depth Estimation
DDP demonstrates strong performance on KITTI and NYU-DepthV2, achieving 0.05 REL on KITTI with Swin-L, surpassing both discriminative and diffusion-based baselines (e.g., DepthGen). The model generalizes well to out-of-domain data (e.g., SUN RGB-D).

Figure 8: Visualization of predicted depth estimation results on KITTI val set.

Figure 9: Visualization of predicted depth estimation results on NYU-DepthV2 val set.
Application to Conditional Generation
DDP's segmentation outputs can be used as conditioning inputs for generative models such as ControlNet, improving semantic consistency and visual quality in text-to-image synthesis.

Figure 10: Control Stable Diffusion with Semantic Map, using DDP segmentation as condition input.
Ablation and Analysis
The paper provides extensive ablations on label encoding, scaling factor, noise schedule, and decoder depth. Class embedding with a small scaling factor and cosine noise schedule yields the best results. The decoder is lightweight, and DDP achieves favorable accuracy-efficiency trade-offs compared to discriminative baselines.
Implications and Future Directions
DDP demonstrates that diffusion models, when properly adapted, can serve as general-purpose, high-performing frameworks for dense visual prediction. The decoupled architecture and dynamic inference capabilities make DDP suitable for deployment in resource-constrained or real-time settings. The natural uncertainty estimation is valuable for safety-critical applications.
Potential future directions include:
- Further architectural specialization for specific dense prediction tasks to close the gap with highly optimized discriminative models.
- Exploration of DDP in additional domains (e.g., medical imaging, remote sensing).
- Integration with large-scale foundation models for unified perception-generation pipelines.
- Investigation of more advanced sampling and training strategies to further reduce computational overhead.
Conclusion
DDP provides a principled, efficient, and extensible diffusion-based framework for dense visual prediction, achieving state-of-the-art or highly competitive results across multiple tasks and datasets. Its architectural decoupling, dynamic inference, and uncertainty quantification set a new baseline for generative approaches in dense prediction. While multi-step inference introduces additional computational cost, the flexibility and generality of DDP make it a compelling direction for future research in vision and beyond.