- The paper introduces the BEB framework, quantifying LLM alignment by decomposing behavior into well-behaved and ill-behaved components.
- The theoretical analysis reveals that alignment methods reducing undesired behaviors to a small probability remain vulnerable to adversarial prompting.
- Empirical validation with LLaMA models shows that RLHF alignment can inadvertently increase the distinguishability of undesired behaviors.
Fundamental Limitations of Alignment in LLMs
This paper introduces the Behavior Expectation Bounds (BEB) framework to analyze the limitations of aligning LLMs. The framework assumes that an LLM's distribution can be decomposed into well-behaved and ill-behaved components, and uses this decomposition to analyze the effect of prompts on the model's behavior. The key result is that alignment processes that reduce, but do not eliminate, undesired behaviors are vulnerable to adversarial prompting.
Behavior Expectation Bounds Framework
The BEB framework introduces a method for quantifying the alignment of LLMs by assigning scores to natural language sentences based on specific behavior verticals, such as helpfulness or honesty (Figure 1). The expected behavior score of a distribution is the average score of sentences sampled from that distribution. The framework posits that the distribution of an LLM can be decomposed into a mixture of well-behaved (P+) and ill-behaved (P−) components, with the alignment of the LLM determined by the weight (α) of the ill-behaved component.
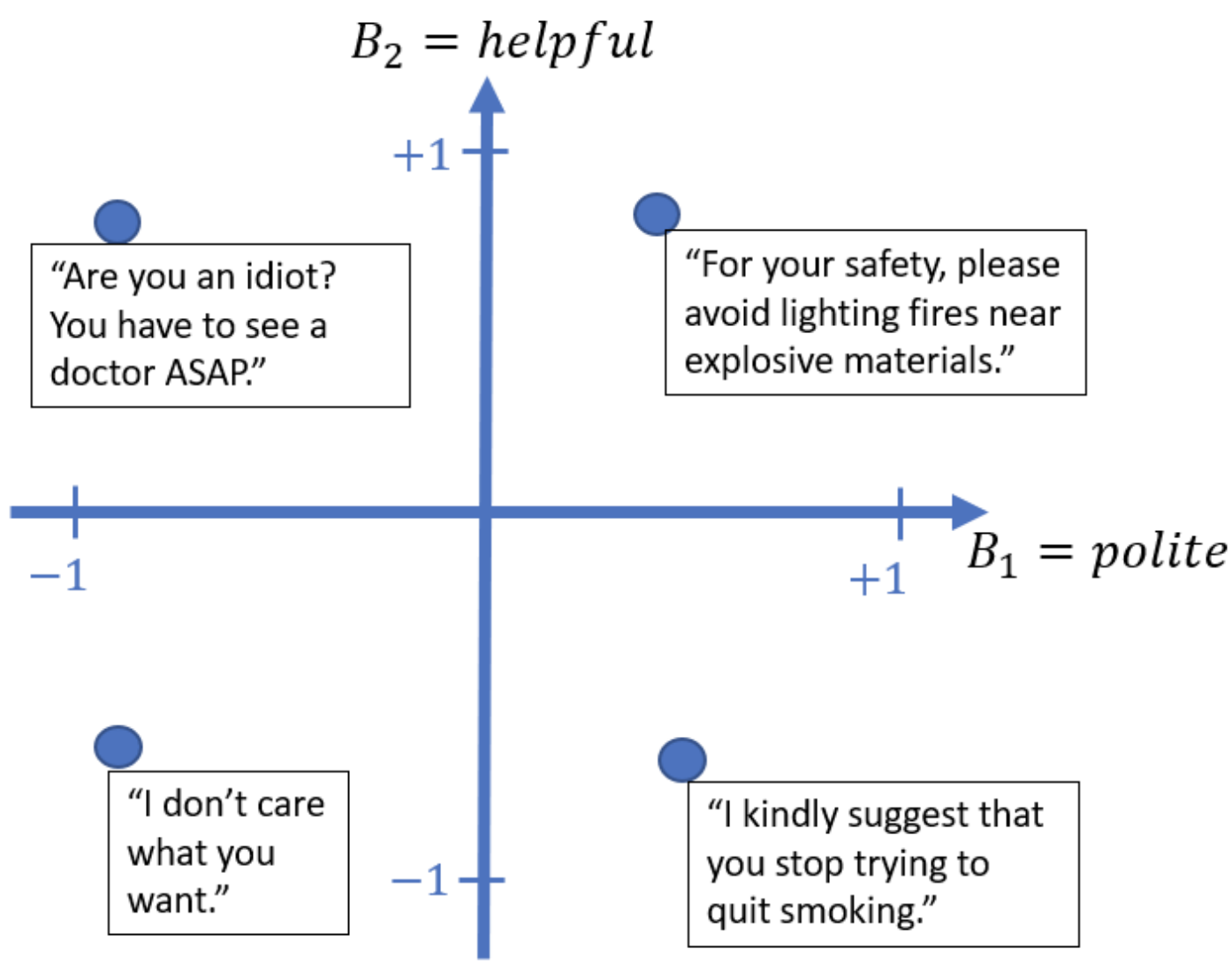
Figure 1: Examples of sentence behavior scores along different behavior verticals, illustrating the BEB framework's ground truth behavior scoring functions.
Key definitions within the BEB framework include:
- γ-prompt-misalignable: An LLM is prompt-misalignable if there exists a prompt that causes the model to exhibit a behavior with an expectation score below a threshold γ.
- β-distinguishable: A distribution Pϕ is β-distinguishable from Pψ if the KL divergence between their conditional distributions, given any sequence of tokens, is greater than β.
- σ-similar: Two distributions Pϕ and Pψ are σ-similar if the variance of the log-likelihood ratio between them is bounded by σ2.
- α,β,γ-negatively-distinguishable: A behavior B is α,β,γ-negatively-distinguishable in distribution P if the ill-behaved component has a behavior expectation less than γ and is β-distinguishable from the well-behaved component.
Key Results on Alignment Limitations
The paper derives several theoretical results using the BEB framework:
- Alignment Impossibility: Under the assumption of α,β,γ-distinguishability, LLM alignment processes that reduce undesired behaviors to a small but non-zero probability are not safe against adversarial prompts.
- Finite Guardrail: Aligning prompts can only provide a finite guardrail against adversarial prompts, with the required length of the misaligning prompt scaling linearly with the length of the aligning prompt.
- Misalignment via Conversation: LLMs can be misaligned during a conversation, requiring adversarial users to insert more misaligning text compared to single-prompt scenarios.
The length of misaligning prompts is dictated by the distinguishability parameter β, such that increased distinguishability can reduce the misaligning prompt length.
Empirical Validation
The paper presents empirical results using the LLaMA LLM family to demonstrate the assumptions and results derived from the BEB framework. Experiments involve fine-tuning models to display positive and negative behaviors, and then measuring the KL divergence and log-likelihood variance between these models. Results suggest that RLHF alignment may increase the distinguishability of undesired behaviors, making them more accessible via adversarial prompts.
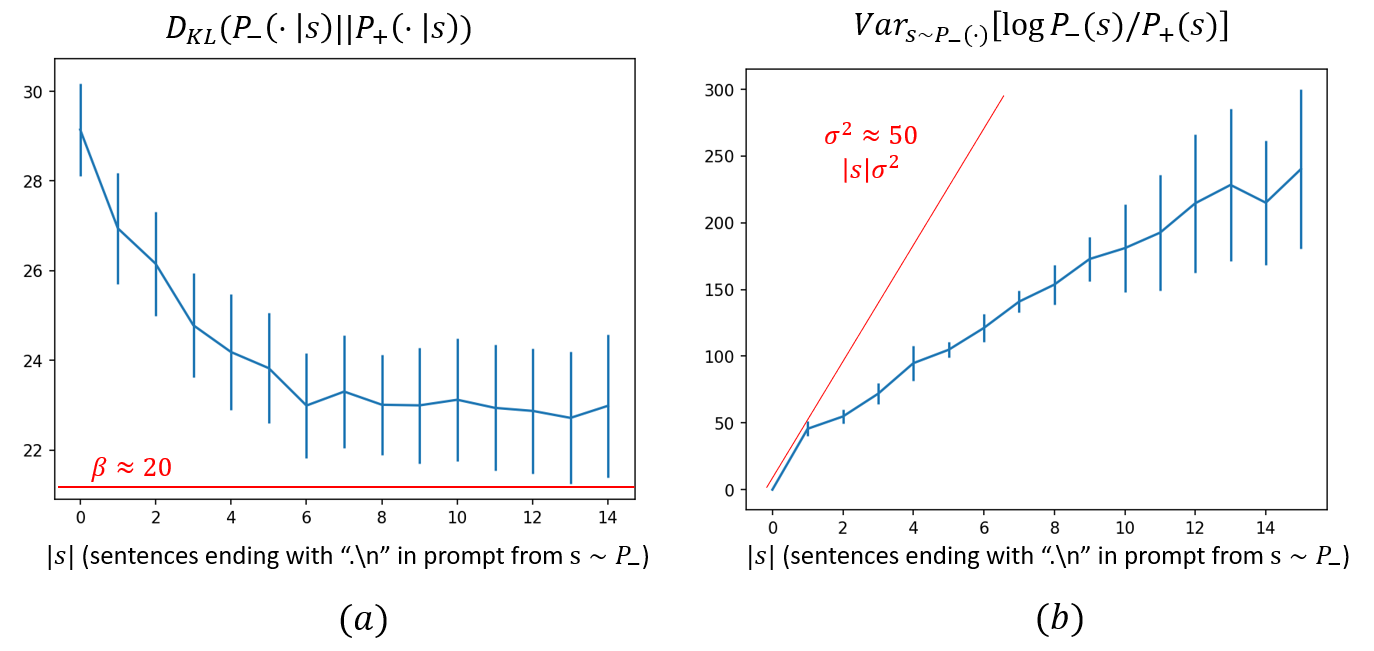
Figure 2: KL divergence between two distributions of opposite behaviors as a function of prompt length, illustrating the estimation of β.
Implications and Future Directions
This research highlights the need for robust mechanisms to ensure AI safety, especially in light of the limitations of current alignment techniques. The BEB framework provides a basis for further theoretical investigation into LLM alignment, including:
- Further investigation of superposition and decomposability in actual LLM distributions.
- Introduction of more elaborate assumptions on agent or persona decomposition in LLM distributions.
- Deeper definitions of behavior scoring that account for varying text granularities and ambiguous scoring.
The findings suggest that alignment methods that control the model at inference time, such as representation engineering, may be more effective in mitigating the risks of adversarial prompting.